import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.linear_model import LinearRegression
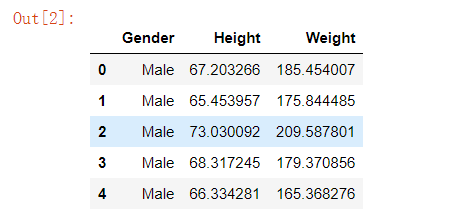
data = pd.read_csv('./training data.txt')
data.head(5)
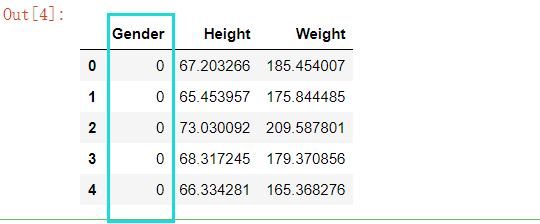
# 数据映射
for col in data.columns[0:1]: # 遍历所有类名
# print(col)
u = data[col].unique() # 得出每个分类下面的种类名称
def convert(x): # 将上面得出的u 进行索引映射
return np.argwhere(u == x)[0,0] # 将上面得出的u 进行索引映射
data[col] = data[col].map(convert) # 将上面得出的u 进行索引映射
data.head(5)
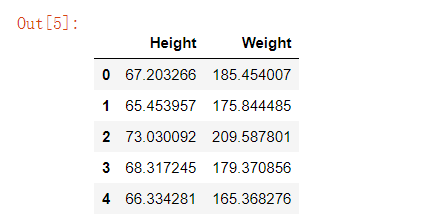
# 数据分类 data.iloc[[行],[列]
X = data.iloc[:,[1,2]]
X.head()
print(type(X))
X.head()
# 数据分类
y = data['Gender']
print(type(y))
y.head()

# 切分训练集跟测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2) # 切分
print("训练集大小",X_train.shape,y_train.shape)
print("测试集大小",X_test.shape,y_test.shape)

# 2: 梯度下降
from sklearn.linear_model import LinearRegression
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 随机梯度下降 要先对数据进行归一化处理
from sklearn.linear_model import SGDRegressor
from sklearn.preprocessing import StandardScaler
# 归一化数据
std = StandardScaler()
std.fit(X_train) # 计算训练集X数据
X_train_std = std.transform(X_train) # 得出归一化训练集X上的归一化值
X_test_std = std.transform(X_test) # 得出归一化测试集X上的归一化值
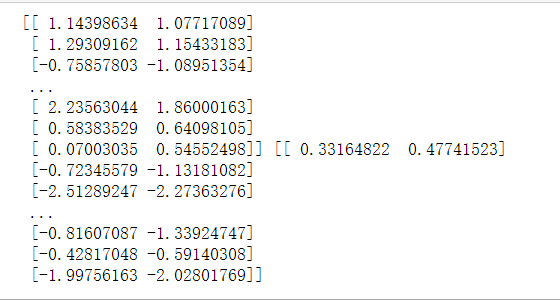
print(X_train_std,X_test_std)
# n_iter代表浏览多少次,默认是5
sgd_reg = SGDRegressor(n_iter=100) # 梯度下降对象实例
sgd_reg.fit(X_train_std, y_train) # 归一化值X训练集 与 y训练集 进行计算训练
res = sgd_reg.score(X_test_std, y_test) # 比较y预测值跟训练之的对比值
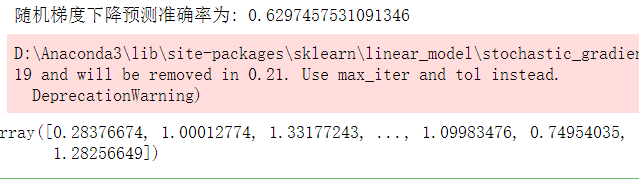
print("随机梯度下降预测准确率为:",res)
y_test_std = sgd_reg.predict(X_test_std) # 预测值
y_test_std
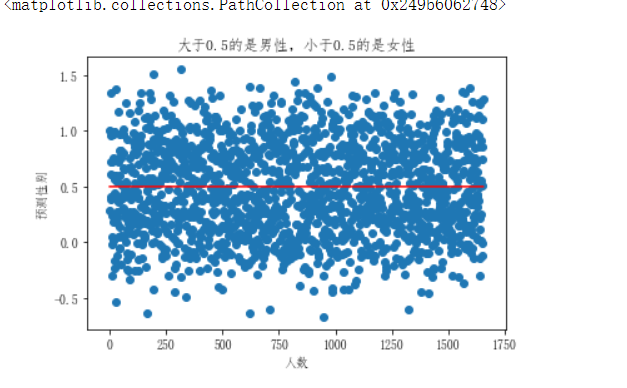
# 梯度下降预测集图
y_data = np.array(y_test_std)
x_data = np.arange(1,len(y_test)+1)
z=np.arange(1,len(y_test)+1)
m=np.array([0.5]*len(y_test))
plt.plot(z,m,label="分割线",color='red')
plt.xlabel("人数")
plt.ylabel("预测性别")
plt.title("大于0.5的是男性,小于0.5的是女性")
plt.scatter(x_data,y_data)