MobileFaceNets: Efficient CNNs for Accurate Real- Time Face Verification on Mobile Devices
该论文简要分析了一下普通的mobile网络用于人脸检测的缺点。这些缺点能够很好地被他们特别设计的MobileFaceNets克服,该网络是一种为了能够在手机和嵌入式设备中实现高准确度的实时人脸检测而进行剪切的一种极其高效的CNN模型类别
该论文的主要贡献有:
在该人脸特征嵌入CNN网络的最后一个卷积层(non-global)之后,使用了一个global depthwise卷积层,而不是一个全局平均池化层或哦一个全连接层去输出一个可区分的特征向量。该选择的优势将在理论和实验中分析
我们设计了一个人脸特征嵌入CNNs网络,命名为MobileFaceNets,在手机和嵌入设备中极其高效
我们在LFW、AgeDB和MegaFace等数据中进行的实验说明了在人脸验证任务中,该MobileFaceNets网络对比于以前最先进的mobile CNNs网络在效率上获得了显著的优化
The Weakness of Common Mobile Networks for Face Verification
目前用于一般的视觉识别任务的最先进的mobile网络都会有一个全局平均池化层,如MobileNetV1、ShuffleNet和MobileNetV2
对于人脸检测和识别任务,一些研究表明不使用全局平均池化层的CNNs网络的效果比使用的好一些,但是东欧没有对该现象进行理论说明
这里我们就简单地以接受域的理论来解释下这个现象:
一个典型的深度人脸检测过程包括预处理人脸图片、通过一个可训练的深度网络来抽取人脸特征、最后通过特征的相似度或距离来对比两张人脸。在预处理步骤使用MTCNN来检测图片上的人脸和5个人脸定位点。然后根据这5个定位点,通过简单的转换来对齐人脸。对齐后的人脸大小为112*112,在RGB图像中每个像素都会减去127.5并除以128来进行归一化。最后一个嵌入人脸特征的CNN网络就会将一个对齐的人脸映射到一个特征向量,如图1所示:
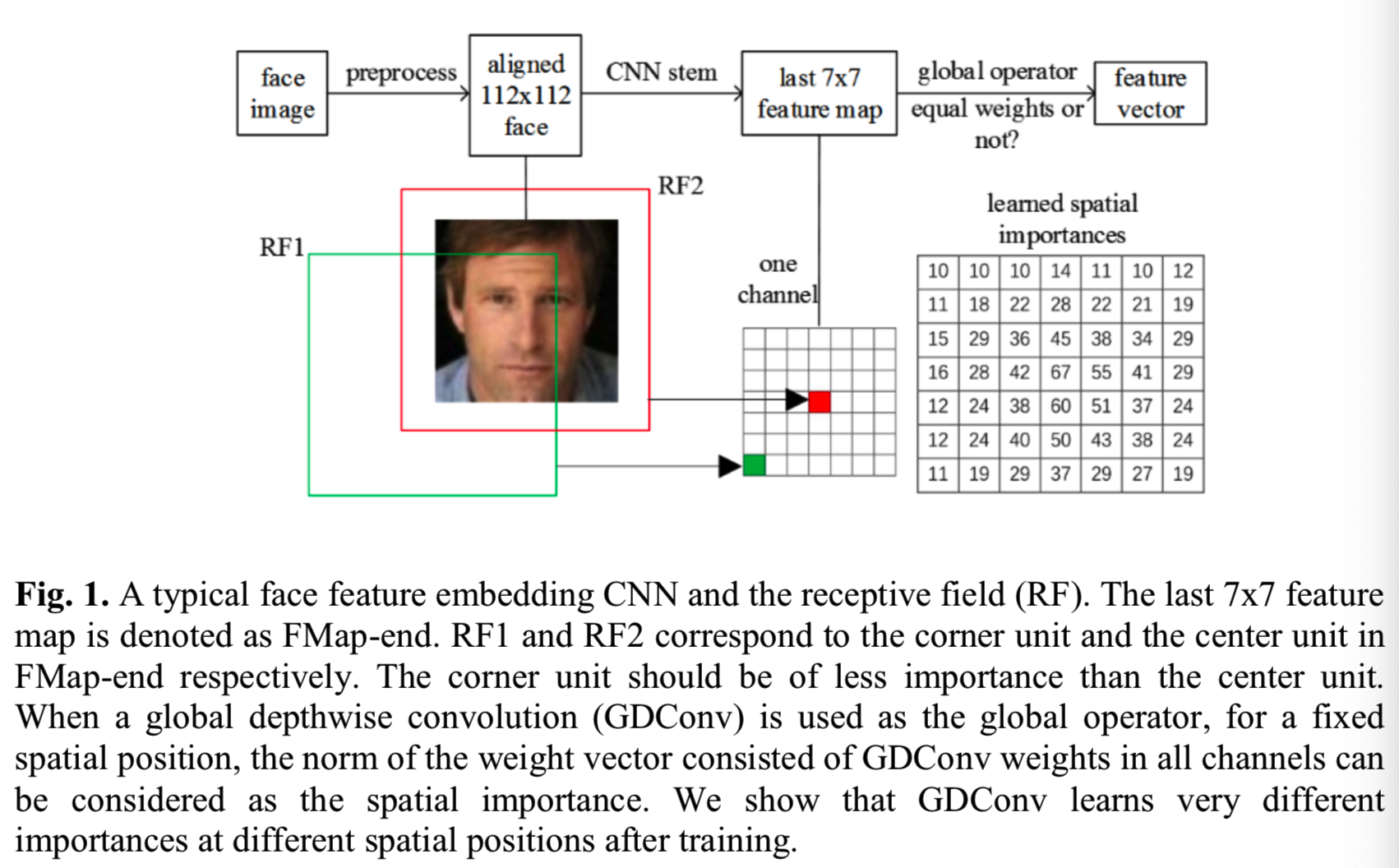
在接下来的讨论中,为了不失一般性,我们使用MobileNetV2作为嵌入人脸特征的CNN网络。为了保持输出feature map的大小与MobileNetV2的输入为224×224的原始网络相同(因为我们的输入是112*112),我们在第一个卷积层中使用stride = 1而不是stride = 2,因为设置stride=2会导致准确率很差。
为了方便起见,在全局平均池化层之前的最后一个卷积层输出的特征映射将被称为FMap-end,其空间分辨率为7*7,虽然理论上FMap-end的中心单元和角落的单元对应输入图像的接受域大小是一样的,但是它们对应的是输入图像的不同位置
FMap-end的角落单元对应的接受域的中心是在输入图像的角落,对应的中心单元对应的接受域的中心是在输入图像的中心,如图1所示。根据[24],一个接受域中心的像素对一个输出有着更大的影响,对于一个输出,其对应的一个接受域的重要性分布是符合高斯分布的。
因此FMap-end的角落单元对应的有效接受域是远远小于中心单元的。当输入图像是一个对齐人脸时,FMap-end的角落单元携带着比中心单元更少的信息。因此,当要抽取一个人脸特征向量时,FMap-end的不同单元是有着不同的重要性的。
在MobileNetV2中,展平的FMap-end不适合直接用作人脸特征向量,因为其有着过高的维度(62720)。因此自然地就会选择使用全局平均池化层(称为GAPool)的输出作为人脸特征向量,但是在很多研究中[14,5],该方法会获得较低的检测准确率(如表2所示)。这是因为全局平均池化层将FMap-end的所有单元都赋予同样的重要性,根据上面的分析可知这是不合理的。因此另一个方法就是选择使用全连接层来将FMap-end投射为一个紧凑的人脸特征向量,但是它将会给整个模型添加大量的参数。即使人脸特征向量只有128维,FMap-end后面的全连接层也会带来额外的8 million参数给MobileNetV2。因此如果我们将更小的模型大小作为追求,就不会考虑这个选择
Global Depthwise Convolution
使用global Depthwise Convolution来替换全局平均池化层,该GDConv层就相当于一个depthwise卷积层,kernel大小为输入大小,padding=0,stride=1。这样能保证输出的大小H*W = 1*1,就相当于下面的实现中的conv_6_dw层
输出的计算公式为:
![]()
F是大小为W*H*M的输入特征映射,K是大小为W*H*M的depthwise卷积核(只有一个卷积核,因为设置groups=M),输出的大小为1*1*M,因为对应的每个m通道中只有一个元素Gm(因为H*W=1*1)。(i,j)表示F和K的W*H对应的空间位置,m表示的是通道索引
因此计算cost为:
![]()
模型设计为:
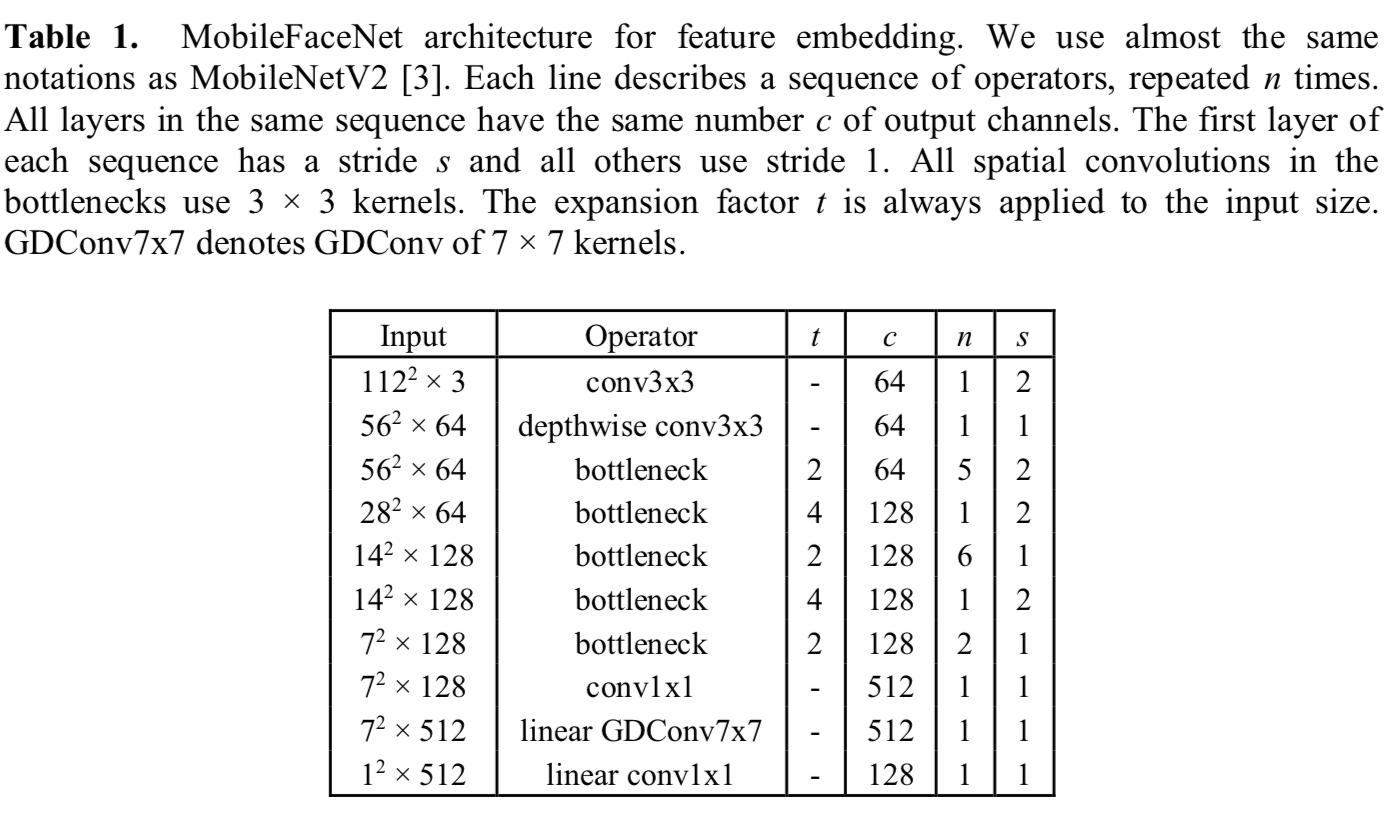
实现,参考https://github.com/TreB1eN/InsightFace_Pytorch:


#coding:utf-8 from torch.nn import Linear, Conv2d, BatchNorm1d, BatchNorm2d, PReLU, ReLU, Sigmoid, Dropout2d, Dropout, AvgPool2d, MaxPool2d, AdaptiveAvgPool2d, Sequential, Module, Parameter class Flatten(Module): def forward(self, input): return input.view(input.size(0), -1) class Conv_block(Module): def __init__(self, in_c, out_c, kernel=(1, 1), stride=(1, 1), padding=(0, 0), groups=1): super(Conv_block, self).__init__() self.conv = Conv2d(in_c, out_channels=out_c, kernel_size=kernel, groups=groups, stride=stride, padding=padding, bias=False) self.bn = BatchNorm2d(out_c) self.prelu = PReLU(out_c) def forward(self, x): x = self.conv(x) x = self.bn(x) x = self.prelu(x) return x class Linear_block(Module): def __init__(self, in_c, out_c, kernel=(1, 1), stride=(1, 1), padding=(0, 0), groups=1): super(Linear_block, self).__init__() self.conv = Conv2d(in_c, out_channels=out_c, kernel_size=kernel, groups=groups, stride=stride, padding=padding, bias=False) self.bn = BatchNorm2d(out_c) def forward(self, x): x = self.conv(x) x = self.bn(x) return x class Depth_Wise(Module): def __init__(self, in_c, out_c, residual = False, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=1): super(Depth_Wise, self).__init__() self.conv = Conv_block(in_c, out_c=groups, kernel=(1, 1), padding=(0, 0), stride=(1, 1)) self.conv_dw = Conv_block(groups, groups, groups=groups, kernel=kernel, padding=padding, stride=stride) self.project = Linear_block(groups, out_c, kernel=(1, 1), padding=(0, 0), stride=(1, 1)) self.residual = residual def forward(self, x): if self.residual: short_cut = x x = self.conv(x) x = self.conv_dw(x) x = self.project(x) if self.residual: output = short_cut + x else: output = x return output class Residual(Module): def __init__(self, c, num_block, groups, kernel=(3, 3), stride=(1, 1), padding=(1, 1)): super(Residual, self).__init__() modules = [] for _ in range(num_block): modules.append(Depth_Wise(c, c, residual=True, kernel=kernel, padding=padding, stride=stride, groups=groups)) self.model = Sequential(*modules) def forward(self, x): return self.model(x) class MobileFaceNet(Module): def __init__(self, embedding_size): super(MobileFaceNet, self).__init__() self.conv1 = Conv_block(3, 64, kernel=(3, 3), stride=(2, 2), padding=(1, 1)) self.conv2_dw = Conv_block(64, 64, kernel=(3, 3), stride=(1, 1), padding=(1, 1), groups=64) self.conv_23 = Depth_Wise(64, 64, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=128) self.conv_3 = Residual(64, num_block=4, groups=128, kernel=(3, 3), stride=(1, 1), padding=(1, 1)) self.conv_34 = Depth_Wise(64, 128, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=256) self.conv_4 = Residual(128, num_block=6, groups=256, kernel=(3, 3), stride=(1, 1), padding=(1, 1)) self.conv_45 = Depth_Wise(128, 128, kernel=(3, 3), stride=(2, 2), padding=(1, 1), groups=512) self.conv_5 = Residual(128, num_block=2, groups=256, kernel=(3, 3), stride=(1, 1), padding=(1, 1)) self.conv_6_sep = Conv_block(128, 512, kernel=(1, 1), stride=(1, 1), padding=(0, 0)) self.conv_6_dw = Linear_block(512, 512, groups=512, kernel=(7,7), stride=(1, 1), padding=(0, 0)) self.conv_6_flatten = Flatten() self.linear = Linear(512, embedding_size, bias=False) self.bn = BatchNorm1d(embedding_size) def forward(self, x): out = self.conv1(x) out = self.conv2_dw(out) out = self.conv_23(out) out = self.conv_3(out) out = self.conv_34(out) out = self.conv_4(out) out = self.conv_45(out) out = self.conv_5(out) out = self.conv_6_sep(out) out = self.conv_6_dw(out) out = self.conv_6_flatten(out) out = self.linear(out) out = self.bn(out) return l2_norm(out)
查看:
if __name__ == '__main__': model = MobileFaceNet(512) # for model in model.modules(): # print(model) for child in model.children(): print(child)
返回:
Conv_block( (conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=64) ) Conv_block( (conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=64) ) Depth_Wise( (conv): Conv_block( (conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (conv_dw): Conv_block( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=128, bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (project): Linear_block( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) Residual( (model): Sequential( (0): Depth_Wise( (conv): Conv_block( (conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (conv_dw): Conv_block( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (project): Linear_block( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Depth_Wise( (conv): Conv_block( (conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (conv_dw): Conv_block( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (project): Linear_block( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (2): Depth_Wise( (conv): Conv_block( (conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (conv_dw): Conv_block( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (project): Linear_block( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (3): Depth_Wise( (conv): Conv_block( (conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (conv_dw): Conv_block( (conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=128) ) (project): Linear_block( (conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) ) ) Depth_Wise( (conv): Conv_block( (conv): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) Residual( (model): Sequential( (0): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (2): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (3): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (4): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (5): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) ) ) Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=512) ) (conv_dw): Conv_block( (conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=512, bias=False) (bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=512) ) (project): Linear_block( (conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) Residual( (model): Sequential( (0): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): Depth_Wise( (conv): Conv_block( (conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (conv_dw): Conv_block( (conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False) (bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=256) ) (project): Linear_block( (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) ) ) Conv_block( (conv): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (prelu): PReLU(num_parameters=512) ) Linear_block( (conv): Conv2d(512, 512, kernel_size=(7, 7), stride=(1, 1), groups=512, bias=False) (bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) Flatten() Linear(in_features=512, out_features=512, bias=False) BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
模型:


其中的Residual层就是Inverted residual block