SSD: Single Shot MultiBox Detector——目标检测
参考https://blog.csdn.net/u010167269/article/details/52563573
目标检测算法可分为两种类型:one-stage和two-stage,两者的区别在于前者是直接基于网络提取到的特征和预定义的框(anchor)进行目标预测;后者是先通过网络提取到的特征和预定义的框学习得到候选框(region of interest,RoI),然后基于候选框的特征进行目标检测
- one-stage:代表是SSD(sigle shot detection)和YOLO(you only look once)等
- two-stage:代表是Faster-RCNN 等
两者的差异主要有两方面:
- 一方面是one-stage算法对目标框的预测只进行一次,而two-stage算法对目标框的预测有两次,类似从粗到细的过程
- 另一方面one-stage算法的预测是基于整个特征图进行的,而two-stage算法的预测是基于RoI特征进行的。这个RoI特征就是初步预测得到框(RoI)在整个特征图上的特征,也就是从整个特征图上裁剪出RoI区域得到RoI特征
SSD算法首先基于特征提取网络提取特征,然后基于多个特征层设置不同大小和宽高比的anchor,最后基于多个特征层预测目标类别和位置
SSD算法在效果和速度上取得了非常好的平衡,但是在检测小尺寸目标上效果稍差,因此后续的优化算法,如DSSD、RefineDet等,主要就是针对小尺寸目标检测进行优化
在整体流程上,主要可以分为三大部分:
- 主网络部分:主要用来提取特征,常称为backbone,一般采用图像分类算法的网络即可,比如常用的VGG和ResNet网络,目前也有在研究专门针对于目标检测任务的特征提取网络,比如DetNet
- 预测部分:包含两个支路——目标类别的分类支路和目标位置的回归支路。预测部分的输入特征经历了从单层特征到多层特征,从多层特征到多层融合特征的过程,算法效果也得到了稳定的提升。其中Faster RCNN算法是基于单层特征进行预测的例子,SSD算法是基于多层特征进行预测的例子,FRN算法是基于多层融合特征进行预测的例子
- NMS操作:(non maximum suppression,非极大值抑制)是目前目标检测算法常用的后处理操作,目的是去掉重复的预测框
在SSD中使用的名词是default box,其含义和anchor相同
SSD离散化边界框(bounding boxes)的输出空间成在每个feature map位置有着不同aspect ratio和scales的default boxes集
(feature map就是每一层卷积层的输出,即下一层的输入)
在预测的时候,网络会对每个default box判断其为每个目标类别的可能行,并进行打分,并对default box的形状进行调整,使其能够更好地匹配目标的形状。比如如果有20种目标类别,加上背景则是21种,那么对于每个feature map位置上的每个default box,都要去判断他们是这21种类别的可能性,并进行打分,分数越高,说明其为该类别的可能性越大
除此之外,网络合并来自多个有着不同分辨率的feature maps的预测结果来解决目标有着不同大小的问题
相对于那些需要 object proposals 的检测模型,本文的 SSD 方法完全取消了 proposals generation、subsequent pixel resampling 或者 feature resampling 这些阶段,并将所有计算封装在一个网络中。这样使得 SSD 更容易去优化训练,也更容易地将检测模型融合进需要检测成分的系统之中。
在 PASCAL VOC、MS COCO、ILSVRC 数据集上的实验证明,SSD 相对于需要额外对象proposal step的方法有着更强的准确率,并且更快
如果输入大小为300×300的 PASCAL VOC 2007 test 图像,在 Titan X 上,SSD 以 58 帧的速率,取得了 72.1%的 mAP。如果输入的图像是 500×500大小,SSD 则取得了 75.1%的 mAP,比目前最 state-of-art 的 Faster R-CNN 要好很多。
SSD 相比较于其他单结构模型(YOLO),SSD 取得更高的精度,即是是在输入图像较小的情况下。
在该论文之前,人们通过牺牲准确率来提高预测速度。但SSD是通过取消了 proposals generation、subsequent pixel resampling 或者 feature resampling 这些阶段来提高运行速度的
SSD的改进还有使用小卷积核去预测目标类别和bounding box位置的偏置offsets,对不同aspect ratio的box的检测使用不同的卷积核,并将这些卷积核应用于网络后期的多个特征映射feature map,以便在多个尺度multiple scales上进行检测
总结贡献是:
- 比YOLO等one-stage方法更快,比Faster-RCNN等two-stage等方法更准确
- SSD的核心是将小的卷积核用在features map上的固定default bounding boxes集上去预测类别分数和框的偏置offset
- 为了得到更高的准确度,对不同大小的feature maps中去进行不同大小的预测,并根据aspect ratio明确区分预测
- 这些设计特点导致了简单的端到端训练和高精度,即使在低分辨率的输入图像,进一步提高了速度与精度的权衡。
- 实验包括在PASCAL VOC、COCO和ILSVRC上对不同输入大小的模型进行定时和精度分析,并与一系列最新的最先进方法进行比较。
The Single Shot Detector (SSD)
下面解释SSD用于检测的框架

图(a)表示在训练时,SSD只需要一个输入图片以及对每个目标的ground truth boxes(GT boxes)
在一个卷积方式中,我们会对在一些不同大小(如图(b)和(c)的8*8和4*4大小) 的feature maps中有着不同aspect ratios的一个小default boxes集进行评估。对于每个default box,我们会预测它的形状offset(如上图c的loc: (cx, cy, w, h))和其对于所有类别的置信度(如上图c的conf : (c1,c2,...,cp))
在训练时,我们会首先将这些default boxes和ground truth box进行匹配。比如上图b中有两个default boxes和cat的ground truth boxes匹配,c中有一个和dog的GT box匹配,他们会作为正样本,其他会作为负样本
该模型的损失是定位损失(localization loss,即上面的loc)和置信度损失(即上面的conf)之间的加权和
8*8的feature map中就会有8*8*K个 (k为一个feature map cell上设置的default boxes个数) default boxes,即每个cell上都会有k个default boxes。如上面的图b和c可见,以其中间的格为中心,发散绘制default boxes,最大的default box在3*3的大小内,因为后面作为预测器的卷积核的大小就是3*3的,最小的default box即中间那个小于cell的box
Model
SSD时目前应用非常广泛的目标检测算法,其网络结构如下图所示:
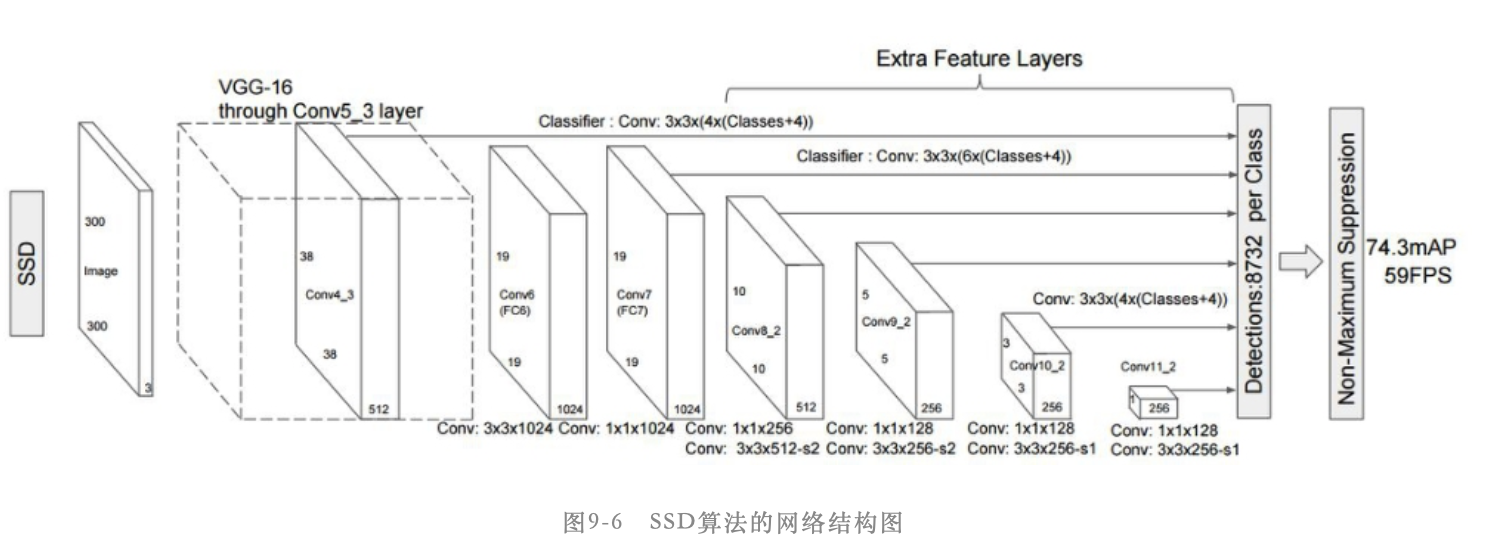
该算法采用修改后的16层网络作为特征提取网络,修改内容主要是将2个全连接层(图中的FC6和FC7)替换成了卷积层(图中的Conv6和Conv7),另外将第5个池化层pool5 改成不改变输入特征图的尺寸。然后在网络的后面(即Conv7后面)添加一系列的卷积层(Extra Feature Layer),即图中的Conv8_2、Conv9_2、Conv10_2和Conv11_2,这样就构成了SSD网络的主体结构。
这里要注意Conv8_2、Conv9_2、Conv10_2和Conv11_2并不是4个卷积层,而是4个小模块,就像是resent网络中的block一样。以Conv8_2为例,Conv8_2包含一个卷积核尺寸是1*1的卷积层和一个卷积核尺寸为3*3的卷积层,同时这2个卷积层后面都有relu类型的激活层。当然这4个模块还有一些差异,Conv8_2和Conv9_2的3*3卷积层的stride参数设置为2、pad参数设置为1,最终能够将输入特征图维度缩小为原来的一半;而Conv10_2和Conv11_2的3*3卷积层的stride参数设置为1、pad参数设置为0
Multi-scale feature maps for detection
在SSD算法中采用基于多个特征层进行预测的方式来预测目标框的位置,具体而言就是使用Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2这6个特征层的输出特征图来进行预测。假设输入图像大小是300*300,那么这6个特征层的输出特征图大小分别是38*38、19*19、10*10、5*5、3*3和1*1。
Convolutional predictors for detection用于检测的卷积预测器,即卷积核
对于一个大小为m*n,有着p个channels的特征层,潜在检测的预测参数的基本元素是3*3*p的小卷积核,用来生成某个类别的分数或相对于default box坐标的shape offset。对于该卷积核应用到的m*n个位置都会生成一个输出值
卷积核的大小为3*3是因为每个feature map cell上的default boxes的最大形状是以自身cell为中心向外扩3*3大小的box
Default boxes and aspect ratios
每个特征层都会有目标类别的分类支路和目标位置的回归支路,这两个支路都是由特定 卷积核数量的卷积层构成的,假设在某个特征层的特征图上每个点设置了k个anchor,目标的类别数一共是N,那么分类支路的卷积核数量就是K*(N+1),其中1表示背景类别;回归支路的卷积核数量就是K*4,其中4表示坐标信息。所以两个支路的总卷积核数量就是k*(N+1+4)。因此对于某个大小为m*n大小的feature map,总的输出结果数量为m*n*k*(N+1+4)
最终将这6个预测层的分类结果和回归结果分别汇总到一起就构成整个网络的分类和回归结果
下面是详细说明:
从上面的网络结构图中可以看出来,对于Conv4_3层的feature map的分类器卷积核为3*3(4*(类别数+4)),意思就是卷积核大小为3*3,每个位置设置的default boxes个数为4,所以该层用来分类和回归的卷积核个数为6*(类别数+4)。对于Conv7、Conv8_2和Conv9_2的default boxes数量为6,对于Conv10_2和Conv11_2的default boxes数量为4
比如我们要对Conv4_3层38*38的feature map计算其loc,用于回归,那么就是使用一个3*3*(4*4),即3*3*16大小的卷积核进行计算(4*4即每个位置的4个default boxes计算4个坐标offset),然后得到32*16*38*38,32为batch size,然后会对维度进行交换变为32*38*38*16,再进行flatten变为32*23104。这就得到了一个batch中所有default boxes的23104个坐标值。
同样的,如果做的是分类,计算置信度conf,假设类别个数为20,还有一个背景类别,卷积核为3*3*(4*21)
倒数第二列的8732表示的是这6个预测层对于每个类设置的default boxes的数量总和,计算为:
8732 = 38*38*4 + 19*19*6 + 10*10*6 + 5*5*6 + 3*3*4 + 1*1*4(38*38是Conv4_3层的feature map大小,以此类推)
然后最后进行NMS非极大值抑制操作
Training
Matching strategy
在训练过程中,我们需要确定与ground truth检测相关的default boxes,并相应地训练网络。对于每个ground truth框,我们都是从随位置、aspect ratio和scale而变化的default boxes中选择。我们首先将每个ground truth框匹配到具有最佳jaccard重叠的default box(如MultiBox[7])。与MultiBox不同的是,然后我们将default box与jaccard重叠超过阈值(设为0.5)的任何ground truth匹配。这简化了学习问题,允许网络预测多个有着高分的重叠default box,而不是要求它只选择重叠最大的一个。
Training objective目标函数
源自MultiBox目标函数,但扩展为可以处理多个目标类别。xpij ={1,0}表明第i个default box是否匹配第j个ground truth的类别。从上面的匹配策略可知,匹配一个ground truth的default box可能有多个,所以![]() 。总的目标函数是位置损失loc(localization loss)和置信度损失conf(confidence loss)的加权和:
。总的目标函数是位置损失loc(localization loss)和置信度损失conf(confidence loss)的加权和:
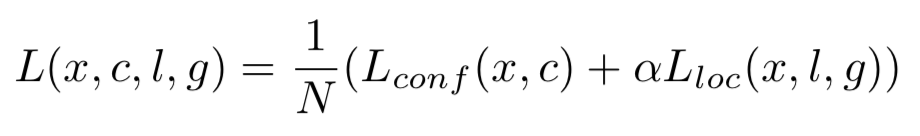
N表示匹配的default boxes的数量。如果N=0,则设置loss=0。
位置损失(localization loss)是预测框(l)和ground truth框(g)参数之间的Smooth L1损失
与Faster R-CNN[2]类似,我们回归到default bounding box(d)的中心(cx, cy)及其宽度(w)和高度(h)的偏移量,如下所示:

即ground truth box根据default box的值去掉偏置后再与预测box求Smooth L1的损失

![]()
置信度损失(confidence loss)是多个类别置信度c的softmax loss:

进行交叉验证(cross validation)时,权重α 设置为1
Choosing scales and aspect ratios for default boxes 选择default boxes的大小和宽高比
为了解决对象大小不同的问题,一些方法是建议将图片处理为不一样的大小,然后最后再将结果合并起来。然而,通过在一个网络中使用多个不同层的特征图进行预测,我们可以模拟相同的效果,同时在所有对象大小内共享参数
使用较低层次的特征图可以提高语义分割质量,因为较低层次可以捕获输入对象的更多细节。添加从特征图中池化而来的全局上下文可以帮助平滑分割结果。受这些方法的启发,我们同时使用高层和低层的特征图进行检测。
幸运的是,在SSD框架中,default boxes不需要对应于每一层的实际接受域。我们设计了default boxes的平铺(tiling),以便特定的feature map能够响应对象的特定大小。假设我们使用m个feature maps进行预测,那么每一个feature map对应的default boxes的大小的计算式子为:
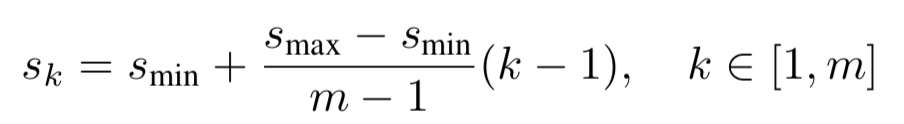
smin=0.2,smax=0.9,意味着最低层(k=1,如conv4_3)的大小为0.2,最高层(k=m,如conv11_2)的大小为0.9,中间层的大小则有规律地间隔
比如这里m=6,sk={0.2, 0.34, 0.48, 0.62, 0.76, 0.9},一般大小设置为2个值,该得到的sk值将对应6个特征层的第一个大小的值,第2个大小的值的计算方式如下所示,是对第k和第k+1个列表的第一个值相乘后求开方得到的
对default boxes使用不同的aspect ratio,表示为ar={1,2,3,1/2,1/3},因此每个default boxes的宽和高的计算公式为:
![]()
因此宽高比 = width / height = ar
当aspect ratio为1时,需要添加一个大小计算方式如下的default box:
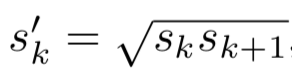
所以最后对于每个feature map位置都有6个default boxes。这是怎么计算得到的呢:
如conv4_3这最低层大小为{0.2, √(0.2*0.34)},有5种不同的宽高比{1,2,3,1/2,1/3},然后先是第一个大小0.2对应所有宽高比得到5个default boxes,再加上当aspect ratio=1时对应大小√(0.2*0.34)得到另一个default box,这样就有6个了default boxes了
我们会将每个default box的中心点设置为![]() ,|fk|表示第k个方形feature map的大小,
,|fk|表示第k个方形feature map的大小,![]()
将来自许多feature map的所有位置中对所有具有不同大小和宽高比的default boxes的预测组合在一起,我们得到了一组不同的预测集,涵盖了不同的输入对象大小和形状。例如,在图1中,狗匹配的是4×4 feature map中的一个default box,而不是8×8 feature map中的任何一个default box。这是因为这些box有不同的大小,与狗的box不匹配,因此在训练中被认为是负样本的,与狗不匹配。
上面有说到conv4_3、conv10_2和conv11_2的default boxes个数为4,是因为其宽高比设置为aspect ratio={1,2,1/2}
Hard negative mining
在生成一系列的 predictions 之后,会产生很多个符合 ground truth box 的 predictions boxes,但同时,不符合 ground truth boxes 也很多,而且这个 negative boxes,远多于 positive boxes。这会造成 negative boxes、positive boxes 之间的不均衡。训练时难以收敛。
因此,本文采取,先将每一个物体位置上对应 predictions(default boxes)是 negative 的 boxes 进行排序,按照 default boxes 的 confidence loss的大小。 选择最高的几个,保证最后 negatives、positives 的比例在 3:1。
本文通过实验发现,这样的比例可以更快的优化,训练也更稳定。
Data augmentation数据增强
为了使模型更具鲁棒性,能满足不同的输入对象大小和形状,每个训练图像都会随机下面任意选项进行采样:
- 使用原始的图像
- 采样一个 patch,与目标之间最小的 jaccard overlap 为:0.1,0.3,0.5,0.7 与 0.9
- 随机的采样一个 patch
采样的 patch 是原始图像大小的[0.1,1]比例,aspect ratio 在 1/2与 2之间。当 ground truth box 的 中心在采样的 patch 中时,我们保留重叠部分。在这些采样步骤之后,每一个采样的 patch 被 resize 到固定的大小,并且以 0.5 的概率随机的水平翻转,除此之外还进行亮度扭曲