参考:https://blog.csdn.net/hsqyc/article/details/81702437
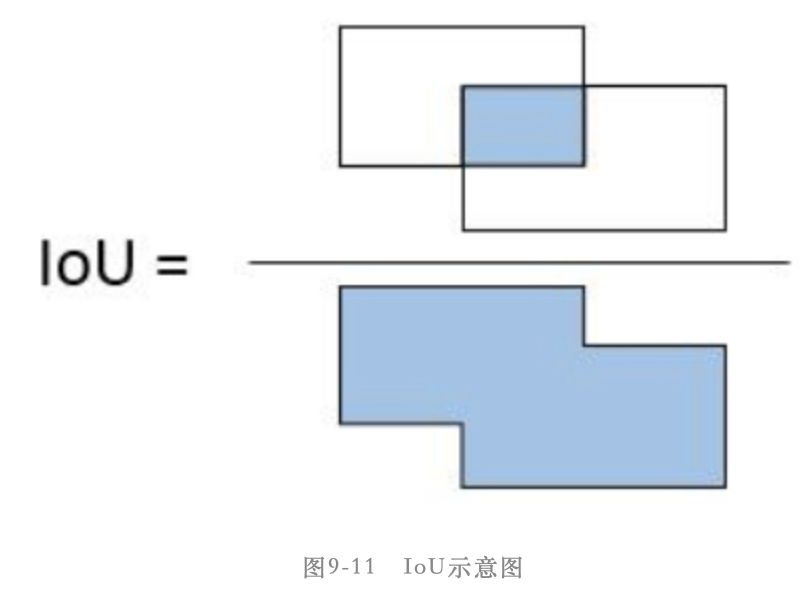
什么是IoU
在目标检测算法中,我们经常需要评价2个矩形框之间的相似性,直观来看可以通过比较2个框的距离、重叠面积等计算得到相似性,而IoU指标恰好可以实现这样的度量。简而言之,IoU(intersection over union,交并比)是目标检测算法中用来评价2个矩形框之间相似度的指标
IoU = 两个矩形框相交的面积 / 两个矩形框相并的面积,如下图所示:
什么是TP TN FP FN
TP、TN、FP、FN即true positive, true negative, false positive, false negative的缩写,positive和negative表示的是你预测得到的结果,预测为正类则为positive,预测为负类则为negative; true和false则表示你预测的结果和真实结果是否相同,相同则是true,不同则为false,如下图:

什么是Precision(精确度)和Recall(召回率)
1)精确度-即查准率
即你模型判断该图片为正类,而该图片也的确是正类的概率
正类的精确度就是指模型判断为正类且真实类别也为正类的图像数量/模型判断为正类的图像数量,衡量的是一个分类器分出来的正类的确是正类的概率,计算公式如下图:
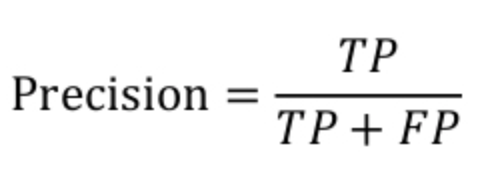
两种极端情况就是,如果精度是100%,就代表所有分类器分出来的正类确实都是正类。如果精度是0%,就代表分类器分出来的正类没一个是正类。
光是精确度还不能衡量分类器的好坏程度,比如50个正样本和50个负样本,我的分类器把49个正样本和50个负样本都分为负样本,剩下一个正样本分为正样本,这样我的精度也是100%,因为分类器分出来1个样本为正类,且这个样本分类正确,则1/1 = 1
所以还需要召回率
2)召回率-即查全率
即所有图片中有5个正类,你的模型能够将这5个图片都正确判断为正类,则召回率为100%
召回率是指模型判为正类且真实类别也是正类的图像数量/真实类别是正类的图像数量,衡量的是一个分类器能把所有的正类都找出来的能力,计算公式为:
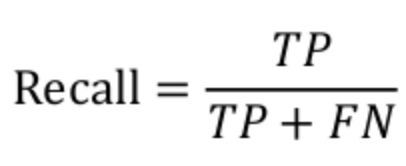
两种极端情况,如果召回率是100%,就代表所有的正类都被分类器分为正类。如果召回率是0%,就代表没一个正类被分为正类
比如有10张图,5张为正类,5张为负类,如果你仅查出TP=3,FN=2,TN=5,那么召回率就是3/5=60%;如果TP=5,FP=2,TN=3,那么召回率为5/5=100%
3)
但是有时候使用两个指标不太好评价模型之间的好坏,因为可能出现模型A的精确度比模型B高,但是A的召回率比模型B低
解决该问题的办法就是结合精确度和召回率计算得到另外一个指标:F1 score,计算公式如下,P表示precision,R表示recall:
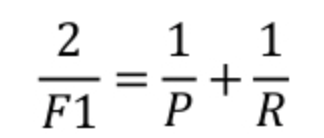
简单换算后可以得到:
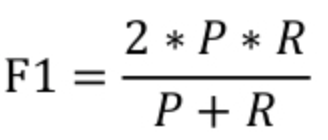
什么是类别置信度:
分类器返回某个目标的类别置信度,即该目标属于A的概率,属于B的概率。即分类器最后softmax得到的结果
AP和mAP
在目标检测算法中常用的评价指标是mAP(mean average precision),这是一个可以用来度量模型预测框类别和位置是否准确的指标。
在目标检测领域常用的公开数据集PASCAL VOC中,有2种mAP计算方式:
- 一种是针对PASCAL VOL 2007数据集的mAP计算方式
- 另一种是针对PASCAL VOC 2012数据集的mAP计算方式
1)AP(average precision)值的计算:
AP就是得出每个类的检测好坏的结果
含义和计算过程如下:
假设某输入图像中有两个真实框:person和dog,模型输出的预测框中预测类别为person的框有5个,预测类别是dog的框有3个,此时的预测框已经经过NMS后处理。
首先以预测类别为person的5个框为例,先对这5个框按照预测的类别置信度进行从大到小排序,然后这5个值依次和person类别的真实框计算IoU值。
假设IoU值大于预先设定的阈值(常设为0.5),那就说明这个预测框是对的,此时这个框就是TP(true positive);假设IoU值小于预先设定的阈值(常设为0.5),那就说明这个预测框是错的,此时这个框就是FP(false positive)。注意如果这5个预测框中有2个预测框和同一个person真实框的IoU大于阈值,那么只有IOU最大的那个预测框才算是预测对了,另一个算是FP。在训练时,先找最大iou的 如果最大iou的置信度大于你设定的置信度就可以用其来计算损失
假设图像的真实框类别中不包含预测框类别,此时预测框类别是cat,但是图像的真实框只有person和dog,那么也算该预测框预测错了,为FP
FN(false negative)的计算可以通过图像中真实框的数量间接计算得到,因为图像中真实框的数量 = TP + FN
得到的person类精确度和召回率都是一个列表,列表的长度和预测类别为person的框相关,所以这里的精确度和召回率的列表的长度是5,因为预测类别为person的框有5个。因此根据这2个列表就可以在一个坐标系中画出该类别的precision和recall曲线图,如下图所示,参考https://github.com/Cartucho/mAP:
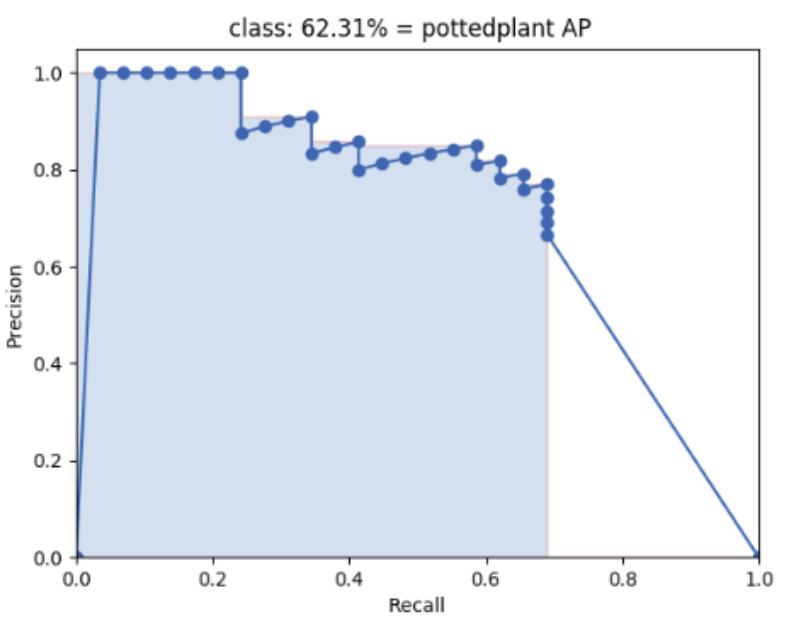
按照PASCAL VOL 2007的mAP计算方式,在召回率坐标轴均匀选取11个点(0, 0.1, ..., 0.9, 1),然后计算在召回率大于0的所有点中,精确度的最大值是多少;计算在召回率大于0.1的所有点中,精确度的最大值是多少;一直计算到在召回率大于1时,精确度的最大值是多少。这样我们最终得到11个精确度值,对这11个精确度求均值就得到AP了,因此AP中的A(average)就代表求精确度均值的过程
⚠️上面的图表示的是PASCAL VOL 2012的mAP计算方式,即每个“峰值点”往左画一条线段直到与上一个峰值点的垂直线相交。这样画出来的红色线段与坐标轴Recall围起来的面积就是AP值。
2)mAP的计算:
mAP就是得出多个类的检测好坏的结果
假设分为两个类:正类和负类,计算得到这两个类AP之和然后除以2就等于mAP
为什么可以使用mAP来评价目标检测的效果;
目标检测的效果取决于预测框的位置和类别是否准确,从mAP的计算过程中可以看出通过计算预测框和真实框的IoU来判断预测框是否准确预测到了位置信息,同时精确度和召回率指标的引用可以评价预测框的类别是否准确,因此mAP是目前目标检测领域非常常用的评价指标