Mapreduce实例——MapReduce自定义输出格式
实验步骤
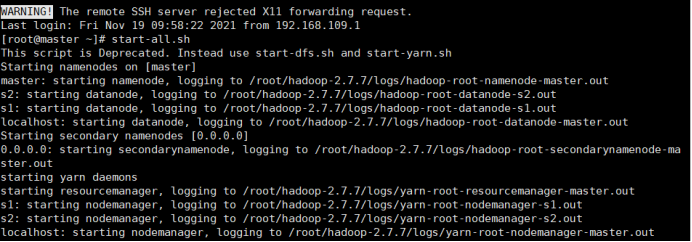
1.开启Hadoop
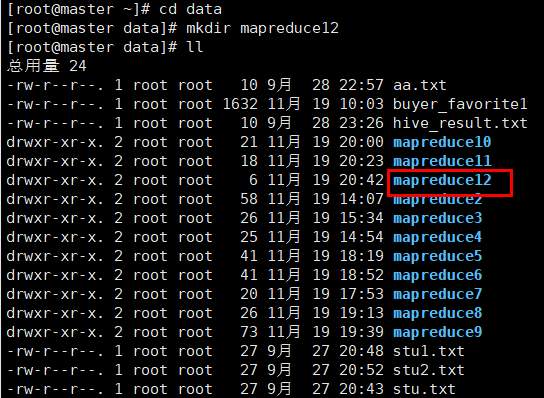
2.新建mapreduce12目录
在Linux本地新建/data/mapreduce12目录
3. 上传文件到linux中
(自行生成文本文件,放到个人指定文件夹下)
cat_group1文件
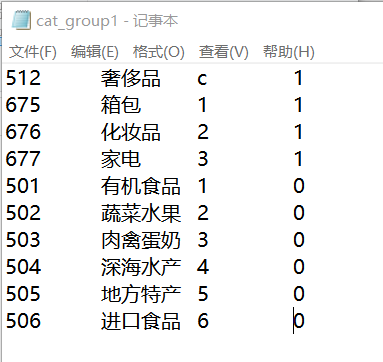
512 奢侈品 c 1
675 箱包 1 1
676 化妆品 2 1
677 家电 3 1
501 有机食品 1 0
502 蔬菜水果 2 0
503 肉禽蛋奶 3 0
504 深海水产 4 0
505 地方特产 5 0
506 进口食品 6 0
4.在HDFS中新建目录
首先在HDFS上新建/mymapreduce12/in目录,然后将Linux本地/data/mapreduce12目录下的cat_group1文件导入到HDFS的/mymapreduce12/in目录中。
hadoop fs -mkdir -p /mymapreduce12/in
hadoop fs -put /root/data/mapreduce12/cat_group1 /mymapreduce12/in
5.新建Java Project项目
新建Java Project项目,项目名为mapreduce。
在mapreduce项目下新建包,包名为mapreduce11。
在mapreduce11包下新建类,类名为MyMultipleOutputFormat、FileOutputMR。
6.添加项目所需依赖的jar包
右键项目,新建一个文件夹,命名为:hadoop2lib,用于存放项目所需的jar包。
将/data/mapreduce2目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce2项目的hadoop2lib目录下。
hadoop2lib为自己从网上下载的,并不是通过实验教程里的命令下载的
选中所有项目hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码
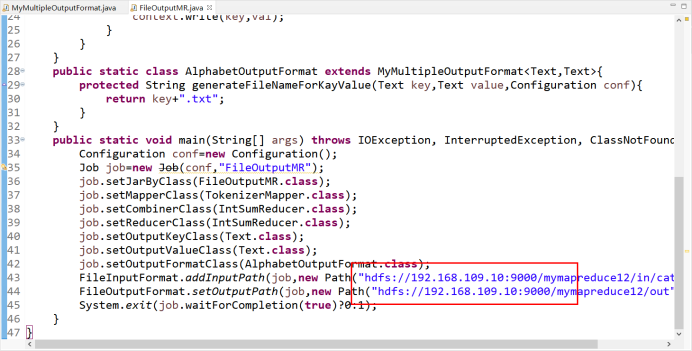
(1)MyMultipleOutputFormat.java
package mapreduce11; import java.io.DataOutputStream; import java.io.IOException; import java.io.PrintWriter; import java.io.UnsupportedEncodingException; import java.util.HashMap; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.compress.CompressionCodec; import org.apache.hadoop.io.compress.GzipCodec; import org.apache.hadoop.mapreduce.OutputCommitter; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.ReflectionUtils; public abstract class MyMultipleOutputFormat <K extends WritableComparable<?>,V extends Writable> extends FileOutputFormat<K,V>{ private MultiRecordWriter writer=null; public RecordWriter<K,V> getRecordWriter(TaskAttemptContext job) throws IOException{ if(writer==null){ writer=new MultiRecordWriter(job,getTaskOutputPath(job)); } return writer; } private Path getTaskOutputPath(TaskAttemptContext conf) throws IOException{ Path workPath=null; OutputCommitter committer=super.getOutputCommitter(conf); if(committer instanceof FileOutputCommitter){ workPath=((FileOutputCommitter) committer).getWorkPath(); }else{ Path outputPath=super.getOutputPath(conf); if(outputPath==null){ throw new IOException("Undefined job output-path"); } workPath=outputPath; } return workPath; } protected abstract String generateFileNameForKayValue(K key,V value,Configuration conf); protected static class LineRecordWriter<K,V> extends RecordWriter<K, V> { private static final String utf8 = "UTF-8"; private static final byte[] newline; private PrintWriter tt; static { try { newline = "\n".getBytes(utf8); } catch (UnsupportedEncodingException uee) { throw new IllegalArgumentException("can't find " + utf8 + " encoding"); } } protected DataOutputStream out; private final byte[] keyValueSeparator; public LineRecordWriter(DataOutputStream out, String keyValueSeparator) { this.out = out; try { this.keyValueSeparator = keyValueSeparator.getBytes(utf8); } catch (UnsupportedEncodingException uee) { throw new IllegalArgumentException("can't find " + utf8 + " encoding"); } } public LineRecordWriter(DataOutputStream out) { this(out, ":"); } private void writeObject(Object o) throws IOException { if (o instanceof Text) { Text to = (Text) o; out.write(to.getBytes(), 0, to.getLength()); } else { out.write(o.toString().getBytes(utf8)); } } public synchronized void write(K key, V value) throws IOException { boolean nullKey = key == null || key instanceof NullWritable; boolean nullValue = value == null || value instanceof NullWritable; if (nullKey && nullValue) {// return; } if (!nullKey) { writeObject(key); } if (!(nullKey || nullValue)) { out.write(keyValueSeparator); } if (!nullValue) { writeObject(value); } out.write(newline); } public synchronized void close(TaskAttemptContext context) throws IOException { out.close(); } } public class MultiRecordWriter extends RecordWriter<K,V>{ private HashMap<String,RecordWriter<K,V> >recordWriters=null; private TaskAttemptContext job=null; private Path workPath=null; public MultiRecordWriter(TaskAttemptContext job,Path workPath){ super(); this.job=job; this.workPath=workPath; recordWriters=new HashMap<String,RecordWriter<K,V>>(); } public void close(TaskAttemptContext context) throws IOException, InterruptedException{ Iterator<RecordWriter<K,V>> values=this.recordWriters.values().iterator(); while(values.hasNext()){ values.next().close(context); } this.recordWriters.clear(); } public void write(K key,V value) throws IOException, InterruptedException{ String baseName=generateFileNameForKayValue(key ,value,job.getConfiguration()); RecordWriter<K,V> rw=this.recordWriters.get(baseName); if(rw==null){ rw=getBaseRecordWriter(job,baseName); this.recordWriters.put(baseName,rw); } rw.write(key, value); } private RecordWriter<K,V> getBaseRecordWriter(TaskAttemptContext job,String baseName)throws IOException,InterruptedException{ Configuration conf=job.getConfiguration(); boolean isCompressed=getCompressOutput(job); String keyValueSeparator= ":"; RecordWriter<K,V> recordWriter=null; if(isCompressed){ Class<?extends CompressionCodec> codecClass=getOutputCompressorClass(job,(Class<?extends CompressionCodec>) GzipCodec.class); CompressionCodec codec=ReflectionUtils.newInstance(codecClass,conf); Path file=new Path(workPath,baseName+codec.getDefaultExtension()); FSDataOutputStream fileOut=file.getFileSystem(conf).create(file,false); recordWriter=new LineRecordWriter<K,V>(new DataOutputStream(codec.createOutputStream(fileOut)),keyValueSeparator); }else{ Path file=new Path(workPath,baseName); FSDataOutputStream fileOut=file.getFileSystem(conf).create(file,false); recordWriter =new LineRecordWriter<K,V>(fileOut,keyValueSeparator); } return recordWriter; } } }
(2)FileOutputMR.java
package mapreduce11; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FileOutputMR { public static class TokenizerMapper extends Mapper<Object,Text,Text,Text>{ private Text val=new Text(); public void map(Object key,Text value,Context context)throws IOException,InterruptedException{ String str[]=value.toString().split("\t"); val.set(str[0]+" "+str[1]+" "+str[2]); context.write(new Text(str[3]), val); } } public static class IntSumReducer extends Reducer<Text,Text,Text,Text>{ public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{ for(Text val:values){ context.write(key,val); } } } public static class AlphabetOutputFormat extends MyMultipleOutputFormat<Text,Text>{ protected String generateFileNameForKayValue(Text key,Text value,Configuration conf){ return key+".txt"; } } public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException{ Configuration conf=new Configuration(); Job job=new Job(conf,"FileOutputMR"); job.setJarByClass(FileOutputMR.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setOutputFormatClass(AlphabetOutputFormat.class); FileInputFormat.addInputPath(job,new Path("hdfs://192.168.109.10:9000/mymapreduce12/in/cat_group1")); FileOutputFormat.setOutputPath(job,new Path("hdfs://192.168.109.10:9000/mymapreduce12/out")); System.exit(job.waitForCompletion(true)?0:1); } }
8.运行代码
在FileOutputMR类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
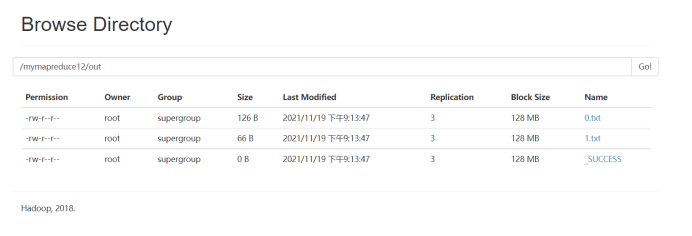
9.查看实验结果
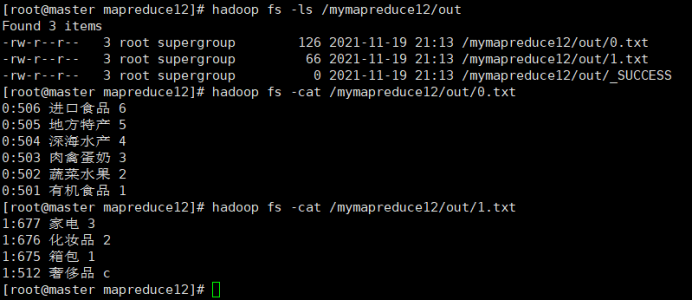
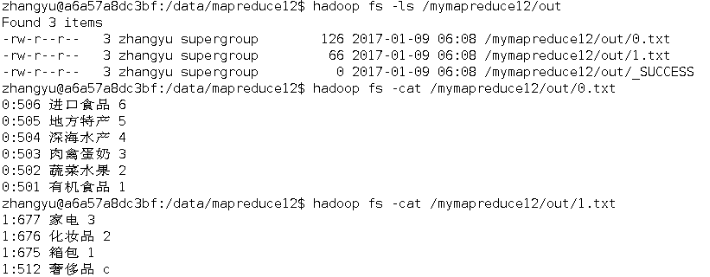
待执行完毕后,进入命令模式下,在HDFS中/mymapreduce12/out查看实验结果。
hadoop fs -ls /mymapreduce12/out
hadoop fs -cat /mymapreduce12/out/0.txt
hadoop fs -cat /mymapreduce12/out/1.txt
图一为我的运行结果,图二为实验结果
经过对比,发现结果一样
此处为浏览器截图