代码:https://github.com/vsitzmann/siren
看其中一个运行在图片上的例子experiment_scripts/train_img.py
这个例子实现的是论文中下面部分的例子:
A simple example: fitting an image. 考虑一个例子,即寻找一个能够以连续的方式参数化一个给定的离散图像 f 的函数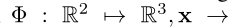
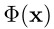 。图像定义一个与它们的RGB颜色
。图像定义一个与它们的RGB颜色 相关联的像素坐标
相关联的像素坐标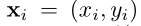 的数据集
的数据集 。唯一实施的约束是 Φ 应该在像素坐标上输出图像颜色,该约束仅依赖于Φ(与其任何导数无关)和,其表示形式为
。唯一实施的约束是 Φ 应该在像素坐标上输出图像颜色,该约束仅依赖于Φ(与其任何导数无关)和,其表示形式为 ,该约束可以转换成损失
,该约束可以转换成损失 。
。
在图1中,我们使用带有不同激活函数的可兼容的网络结构去拟合Φθ成一个自然图像。我们只对图像值进行监督实验,同时对梯度∇f 和 Laplacians∆f也进行了可视化。只有两种方法,即带有位置编码(P.E)[5]的ReLU网络和我们的SIREN,能够准确地表示ground truth图像f (x),而SIREN是唯一能够表示信号导数的网络。
即训练网络,能够输入图像的坐标信息,然后输出图像的像素信息,拟合一张图像
1.数据处理
使用的是skimage自带的拿相机的人的示例照片。查看下该照片:
#coding:utf-8
import skimage
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
img = skimage.data.camera() #这是个灰度图像,仅一张
print(img.shape) #(512, 512)
skimage.io.imsave('./camera_people.jpg',img)
img = skimage.data.chelsea() #这是个小猫的数据集,是彩色图像,仅一张
print(img.shape) #(300, 451, 3)
skimage.io.imsave('./cat.jpg',img)
返回图像:


dataio.py:
get_mgrid()函数:
import numpy as np
import torch
sidelen = 512
dim = 2
if isinstance(sidelen, int):
sidelen = dim * (sidelen,)
print(sidelen)
grid_1 = np.mgrid[:sidelen[0], :sidelen[1]]
print(grid_1.shape)
grid_2 = np.stack(grid_1, axis=-1)
print(grid_2.shape)
grid_3 = grid_2[None, ...].astype(np.float32)
print(grid_3.shape)
grid_4 = torch.Tensor(grid_3).view(-1, dim)
print(grid_4.shape)
返回:
(512, 512)
(2, 512, 512)
(512, 512, 2)
(1, 512, 512, 2)
torch.Size([262144, 2])
def get_mgrid(sidelen, dim=2):
'''Generates a flattened grid of (x,y,...) coordinates in a range of -1 to 1.'''
if isinstance(sidelen, int):
sidelen = dim * (sidelen,) #(512, 512)
if dim == 2:
pixel_coords = np.stack(np.mgrid[:sidelen[0], :sidelen[1]], axis=-1)[None, ...].astype(np.float32) #(1, 512, 512, 2)
# 此时数组的值在[0,511]的范围里,除以511变成[0,1]的范围
pixel_coords[0, :, :, 0] = pixel_coords[0, :, :, 0] / (sidelen[0] - 1)
pixel_coords[0, :, :, 1] = pixel_coords[0, :, :, 1] / (sidelen[1] - 1)
elif dim == 3:
pixel_coords = np.stack(np.mgrid[:sidelen[0], :sidelen[1], :sidelen[2]], axis=-1)[None, ...].astype(np.float32)
pixel_coords[..., 0] = pixel_coords[..., 0] / max(sidelen[0] - 1, 1)
pixel_coords[..., 1] = pixel_coords[..., 1] / (sidelen[1] - 1)
pixel_coords[..., 2] = pixel_coords[..., 2] / (sidelen[2] - 1)
else:
raise NotImplementedError('Not implemented for dim=%d' % dim)
pixel_coords -= 0.5
pixel_coords *= 2. # 这两部操作将数组中的值的范围变为[-1,1]
#最后构造得到一个网格,pixel_coords为对应的262144个(x,y)的坐标点
pixel_coords = torch.Tensor(pixel_coords).view(-1, dim) #torch.Size([262144, 2])
return pixel_coords
print(get_mgrid(512))
返回:
tensor([[-1.0000, -1.0000],
[-1.0000, -0.9961],
[-1.0000, -0.9922],
...,
[ 1.0000, 0.9922],
[ 1.0000, 0.9961],
[ 1.0000, 1.0000]])
出错:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
解决,添加:
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
测试使用:
#coding:utf-8
import numpy as np
import torch
from torch.utils.data import Dataset
from PIL import Image
import skimage
from torchvision.transforms import Resize, Compose, ToTensor, Normalize
import scipy.ndimage
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
def get_mgrid(sidelen, dim=2):
'''Generates a flattened grid of (x,y,...) coordinates in a range of -1 to 1.'''
if isinstance(sidelen, int):
sidelen = dim * (sidelen,) #(512, 512)
if dim == 2:
pixel_coords = np.stack(np.mgrid[:sidelen[0], :sidelen[1]], axis=-1)[None, ...].astype(np.float32) #(1, 512, 512, 2)
# 此时数组的值在[0,511]的范围里,除以511变成[0,1]的范围
pixel_coords[0, :, :, 0] = pixel_coords[0, :, :, 0] / (sidelen[0] - 1)
pixel_coords[0, :, :, 1] = pixel_coords[0, :, :, 1] / (sidelen[1] - 1)
elif dim == 3:
pixel_coords = np.stack(np.mgrid[:sidelen[0], :sidelen[1], :sidelen[2]], axis=-1)[None, ...].astype(np.float32)
pixel_coords[..., 0] = pixel_coords[..., 0] / max(sidelen[0] - 1, 1)
pixel_coords[..., 1] = pixel_coords[..., 1] / (sidelen[1] - 1)
pixel_coords[..., 2] = pixel_coords[..., 2] / (sidelen[2] - 1)
else:
raise NotImplementedError('Not implemented for dim=%d' % dim)
pixel_coords -= 0.5
pixel_coords *= 2. # 这两部操作将数组中的值的范围变为[-1,1]
#最后构造得到一个网格,pixel_coords为对应的262144个(x,y)的坐标点
pixel_coords = torch.Tensor(pixel_coords).view(-1, dim) #torch.Size([262144, 2])
return pixel_coords
# print(get_mgrid(512))
class Camera(Dataset):
def __init__(self, downsample_factor=1):
super().__init__()
self.downsample_factor = downsample_factor
self.img = Image.fromarray(skimage.data.camera()) #skimage自带的拿相机的人的照片
self.img_channels = 1
if downsample_factor > 1:
size = (int(512 / downsample_factor),) * 2
self.img_downsampled = self.img.resize(size, Image.ANTIALIAS)
def __len__(self):
return 1
def __getitem__(self, idx):
if self.downsample_factor > 1:
return self.img_downsampled
else:
return self.img
class Implicit2DWrapper(torch.utils.data.Dataset):
def __init__(self, dataset, sidelength=None, compute_diff=None):
if isinstance(sidelength, int):
sidelength = (sidelength, sidelength)
self.sidelength = sidelength
self.transform = Compose([
Resize(sidelength),
ToTensor(),
Normalize(torch.Tensor([0.5]), torch.Tensor([0.5]))
])
self.compute_diff = compute_diff
self.dataset = dataset
self.mgrid = get_mgrid(sidelength)
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
img = self.transform(self.dataset[idx])
if self.compute_diff == 'gradients':
img *= 1e1
gradx = scipy.ndimage.sobel(img.numpy(), axis=1).squeeze(0)[..., None]
grady = scipy.ndimage.sobel(img.numpy(), axis=2).squeeze(0)[..., None]
elif self.compute_diff == 'laplacian':
img *= 1e4
laplace = scipy.ndimage.laplace(img.numpy()).squeeze(0)[..., None]
elif self.compute_diff == 'all':
gradx = scipy.ndimage.sobel(img.numpy(), axis=1).squeeze(0)[..., None]
# print(gradx.shape) #(512, 512, 1)
grady = scipy.ndimage.sobel(img.numpy(), axis=2).squeeze(0)[..., None]
# print(grady.shape) #(512, 512, 1)
laplace = scipy.ndimage.laplace(img.numpy()).squeeze(0)[..., None]
# print(laplace.shape) #(512, 512, 1)
# print(img.shape) #torch.Size([1, 512, 512])
img = img.permute(1, 2, 0).view(-1, self.dataset.img_channels)
# print(img.shape) #torch.Size([262144, 1])
in_dict = {'idx': idx, 'coords': self.mgrid}
gt_dict = {'img': img}
if self.compute_diff == 'gradients':
gradients = torch.cat((torch.from_numpy(gradx).reshape(-1, 1),
torch.from_numpy(grady).reshape(-1, 1)),
dim=-1)
gt_dict.update({'gradients': gradients})
elif self.compute_diff == 'laplacian':
gt_dict.update({'laplace': torch.from_numpy(laplace).view(-1, 1)})
elif self.compute_diff == 'all':
gradients = torch.cat((torch.from_numpy(gradx).reshape(-1, 1),
torch.from_numpy(grady).reshape(-1, 1)),
dim=-1)
# print(gradients.shape) #torch.Size([262144, 2])
gt_dict.update({'gradients': gradients})
gt_dict.update({'laplace': torch.from_numpy(laplace).view(-1, 1)})
return in_dict, gt_dict
img_dataset = Camera()
coord_dataset = Implicit2DWrapper(img_dataset, sidelength=512, compute_diff='all')
in_dict, gt_dict = coord_dataset[0]
print(in_dict)
print(gt_dict)
print(in_dict['coords'].shape)
print(gt_dict['img'].shape)
print(gt_dict['gradients'].shape)
print(gt_dict['laplace'].shape)
返回:
{'idx': 0, 'coords': tensor([[-1.0000, -1.0000],
[-1.0000, -0.9961],
[-1.0000, -0.9922],
...,
[ 1.0000, 0.9922],
[ 1.0000, 0.9961],
[ 1.0000, 1.0000]])}
{'img': tensor([[ 0.2235],
[ 0.2314],
[ 0.2549],
...,
[-0.0510],
[-0.1137],
[-0.1294]]), 'gradients': tensor([[ 0.0000, 0.1255],
[-0.0314, 0.4706],
[-0.0941, 0.2196],
...,
[ 0.0000, -2.1333],
[-0.0000, -1.2549],
[-0.0000, -0.2510]]), 'laplace': tensor([[ 0.0078],
[ 0.0157],
[-0.0392],
...,
[ 0.0078],
[ 0.0471],
[ 0.0157]])}
torch.Size([262144, 2])
torch.Size([262144, 1])
torch.Size([262144, 2])
torch.Size([262144, 1])
2.使用模型
module.py
FCBlock:
MetaSequential( (0): MetaSequential( (0): BatchLinear(in_features=1, out_features=256, bias=True) (1): Sine() ) (1): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (2): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (3): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (4): MetaSequential( (0): BatchLinear(in_features=256, out_features=2, bias=True) ) )
SingleBVPNet():
SingleBVPNet( (image_downsampling): ImageDownsampling() (net): FCBlock( (net): MetaSequential( (0): MetaSequential( (0): BatchLinear(in_features=2, out_features=256, bias=True) (1): Sine() ) (1): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (2): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (3): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (4): MetaSequential( (0): BatchLinear(in_features=256, out_features=1, bias=True) ) ) ) )
3.损失函数
loss_functions.py
def image_mse(mask, model_output, gt): if mask is None: return {'img_loss': ((model_output['model_out'] - gt['img']) ** 2).mean()} else: return {'img_loss': (mask * (model_output['model_out'] - gt['img']) ** 2).mean()}
使用的是MSELoss
4.总结
这个简单的例子主要相关的代码是:
- experiment_scripts/train_img.py
- dataio.py
- modules.py
- loss_functions.py

大概将主要内容放在一起看看效果:


#coding:utf-8 import numpy as np import torch import torch.nn as nn from torch.utils.data import Dataset from PIL import Image import skimage # from skimage import io #有这个,就会报错OMP: Error #15 from torchvision.transforms import Resize, Compose, ToTensor, Normalize import scipy.ndimage from torch.utils.data import DataLoader from collections import OrderedDict from torchmeta.modules.utils import get_subdict ############################################################## 数据处理 ############################## import os os.environ['KMP_DUPLICATE_LIB_OK']='True' def get_mgrid(sidelen, dim=2): '''Generates a flattened grid of (x,y,...) coordinates in a range of -1 to 1.''' if isinstance(sidelen, int): sidelen = dim * (sidelen,) #(512, 512) if dim == 2: pixel_coords = np.stack(np.mgrid[:sidelen[0], :sidelen[1]], axis=-1)[None, ...].astype(np.float32) #(1, 512, 512, 2) # 此时数组的值在[0,511]的范围里,除以511变成[0,1]的范围 pixel_coords[0, :, :, 0] = pixel_coords[0, :, :, 0] / (sidelen[0] - 1) pixel_coords[0, :, :, 1] = pixel_coords[0, :, :, 1] / (sidelen[1] - 1) elif dim == 3: pixel_coords = np.stack(np.mgrid[:sidelen[0], :sidelen[1], :sidelen[2]], axis=-1)[None, ...].astype(np.float32) pixel_coords[..., 0] = pixel_coords[..., 0] / max(sidelen[0] - 1, 1) pixel_coords[..., 1] = pixel_coords[..., 1] / (sidelen[1] - 1) pixel_coords[..., 2] = pixel_coords[..., 2] / (sidelen[2] - 1) else: raise NotImplementedError('Not implemented for dim=%d' % dim) pixel_coords -= 0.5 pixel_coords *= 2. # 这两部操作将数组中的值的范围变为[-1,1] #最后构造得到一个网格,pixel_coords为对应的262144个(x,y)的坐标点 pixel_coords = torch.Tensor(pixel_coords).view(-1, dim) #torch.Size([262144, 2]) return pixel_coords class Camera(Dataset): def __init__(self, downsample_factor=1): super().__init__() self.downsample_factor = downsample_factor self.img = Image.fromarray(skimage.data.camera()) #skimage自带的拿相机的人的照片 self.img_channels = 1 if downsample_factor > 1: size = (int(512 / downsample_factor),) * 2 self.img_downsampled = self.img.resize(size, Image.ANTIALIAS) def __len__(self): return 1 def __getitem__(self, idx): if self.downsample_factor > 1: return self.img_downsampled else: return self.img class Implicit2DWrapper(torch.utils.data.Dataset): def __init__(self, dataset, sidelength=None, compute_diff=None): if isinstance(sidelength, int): sidelength = (sidelength, sidelength) self.sidelength = sidelength self.transform = Compose([ Resize(sidelength), ToTensor(), Normalize(torch.Tensor([0.5]), torch.Tensor([0.5])) ]) self.compute_diff = compute_diff self.dataset = dataset self.mgrid = get_mgrid(sidelength) def __len__(self): return len(self.dataset) def __getitem__(self, idx): img = self.transform(self.dataset[idx]) # self.dataset[idx].save('./camera_people_2.jpg') if self.compute_diff == 'gradients': img *= 1e1 gradx = scipy.ndimage.sobel(img.numpy(), axis=1).squeeze(0)[..., None] grady = scipy.ndimage.sobel(img.numpy(), axis=2).squeeze(0)[..., None] elif self.compute_diff == 'laplacian': img *= 1e4 laplace = scipy.ndimage.laplace(img.numpy()).squeeze(0)[..., None] elif self.compute_diff == 'all': gradx = scipy.ndimage.sobel(img.numpy(), axis=1).squeeze(0)[..., None] # print(gradx.shape) #(512, 512, 1) grady = scipy.ndimage.sobel(img.numpy(), axis=2).squeeze(0)[..., None] # print(grady.shape) #(512, 512, 1) laplace = scipy.ndimage.laplace(img.numpy()).squeeze(0)[..., None] # print(laplace.shape) #(512, 512, 1) # print(img.shape) #torch.Size([1, 512, 512]) #将图像的每一个像素值展开得到262144个像素值 img = img.permute(1, 2, 0).view(-1, self.dataset.img_channels) # print(img.shape) #torch.Size([262144, 1]) in_dict = {'idx': idx, 'coords': self.mgrid} gt_dict = {'img': img} if self.compute_diff == 'gradients': gradients = torch.cat((torch.from_numpy(gradx).reshape(-1, 1), torch.from_numpy(grady).reshape(-1, 1)), dim=-1) gt_dict.update({'gradients': gradients}) elif self.compute_diff == 'laplacian': gt_dict.update({'laplace': torch.from_numpy(laplace).view(-1, 1)}) elif self.compute_diff == 'all': gradients = torch.cat((torch.from_numpy(gradx).reshape(-1, 1), torch.from_numpy(grady).reshape(-1, 1)), dim=-1) # print(gradients.shape) #torch.Size([262144, 2]) gt_dict.update({'gradients': gradients}) gt_dict.update({'laplace': torch.from_numpy(laplace).view(-1, 1)}) return in_dict, gt_dict img_dataset = Camera() coord_dataset = Implicit2DWrapper(img_dataset, sidelength=512, compute_diff='all') # in_dict, gt_dict = coord_dataset[3] # print(in_dict) # print(gt_dict) # print(in_dict['coords'].shape) # print(gt_dict['img'].shape) # print(gt_dict['gradients'].shape) # print(gt_dict['laplace'].shape) #num_workers=0说明使用单进程 dataloader = DataLoader(coord_dataset, shuffle=True, batch_size=1, pin_memory=True, num_workers=0) ############################################################## 数据处理 ############################## ############################################################## 使用的模型 ############################## from torchmeta.modules import (MetaModule, MetaSequential) class Sine(nn.Module): def __init(self): super().__init__() def forward(self, input): # See paper sec. 3.2, final paragraph, and supplement Sec. 1.5 for discussion of factor 30 return torch.sin(30 * input) def sine_init(m): with torch.no_grad(): if hasattr(m, 'weight'): num_input = m.weight.size(-1) # See supplement Sec. 1.5 for discussion of factor 30 m.weight.uniform_(-np.sqrt(6 / num_input) / 30, np.sqrt(6 / num_input) / 30) def first_layer_sine_init(m): with torch.no_grad(): if hasattr(m, 'weight'): num_input = m.weight.size(-1) # See paper sec. 3.2, final paragraph, and supplement Sec. 1.5 for discussion of factor 30 m.weight.uniform_(-1 / num_input, 1 / num_input) def init_weights_normal(m): if type(m) == BatchLinear or type(m) == nn.Linear: if hasattr(m, 'weight'): nn.init.kaiming_normal_(m.weight, a=0.0, nonlinearity='relu', mode='fan_in') def init_weights_xavier(m): if type(m) == BatchLinear or type(m) == nn.Linear: if hasattr(m, 'weight'): nn.init.xavier_normal_(m.weight) def init_weights_selu(m): if type(m) == BatchLinear or type(m) == nn.Linear: if hasattr(m, 'weight'): num_input = m.weight.size(-1) nn.init.normal_(m.weight, std=1 / math.sqrt(num_input)) def init_weights_elu(m): if type(m) == BatchLinear or type(m) == nn.Linear: if hasattr(m, 'weight'): num_input = m.weight.size(-1) nn.init.normal_(m.weight, std=math.sqrt(1.5505188080679277) / math.sqrt(num_input)) # 重新写了下nn.Linear层 class BatchLinear(nn.Linear, MetaModule): '''A linear meta-layer that can deal with batched weight matrices and biases, as for instance output by a hypernetwork.''' __doc__ = nn.Linear.__doc__ def forward(self, input, params=None): if params is None: params = OrderedDict(self.named_parameters()) #得到nn.Linear的参数 bias = params.get('bias', None) weight = params['weight'] # print('BatchLinear list :', [i for i in range(len(weight.shape) - 2)]) #[] # 不知道这个跟nn.Linear层的原本实现有什么差别 # output = input.matmul(weight.t()) # output += bias # print('weight.shape before : ', weight.shape) #torch.Size([256, 2]) print('input.shape : ', input.shape) #torch.Size([1, 262144, 2]) # print('weight permute :', weight.permute(*[i for i in range(len(weight.shape) - 2)], -1, -2).shape)#相当于weight的转置操作 # 其实就是x*(A转置) + b 操作 output = input.matmul(weight.permute(*[i for i in range(len(weight.shape) - 2)], -1, -2)) # print('weight.shape after : ', weight.shape) #torch.Size([256, 2]) print('output.shape : ', output.shape) #torch.Size([1, 262144, 256]) output += bias.unsqueeze(-2) return output class ImageDownsampling(nn.Module): '''Generate samples in u,v plane according to downsampling blur kernel''' def __init__(self, sidelength, downsample=False): super().__init__() if isinstance(sidelength, int): self.sidelength = (sidelength, sidelength) else: self.sidelength = sidelength if self.sidelength is not None: # self.sidelength = torch.Tensor(self.sidelength).cuda().float() self.sidelength = torch.Tensor(self.sidelength).float() else: assert downsample is False self.downsample = downsample def forward(self, coords): if self.downsample: return coords + self.forward_bilinear(coords) else: return coords def forward_box(self, coords): return 2 * (torch.rand_like(coords) - 0.5) / self.sidelength def forward_bilinear(self, coords): Y = torch.sqrt(torch.rand_like(coords)) - 1 #torch.rand_like(coords)返回跟coords的tensor一样size的0-1随机数 Z = 1 - torch.sqrt(torch.rand_like(coords)) b = torch.rand_like(coords) < 0.5 Q = (b * Y + ~b * Z) / self.sidelength return Q class FCBlock(MetaModule): '''A fully connected neural network that also allows swapping out the weights when used with a hypernetwork. Can be used just as a normal neural network though, as well. ''' def __init__(self, in_features, out_features, num_hidden_layers, hidden_features, outermost_linear=False, nonlinearity='relu', weight_init=None): super().__init__() self.first_layer_init = None # Dictionary that maps nonlinearity name to the respective function, initialization, and, if applicable, # special first-layer initialization scheme nls_and_inits = {'sine':(Sine(), sine_init, first_layer_sine_init), 'relu':(nn.ReLU(inplace=True), init_weights_normal, None), 'sigmoid':(nn.Sigmoid(), init_weights_xavier, None), 'tanh':(nn.Tanh(), init_weights_xavier, None), 'selu':(nn.SELU(inplace=True), init_weights_selu, None), 'softplus':(nn.Softplus(), init_weights_normal, None), 'elu':(nn.ELU(inplace=True), init_weights_elu, None)} nl, nl_weight_init, first_layer_init = nls_and_inits[nonlinearity] if weight_init is not None: # Overwrite weight init if passed self.weight_init = weight_init else: self.weight_init = nl_weight_init self.net = [] self.net.append(MetaSequential( #BatchLinear和一个sine层 BatchLinear(in_features, hidden_features), nl )) for i in range(num_hidden_layers): self.net.append(MetaSequential( BatchLinear(hidden_features, hidden_features), nl )) if outermost_linear: self.net.append(MetaSequential(BatchLinear(hidden_features, out_features))) else: self.net.append(MetaSequential( BatchLinear(hidden_features, out_features), nl )) # 如果使用的是sine,第一层的初始化和后面层的初始化是不同的 self.net = MetaSequential(*self.net) if self.weight_init is not None: self.net.apply(self.weight_init) if first_layer_init is not None: # Apply special initialization to first layer, if applicable. self.net[0].apply(first_layer_init) def forward(self, coords, params=None, **kwargs): if params is None: params = OrderedDict(self.named_parameters()) output = self.net(coords, params=get_subdict(params, 'net')) return output def forward_with_activations(self, coords, params=None, retain_grad=False): '''Returns not only model output, but also intermediate activations.''' if params is None: params = OrderedDict(self.named_parameters()) activations = OrderedDict() x = coords.clone().detach().requires_grad_(True) activations['input'] = x for i, layer in enumerate(self.net): subdict = get_subdict(params, 'net.%d' % i) for j, sublayer in enumerate(layer): if isinstance(sublayer, BatchLinear): x = sublayer(x, params=get_subdict(subdict, '%d' % j)) else: x = sublayer(x) if retain_grad: x.retain_grad() activations['_'.join((str(sublayer.__class__), "%d" % i))] = x return activations class SingleBVPNet(MetaModule): '''A canonical representation network for a BVP.''' def __init__(self, out_features=1, type='sine', in_features=2, mode='mlp', hidden_features=256, num_hidden_layers=3, **kwargs): super().__init__() self.mode = mode if self.mode == 'rbf': self.rbf_layer = RBFLayer(in_features=in_features, out_features=kwargs.get('rbf_centers', 1024)) in_features = kwargs.get('rbf_centers', 1024) elif self.mode == 'nerf': self.positional_encoding = PosEncodingNeRF(in_features=in_features, sidelength=kwargs.get('sidelength', None), fn_samples=kwargs.get('fn_samples', None), use_nyquist=kwargs.get('use_nyquist', True)) in_features = self.positional_encoding.out_dim self.image_downsampling = ImageDownsampling(sidelength=kwargs.get('sidelength', None), downsample=kwargs.get('downsample', False)) self.net = FCBlock(in_features=in_features, out_features=out_features, num_hidden_layers=num_hidden_layers, hidden_features=hidden_features, outermost_linear=True, nonlinearity=type) print(self) def forward(self, model_input, params=None): if params is None: params = OrderedDict(self.named_parameters()) # Enables us to compute gradients w.r.t. coordinates coords_org = model_input['coords'].clone().detach().requires_grad_(True) coords = coords_org # various input processing methods for different applications if self.image_downsampling.downsample: coords = self.image_downsampling(coords) if self.mode == 'rbf': coords = self.rbf_layer(coords) elif self.mode == 'nerf': coords = self.positional_encoding(coords) output = self.net(coords, get_subdict(params, 'net')) return {'model_in': coords_org, 'model_out': output} # 该模型的作用就是输入(512,512)图像对应的大小为[batch_size, 262144, 2]像素坐标model_input['coords'] # 输出对应的大小为[batch_size, 262144, 1]的像素值,output['model_out'] # SingleBVPNet模型就是拟合的带参数theta的函数 # 最后用损失MSE去计算得到的像素值output['model_out']和真正的像素值gt['img']之间的误差 # 减少该误差来训练网络 model = SingleBVPNet(type='sine', mode='mlp', sidelength=(512, 512)) # for i in model.children(): # print(i) # 这里的输入只有一张图,即那个照相的男人 # 拟合网络生成这张图 for step, (model_input, gt) in enumerate(dataloader): print('-'*30) print('step : ', step) print(model_input['coords'].shape) print(gt['img'].shape) output = model(model_input) print('model in : ', output['model_in'].shape) print('model out : ', output['model_out'].shape)
返回:
SingleBVPNet( (image_downsampling): ImageDownsampling() (net): FCBlock( (net): MetaSequential( (0): MetaSequential( (0): BatchLinear(in_features=2, out_features=256, bias=True) (1): Sine() ) (1): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (2): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (3): MetaSequential( (0): BatchLinear(in_features=256, out_features=256, bias=True) (1): Sine() ) (4): MetaSequential( (0): BatchLinear(in_features=256, out_features=1, bias=True) ) ) ) ) ------------------------------ step : 0 torch.Size([1, 262144, 2]) torch.Size([1, 262144, 1]) input.shape : torch.Size([1, 262144, 2]) output.shape : torch.Size([1, 262144, 256]) input.shape : torch.Size([1, 262144, 256]) output.shape : torch.Size([1, 262144, 256]) input.shape : torch.Size([1, 262144, 256]) output.shape : torch.Size([1, 262144, 256]) input.shape : torch.Size([1, 262144, 256]) output.shape : torch.Size([1, 262144, 256]) input.shape : torch.Size([1, 262144, 256]) output.shape : torch.Size([1, 262144, 1]) model in : torch.Size([1, 262144, 2]) model out : torch.Size([1, 262144, 1])
可见sine激活函数实现使用:
# 重新写了下nn.Linear层 class BatchLinear(nn.Linear, MetaModule): '''A linear meta-layer that can deal with batched weight matrices and biases, as for instance output by a hypernetwork.''' __doc__ = nn.Linear.__doc__ def forward(self, input, params=None): if params is None: params = OrderedDict(self.named_parameters()) #得到nn.Linear的参数 bias = params.get('bias', None) weight = params['weight'] # print('BatchLinear list :', [i for i in range(len(weight.shape) - 2)]) #[] # 不知道这个跟nn.Linear层的原本实现有什么差别 # output = input.matmul(weight.t()) # output += bias # print('weight.shape before : ', weight.shape) #torch.Size([256, 2]) print('input.shape : ', input.shape) #torch.Size([1, 262144, 2]) # print('weight permute :', weight.permute(*[i for i in range(len(weight.shape) - 2)], -1, -2).shape)#相当于weight的转置操作 # 其实就是x*(A转置) + b 操作 output = input.matmul(weight.permute(*[i for i in range(len(weight.shape) - 2)], -1, -2)) # print('weight.shape after : ', weight.shape) #torch.Size([256, 2]) print('output.shape : ', output.shape) #torch.Size([1, 262144, 256]) # print('bias before:', bias.shape) #torch.Size([256]) # print('bias after:', bias.unsqueeze(-2).shape) output += bias.unsqueeze(-2) #torch.Size([1, 256]) return output
参数w(weight)和b(bias)都在该层,得到sine()的输入wTx+b
然后对BatchLinear的输出wTx+b使用sine()激活函数:
class Sine(nn.Module): def __init(self): super().__init__() def forward(self, input): # See paper sec. 3.2, final paragraph, and supplement Sec. 1.5 for discussion of factor 30 return torch.sin(30 * input) #w0=30 def sine_init(m): with torch.no_grad(): if hasattr(m, 'weight'): num_input = m.weight.size(-1) #num_input即in_features_num # See supplement Sec. 1.5 for discussion of factor 30 m.weight.uniform_(-np.sqrt(6 / num_input) / 30, np.sqrt(6 / num_input) / 30) def first_layer_sine_init(m): with torch.no_grad(): if hasattr(m, 'weight'): num_input = m.weight.size(-1) # See paper sec. 3.2, final paragraph, and supplement Sec. 1.5 for discussion of factor 30 m.weight.uniform_(-1 / num_input, 1 / num_input)