(1) 一道面试题的背景引入
各位在面试的时候很容易会被问到,你们的系统是怎么处理高并发的场景的?让很多人头疼不已,今天就给大家科普一下。
(2)先考虑一个最简单的系统架构
简单的架构,单机部署,单数据库。
差不多每秒十次左右。
此时假设你的系统用户量总共就10万左右。

分摊到每一秒也就:10次。完全不用考虑并发的问题。
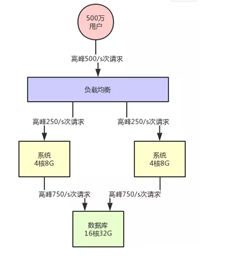
(3)系统集群化部署
此时如果用户增长到了500万,每秒的请求500次左右。
然后对数据库的每秒请求数量是1500/s,这个时候会怎么样呢?
4核8G的机器每秒请求达到500/s的时候,很可能你会发现你的机器CPU负载较高了。
数据库层面,以上述的配置而言,其实基本上1500/s的高峰请求压力的话,还算可以接受。
你可以在前面挂一个负载均衡层,把请求均匀打到系统层面,让系统可以用多台机器集群化支撑更高的并发压力。
但是集群的设计需要一个请求分发机构:负载均衡系统架构就变成这样了。
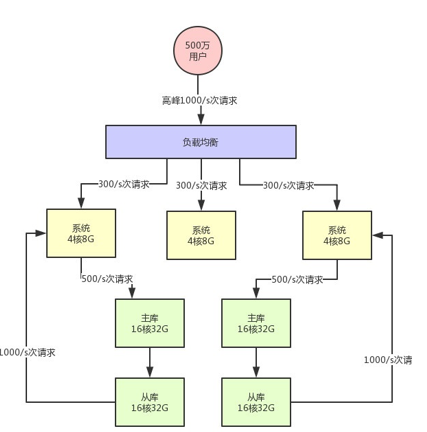
(4)数据库分库分表 + 读写分离
假设此时用户量继续增长,达到了1000万注册用户,然后每天日活用户是100万。
那么此时对系统层面的请求量会达到每秒1000/s,系统层面,你可以继续通过集群化的方式来扩容,反正前面的负载均衡层会均匀分散流量过去的。
但是,这时数据库层面接受的请求量会达到3000/s,这个就有点问题了。
超过了平均1500上限的两倍。
没错,一般来说,对那种普通配置的线上数据库,建议就是读写并发加起来,按照上述我们举例的那个配置,不要超过3000/s。
首先一个问题就是高峰期系统性能可能会降低,因为数据库负载过高对性能会有影响。
另外一个万一把你的数据库给搞挂了 咋办。
所以此时你必须得对系统做分库分表 + 读写分离,也就是把一个库拆分为多个库,部署在多个数据库服务上,这是作为主库承载写入请求的。
然后每个主库都挂载至少一个从库,由从库来承载读请求
此时假设对数据库层面的读写并发是3000/s,其中写并发占到了1000/s,读并发占到了2000/s。
(5)缓存集群引入
接着就好办了,如果你的注册用户量越来越大,此时你可以不停的加机器,比如说系统层面不停加机器,就可以承载更高的并发请求。
但是这里有一个很大的问题:数据库其实本身不是用来承载高并发请求的,所以通常来说,数据库单机每秒承载的并发就在几千的数量级,而且数据库使用的机器都是比较高配置,比较昂贵的机器,成本很高。
缓存系统的设计就是为了承载高并发而生。
所以单机承载的并发量都在每秒几万,甚至每秒数十万,对高并发的承载能力比数据库系统要高出一到两个数量级。
具体来说,就是在写数据库的时候同时写一份数据到缓存集群里,然后用缓存集群来承载大部分的读请求。
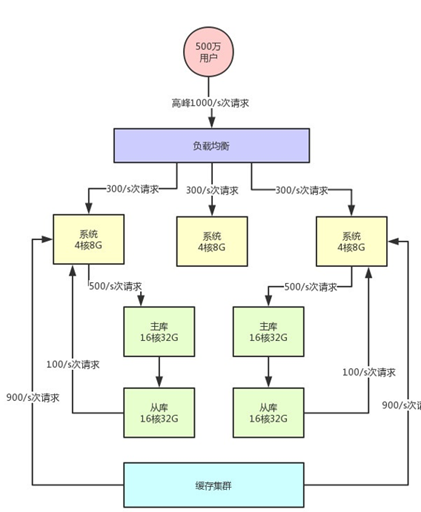
• 不要盲目进行数据库扩容,数据库服务器成本昂贵,且本身就不是用来承载高并发的
• 针对写少读多的请求,引入缓存集群,用缓存集群抗住大量的读请求
(6)引入消息中间件集群
接着再来看看数据库写这块的压力,其实是跟读类似的。
假如说你所有写请求全部都落地数据库的主库层,当然是没问题的,但是写压力要是越来越大了呢?
比如每秒要写几万条数据,此时难道也是不停的给主库加机器吗?
这时消息中间件的分流的作用就凸显出来了。MQ集群,他是非常好的做写请求异步化处理,实现削峰填谷的效果。
假如说,你现在每秒是1000/s次写请求,其中比如500次请求是必须请求过来立马写入数据库中的,但是另外500次写请求是可以允许异步化等待个几十秒,甚至几分钟后才落入数据库内的。
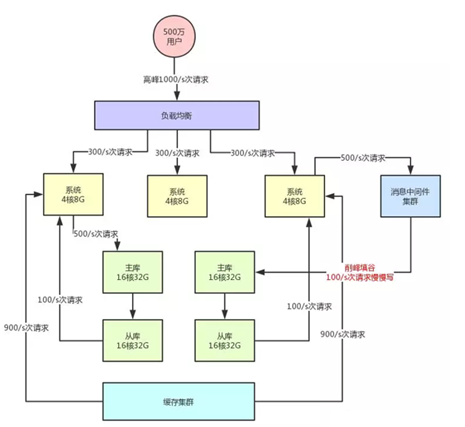
大家看上面的架构图,首先消息中间件系统本身也是为高并发而生,所以通常单机都是支撑几万甚至十万级的并发请求的。
所以,他本身也跟缓存系统一样,可以用很少的资源支撑很高的并发请求,用他来支撑部分允许异步化的高并发写入是没问题的,比使用数据库直接支撑那部分高并发请求要减少很多的机器使用量。
以上介绍了几种方式:
- 系统集群化
- 数据库层面的分库分表+读写分离
- 针对读多写少的请求,引入缓存集群
- 针对高写入的压力,引入消息中间件集群,