GroupFace: Learning Latent Groups and Constructing Group-based Representations for Face Recognition
Abstract
在人脸识别领域中,模型学习使用更少维度的嵌入特征来区分百万级的人脸图像,且这样大量的信息不可能使用单一分支的卷积模型就能够恰当地编码。我们提出了一个新的特定的人脸识别结构,称为GroupFace,能够同时使用多个group-aware表征,以改善嵌入特征的质量。该提出的方法提供了子分布标签,能够在不需要额外人物标注的情况下平衡属于每个组的样本的数量;同时学习group-aware表征能够缩小目标身份的搜索空间。我们通过展示扩展的ablation研究和可视化来证明所提方法的有效性。所提方法的所有组成部分都能够以端到端的方式训练,计算复杂度略有增加。最后,所提方法在下述公开数据集,如:LFW, YTF, CALFW, CPLFW,CFP, AgeDB-30, MegaFace, IJB-B and IJB-C 的1:1人脸验证和1:N人脸识别任务中以极大的改进获得了最先进的结果
1. Introduction
第一二段讲了下最近人脸识别的优化方法,即大量数据集、深度学习以及损失函数的改进
尽管损失函数得到了发展,但通用网络,不是为人脸识别而设计的网络,在有效训练网络以识别大量的人身份方面还存在困难。不像分类等常见问题,在评估阶段,人脸识别模型会遇到不包含在训练集的新身份。因此,该模型需要在训练集中嵌入近100k个身份[10],和考虑大量未知的身份。然而,现有的方法大多只是在VGG[25]、ResNet[12]等广泛使用的backbone网之后附加几个全连接的层,而没有对人脸识别的特征进行设计。
Grouping是高效灵活地嵌入大量人员并能简要描述未知人员的关键思想。每个人的脸上都有自己的特点。与此同时,他们在一群人中也有共同之处。在现实世界中,基于group的描述(如有着深邃的黑眼睛和红胡子的男人)涉及到群体中的共同特征,可以帮助缩小候选人范围,尽管它不能确定确切的人。遗憾的是,显式分组需要对海量数据进行手工分类,可能受到人类知识描述范围有限的限制,但通过采用分组的概念,识别网络可以减少搜索空间,灵活地将大量身份嵌入到一个嵌入特征中。
我们提出一个新的人脸识别架构,称为GroupFace,学习多个潜在的groups和构造group-aware的表征去有效采用分组(图1)的概念:
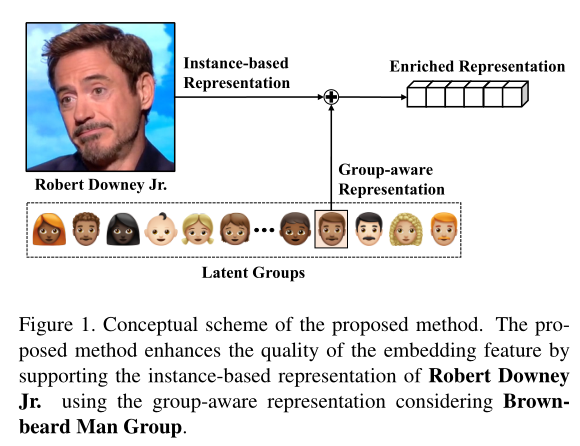
我们定义Latent Groups, 其被内部确定为通过综合考虑面部因素(如头发、姿势,胡子)和非面部因素(如噪声、背景、照明)决定的潜在变量。为了学习Latent Groups,我们引入了一种通过考虑Latent Groups的整体分布来确定group标签的自分布分组方法。在结构上,该方法GroupFace将多个group-aware表征集成到原始的基于实例的表征中去进行人脸识别(即图1将图像这个实例表征和下面的latent groups表征合并成一个Enriched表征)。
我们将其贡献总结如下:
- GroupFace是一种新型的人脸识别专用体系结构,它将群group-aware表征集成到嵌入特征中,并提供分布良好的group标签以提高特征表示的质量。GroupFace还提出了一种新的相似性度量方法来考虑group信息。
- 通过大量的实验和消融研究,证明了GroupFace算法的有效性。
- GroupFace可以应用于许多现有的人脸识别方法,在资源边际增加(即少量增加)的情况下获得显著的改进。特别是GroupFace的hard-ensemble版本,只需自适应地使用少量附加卷积,就可以获得较高的识别精度。
2. Related Works
Face Recognition (省略以前方法的介绍)。一般来说,这些方法的重点是如何改进损失函数,以提高传统的特征表征的人脸识别的准确性。一个轻微的变化,如增加一些层或增加通道的数量,通常不会带来明显的改善。GroupFace提高了特征表征的质量,同时通过增加一些层取得了显著的改进。
分组(Grouping)或聚类方法,如k-means,通过考虑相对度量,如余弦相似度或欧氏距离,来内部分类没有明确的类标签的样本。通常,这些聚类方法试图通过防止将大多数图像分配到一个或几个聚类来构建能良好区分的类别。最近,已经引入了几种使用深度学习的方法[4,24,40]。这些方法是有效的,但是,他们在以前的方法中使用完整的batches,而不是如在深度学习中使用mini-batch。因此,这些方法不能很容易地在应用程序框架中深入地、端到端地合并。为了有效地学习latent groups,我们引入了一种以深度的方式考虑期望-归一化概率的自分布分组方法。
3. Proposed Method
我们的GroupFace使用自分布分组的方法来学习latent group,构造多个group-aware表征,并将其集成到标准的基于实例的表征中,以丰富人脸识别的特征表示。
3.1. GroupFace
讨论了如何将latent groups方案有效地集成到GroupsFace的嵌入特征中。
Instance-based Representation. 我们将调用一个传统人脸识别方案[7,34,35,44]中的特征向量作为本文基于实例的表征(如图2所示):

基于实例的表征通常通过使用基于softmax的损失(例如,CosFace[34]和ArcFace[7]), 作为一个嵌入特征被训练,用于预测一个身份:
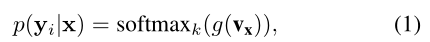
其中yi是身份标签,vx是给定样本x的基于实例的表征,g是将512维的嵌入特征投影到M维空间中的函数。M是个人身份的数量。
Group-aware Representation. GroupFace使用了一种新的group-aware表征和基于实例的表征来丰富嵌入特征。提取每个group-aware表征向量通过为每个相应的group部署全连接层抽取得到(如图2所示)。GroupFace的嵌入特性( ,在图2的最后表征)是通过聚合基于实例的表征vx和权重求和的group-aware表征vxG得到的。GroupFace使用加强后的最终表征来预测身份为:
,在图2的最后表征)是通过聚合基于实例的表征vx和权重求和的group-aware表征vxG得到的。GroupFace使用加强后的最终表征来预测身份为:
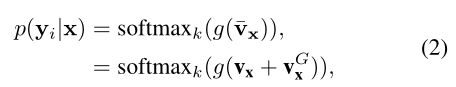
其中vxG是具有group概率的多个group-aware表征的集合。
Structure. GroupFace同时计算和使用基于实例的表征和group-aware的表征。基于实例的表征通过在传统的人脸识别方法[7,34,35,44]中使用的相同方法来获得,K个group-aware表征方法通过部署全连接层得到。然后,通过部署由3个全连接层和一个softmax层组成的Group Decision Network(GDN),利用基于实例的表示向量计算群概率。使用利用group概率,对多个group-aware表征进行以soft方式(S-GroupFace)子集成或以hard方式(H-GroupFace)子集成。
S-GroupFace使用组对应的概率作为权重来集成多个group-aware的表征,定义为: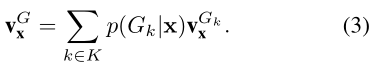
H-GroupFace则选择group-aware表征中对应的组概率最大的那个,表示为:
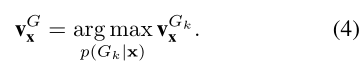
S-GroupFace显著提高了识别精度,仅需要少量的额外资源;H-GroupFace比S-GroupFace更适合于实际应用,但代价是增加了一些额外的卷积。通过聚合基于实例的表征和子集合的group-aware表征,可以加强最终表示为。
Group-aware Similarity. 我们引入了一种group-aware相似度,它是一种新的相似度,同时考虑了GDN在推理阶段的标准嵌入特征和中间特征。由于中间特征没有在余弦空间上训练,只是描述了给定样本的group身份,而不是给定样本的显式身份,因此group-aware的相似性被两个给定实例的中间特征之间的距离所抵消。第i个图像Ii和第j个图像Ij之间的group-aware相似性S∗定义为:
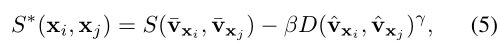
式中:S为余弦相似度度量,D为距离度量, 为GDN的中间特征,β 和 γ为常量参数。根据经验确定参数β = 0.1 和 γ=1/3
为GDN的中间特征,β 和 γ为常量参数。根据经验确定参数β = 0.1 和 γ=1/3
3.2. Self-distributed Grouping
在这项工作中,我们将一个组定义为一组样本,这些样本具有用于人脸识别的任何共同的视觉或非视觉特征。这样的组由一个部署的GDN决定。我们的GDN以一种自分组的方式逐步训练,这种自分组方式在没有任何明确的group-truth信息的情况下,考虑了latent groups的分布,提供了一个组标签。
Na¨ıve Labeling. 简单地确定一组标签的方法是采取softmax的最大激活输出的索引作为标签。通过部署MLP并附加一个softmax函数,我们构建了一个GDN f来确定一个归属组G∗:

其中Gk表示第k组。缺乏考虑的group分布会导致na¨ıve的解决方案使得大多数样本被分配给一个或某几个组。
Self-distributed Labeling. 提出了一种利用先验概率调节的修正概率深度生成均匀分布的组标签的有效标记方法。我们定义一个expectation-normalized概率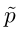 去平衡样本在K组的数量:
去平衡样本在K组的数量:
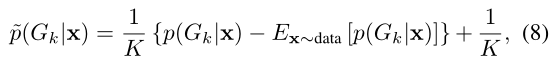
第一个1/K限定了标准化概率在0到1之间。然后计算期望-归一化概率的期望为:

因此优化后的子分布标签为:
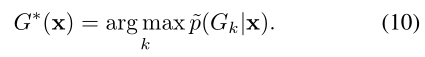
经过训练的GDN估计一组概率,表示样本属于latent groups的程度。当样本数趋于无穷大时,该方法将稳定输出均匀分布的标签(图3):

3.3. Learning
GroupFace网络同时采用基于softmax的标准分类丢失(用于识别身份的丢失)和自分组丢失(用于训练潜在群的丢失)进行训练。
Loss Function. 使用基于softmax的损失L1(主要使用ArcFace[7])训练身份特征表征,定义为:
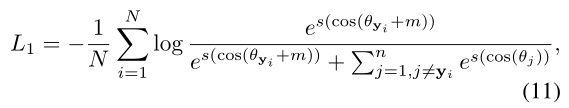
式中,N为小批样本的数量; Θ为特征和对应权重的角度, s是尺寸因子, m是边际因子。为了构建最优组空间,使用一个self-grouping损失来减少预测和子生成标签之间的差距:

Training. 整个网络使用集成的两个损失训练:

其中参数λ用来平衡不同损失之间的权重,这里设置为0.1.因此GDN可以学习组,这是有益于人脸识别的
其实这个网络就是在中间添加了一个分组的操作,对特征表征进行加强操作,使用最后集成得到的最终特征表征去进行人脸识别
4. Experiments
省略
Experimental Setting. 我们通过BN-FC块将激活向量化,并将激活减少到4096*1*1(即图2中的Shared Feature)。我们的GroupFace是在ResNet-100的res5c层后附加上的,res5c层输出激活维数为512×7×7(所以Shared Feature为4096=512×7×7)。GDN中的MLP由两个BN-FC块组成,GDN中还有一个用于组分类的FC(所以GDN中有三个FC层)。我们遵循[7,34]来设置损失函数的超参数。