On First-Order Meta-Learning Algorithms
Abstract
本文考虑元学习问题,其中存在任务分布,我们希望得到一个当面对一个从这个分布中采样的以前未被发现(即以前训练的时候没使用过的)的任务时,也能表现良好的agent(即学习很快)。我们分析了一组学习参数初始化的算法,这些算法可以在新的任务上快速微调,仅使用一阶导数进行元学习更新。这一族包含和推广了一阶MAML,这是忽略二阶导数得到的MAML的近似。它还包括Reptile,即我们在这里介绍的一个新算法,它通过重复采样一个任务,对它进行训练,并将初始化移动到该任务的训练权重。我们扩展了Finn等人的结果,表明一阶元学习算法在一些已确立的few-shot分类基准上表现良好,我们提供了理论分析,旨在理解这些算法的工作原理。
1 Introduction
虽然机器学习系统已经在许多任务上超越了人类,但它们通常需要多得多的数据才能达到相同的性能水平。例如,Schmidt等人[17,15]的研究表明,人类主体可以根据一些样本图像识别新的对象类别。Lake等人[12]指出,在Frostbite的Atari游戏中,人类新手在15分钟后就能在游戏中取得显著进展,但double-dueling-DQN [19]需要超过1000倍的经验才能获得相同的分数。
把人类比作从头开始学习的算法是不完全公平的,因为人类在完成任务时,大脑和DNA中已经编码了大量的先验知识。他们不是从零开始学习,而是对一组已有的技能进行微调和重组。上述由Tenenbaum和他的合作者所引用的工作表明,人类的快速学习能力可以被解释为贝叶斯推理,而开发具有人类水平学习速度的算法的关键是使我们的算法更加贝叶斯。然而,在实践中,开发(从第一原理)利用深度神经网络并且在计算上可行的贝叶斯机器学习算法是具有挑战性的。
元学习是最近出现的一种从少量数据中学习的方法。元学习并不是试图模仿贝叶斯推理(这可能是难以计算的),而是寻求使用任务数据集直接优化快速学习算法。具体地说,我们假设可以访问任务分布,例如,每个任务都是一个分类问题。从这个分布中,我们对任务的训练集和测试集进行采样。我们的算法接受训练集,它必须产生一个在测试集上平均表现良好的agent。由于每个任务对应一个学习问题,因此在一个任务上表现良好就对应着快速学习。
各种不同的元学习方法已经被提出,每种方法都有其优缺点。其中一种方法是将学习算法编码在递归网络的权值中,但在测试时不进行梯度下降。该方法是由Hochreiter等人[8]提出的,他们使用LSTMs进行下一步预测,并在近期进行了一系列后续工作,例如,Santoro等人[16]进行few-shot分类,Duan等人[3]进行POMDP设置。
第二种方法是学习网络的初始化,然后在测试时对新任务进行微调。这种方法的一个经典示例是使用大型数据集(例如ImageNet[2])进行预训练,并对较小的数据集进行微调(例如不同种类鸟类[20]的数据集)。然而,这种经典的预训练方法并不能保证学习有利于微调的初始化,而且要获得良好的性能,需要特别的技巧。最近,Finn等人[4]提出了一种称为MAML的算法,该算法通过在微调过程微分来直接优化了与初始化相关的性能。在这种方法中,即使在接收到样本外数据时,学习者也会采用合理的基于梯度的学习算法,从而使其比基于RNN的方法[5]泛化得更好。另一方面,由于MAML需要在优化过程中进行微分,因此它不适用于需要在测试时执行大量梯度步骤的问题。作者还提出了一种称为一阶MAML (FOMAML)的变体,它的定义是忽略二阶导数项,避免了这个问题,但代价是丢失一些梯度信息。然而,令人惊讶的是,他们发现在Mini-ImageNet数据集[18]上,FOMAML的表现几乎和MAML一样好。(之前的元学习[1,13]的工作就预示了这个结果,在通过梯度下降进行微分时忽略了二阶导数,没有不良影响。)在这项工作中,我们在此基础上进行了扩展,并探索了基于一阶梯度信息的元学习算法的潜力,这是出于对那些使用依赖于高阶梯度(如全MAML)的技术过于繁琐的问题的潜在适用性。
我们的贡献如下:
- 我们指出,一阶MAML[4]的实现比在本文之前被广泛认为的要简单。
- 我们介绍了Reptile,一个与FOMAML密切相关的算法,它同样易于实现。Reptile与联合训练(即训练以减少训练任务的预期损失)十分相似,它作为一种元学习算法,尤其令人惊讶。与FOMAML不同的是,Reptile不需要为每个任务进行训练测试分割,这可能会使它在某些情况下成为更自然的选择。它也与[7]的fast weight/slow weight的旧观念有关。
- 我们提供了一个适用于一阶MAML和Reptile的理论分析,表明它们都优化了任务内的泛化。
- 基于对Mini-ImageNet[18]和Omniglot[11]数据集的经验评估,我们为最佳实践提供了一些见解。
2 Meta-Learning an Initialization
我们考虑了MAML[4]的优化问题:找到一组初始参数Φ,使得对于一个具有相应的损失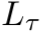 的随机采样的任务
的随机采样的任务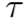 ,在k次更新后,学习者的损失较小。那就是:
,在k次更新后,学习者的损失较小。那就是:

其中![]() 是使用从任务中采样的数据更新Φ参数k次的操作符。在few-shot学习中,U对应于在从任务中采样的数据batches中实现梯度下降或Adam[10]
是使用从任务中采样的数据更新Φ参数k次的操作符。在few-shot学习中,U对应于在从任务中采样的数据batches中实现梯度下降或Adam[10]
MAML解决了方程(1)的一个版本,它基于额外的假设:对于给定的任务,内循环优化使用训练样本A,而损失使用测试样本B计算。这样,MAML优化泛化,类似于交叉验证。省略上标k,我们把它记为:
![]()
MAML的工作方式是通过随机梯度下降来优化这个损失,即如下的计算:
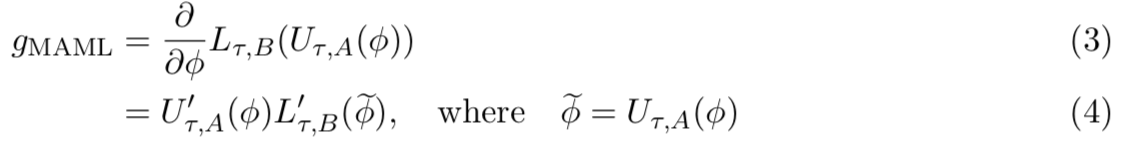
在等式(4)中,![]() 是更新操作
是更新操作![]() 的Jacobian矩阵。
的Jacobian矩阵。![]() 对应于添加一系列梯度向量到初始向量中,即
对应于添加一系列梯度向量到初始向量中,即![]() 。(在Adam中,梯度也按元素重新调整,但这不会改变结论。)一阶MAML(FOMAML)将这些梯度(二阶)看作常量,然而,它使用恒等操作来替换Jacobian
。(在Adam中,梯度也按元素重新调整,但这不会改变结论。)一阶MAML(FOMAML)将这些梯度(二阶)看作常量,然而,它使用恒等操作来替换Jacobian ![]() 。因此,FOMAML在外循环优化中使用的梯度是
。因此,FOMAML在外循环优化中使用的梯度是![]() 。因此FOMAML能使用特别简单的方法来实现:(1)采样任务;(2)使用更新操作符,产生
。因此FOMAML能使用特别简单的方法来实现:(1)采样任务;(2)使用更新操作符,产生![]() ,这是在训练集A上得到的;(3)计算在
,这是在训练集A上得到的;(3)计算在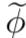 的梯度
的梯度![]() ,这是在测试集B上得到的;(4)将gFOMAML添加到外循环操作器中,更新参数
,这是在测试集B上得到的;(4)将gFOMAML添加到外循环操作器中,更新参数
3 Reptile
在本节中,我们描述了一个新的一阶基于梯度的元学习算法,称为Reptile。和MAML一样,Reptile学习神经网络模型参数的初始化,这样当我们在测试时优化这些参数时,学习是快速的 —— 即该模型从测试任务的少量示例中归纳而来。Reptile算法如下:

该方法与MAML的不同主要在于最后一步更新Φ上
MAML的训练可以分为两个层次:内层优化和外层优化,内层优化就与普通的训练一样,假设网络初始参数为θ0,在数据集A(训练数据)上采用SGD的方式进行训练后得到参数θ′。如果是普通的训练,那么就会接着采样一个数据集B(测试数据),然后以θ′作为初始参数继续训练了。MAML同样采集一个数据集B,然后用在数据集A上训练得到的模型fθ′处理数据集B上的样本,并计算损失。不同的是,MAML利用该损失计算得到的梯度对θ0进行更新:
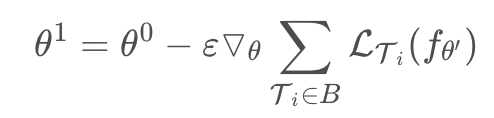
也就是说MAML的目标是训练得到一个好的初始化参数θ,使其能够在处理其他任务时很快的收敛到一个较好的结果。在梯度计算过程中会涉及到二阶导数计算,MAML利用一阶导数近似方法(FOMAML)进行处理,发现结果相差并不大,但计算量会减少很多
回到本文,本文提出的算法就是在FOMAML,进一步简化参数更新的方式,甚至连损失梯度都不需要计算了,直接利用θ0−θ′(即下面的![]() )作为梯度对参数进行更新,即:
)作为梯度对参数进行更新,即:
![]()
可能有人会觉得这样做,不是相当于退化成普通的训练过程了吗,因为θ′还是利用SGD方式得到的,然后让θ0沿着θ0−θ′的方向更新,就得到θ1。如果说在训练数据集A中只有一个训练样本,或者说只经过一个batch的训练,那么本文的算法的确会退化为普通的SGD训练,但如果每个数据集都进行不止一个Batch的训练,二者就不相同了。
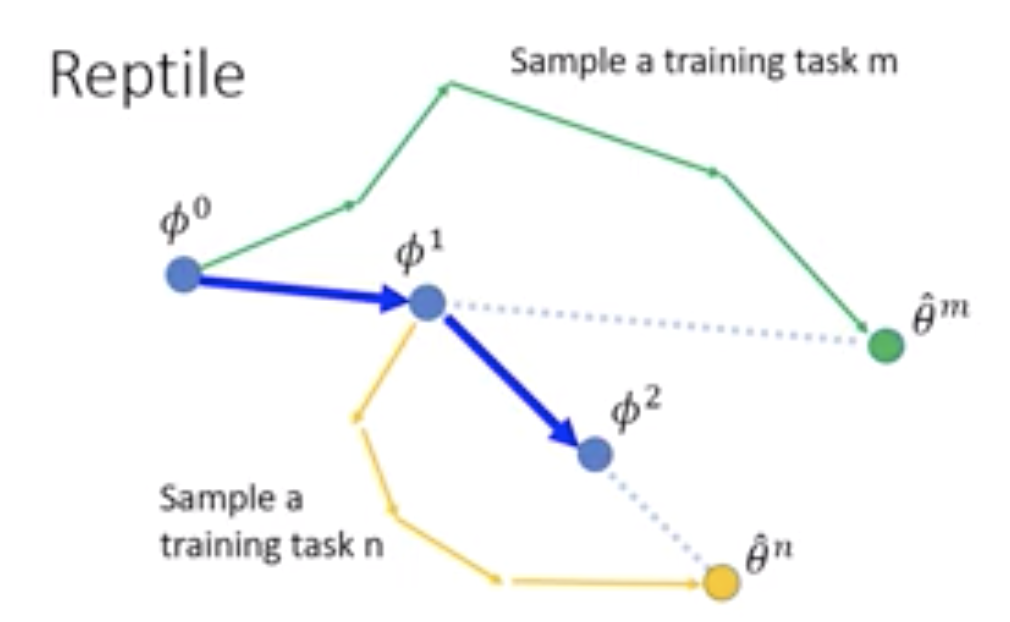
如下图所示:
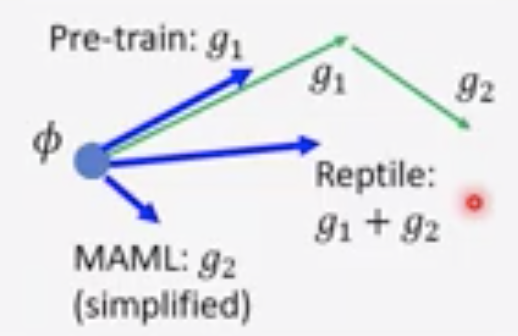
如果k=0,那么Reptile的确就等于普通的SGD训练了
在最后一步,不是简单地在![]() 方向更新Φ,我们将
方向更新Φ,我们将![]() 看作一个梯度,并将其插入如Adam[10]的自适应算法中。(实际上,我们将在Section 5.1中讨论,将Reptile梯度定义为
看作一个梯度,并将其插入如Adam[10]的自适应算法中。(实际上,我们将在Section 5.1中讨论,将Reptile梯度定义为![]() 会更自然,其中α是使用在SGD操作中的步长。)我们还定义了该算法的并行或batch版本,能在每个迭代中评估n个任务并更新初始化为:
会更自然,其中α是使用在SGD操作中的步长。)我们还定义了该算法的并行或batch版本,能在每个迭代中评估n个任务并更新初始化为:

其中![]() ,是第i个任务的更新参数
,是第i个任务的更新参数
该算法看起来与在期望损失![]() 上联合训练极其相似。甚至,如果我们定义U为一步的梯度下降(k=1),那么该算法对应于在期望损失上的随机梯度下降:
上联合训练极其相似。甚至,如果我们定义U为一步的梯度下降(k=1),那么该算法对应于在期望损失上的随机梯度下降:

然而,如果我们在局部最小化中执行多个梯度更新(k>1),那么该期望更新![]() 并不对应于在期望损失
并不对应于在期望损失![]() 上梯度下降一步(即当k>1时,U的期望更新将不等于损失函数期望更新,而是将包含损失函数的二次甚至更高阶微分项,Reptile的收敛点与最小化E(L)不同)。相反,该更新包含来自的二阶和更高阶导数的重要部分,如我们将在Section 5.1中分析的一样。甚至,Reptile收敛到了一个与最小的预期损失
上梯度下降一步(即当k>1时,U的期望更新将不等于损失函数期望更新,而是将包含损失函数的二次甚至更高阶微分项,Reptile的收敛点与最小化E(L)不同)。相反,该更新包含来自的二阶和更高阶导数的重要部分,如我们将在Section 5.1中分析的一样。甚至,Reptile收敛到了一个与最小的预期损失![]() 十分不同的结果
十分不同的结果
其他部分如步长参数ε和任务采样,Reptile的batched版本都与SimuParallelSGD[21]算法相似。SimuParallelSGD是一个communication-efficient的分布式优化方法,其中worker在本地进行梯度更新,且不经常平均他们的参数,而不是使用平均梯度的标准方法。
4 Case Study: One-Dimensional Sine Wave Regression
作为一个简单的案例研究,让我们考虑一维正弦波回归问题,它是对Finn等人[4]做了一些修改。这个问题是有指导意义的,因为通过设计,联合训练不能学习一个非常有用的初始化;然而,元学习方法可以。
- 任务
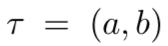 使用正弦波函数
使用正弦波函数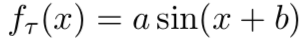 的振幅a和相位b来定义。通过采样
的振幅a和相位b来定义。通过采样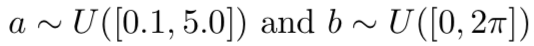 得到任务分布
得到任务分布 - 采样p个点
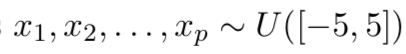
- learner找到
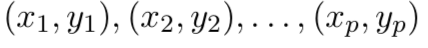 并预测整个函数f(x)
并预测整个函数f(x) - 损失是在整个[-5,5]间隔中使用的L2损失
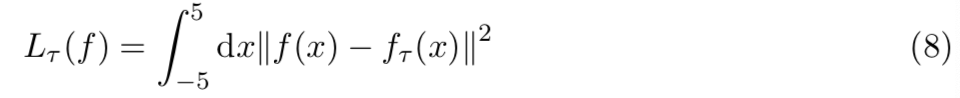
我们用50个等距点x来计算这个积分
首先注意到由于随机相位b,平均函数在任何地方都是0,即![]() 。因此在期望损失
。因此在期望损失![]() 上训练是无用的,因为损失会使用零函数f(x) = 0来最小化
上训练是无用的,因为损失会使用零函数f(x) = 0来最小化
另一方面,MAML和Reptile给了我们在任务上训练前的输出近似为f(x) = 0的初始化,但是在采样点![]() 上训练后的网络的内部特征表征近似于目标函数
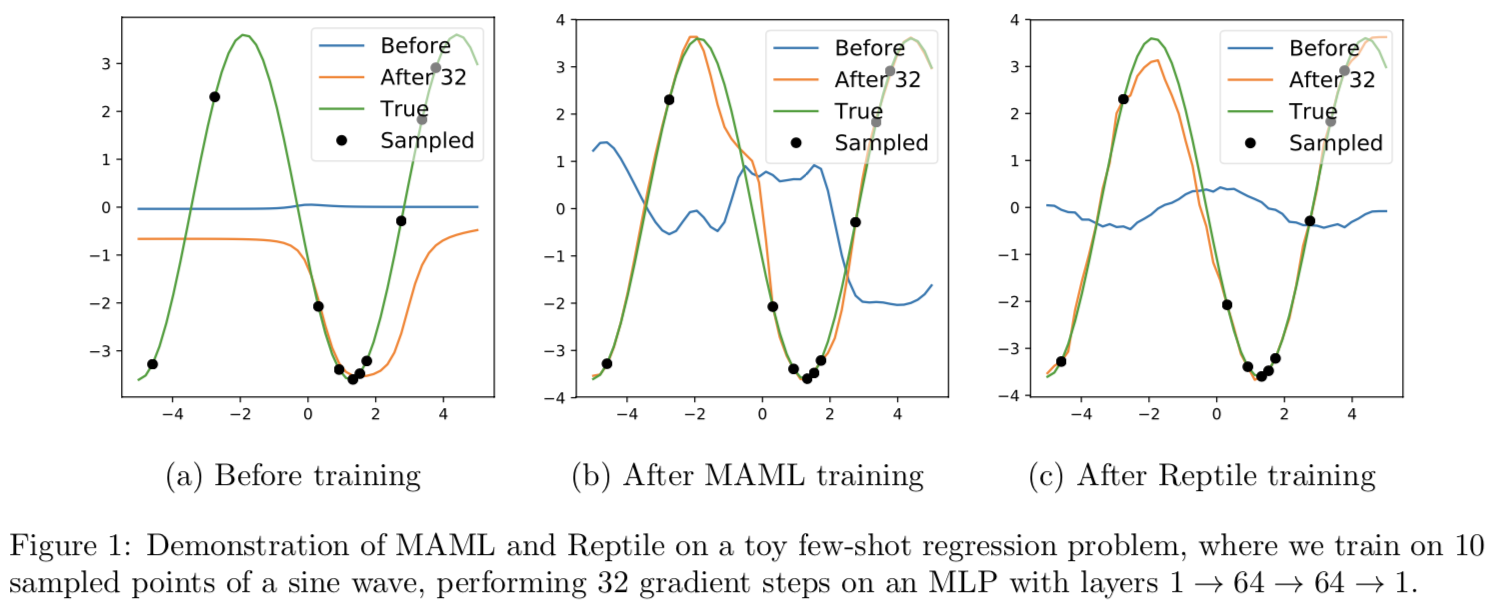
上训练后的网络的内部特征表征近似于目标函数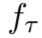 。这个学习过程在下图中展示。从图1可以看出,经过Reptile训练后,网络可以快速收敛到一个采样的正弦波,并推断出远离采样点的值。作为比较,我们还展示了MAML和一个随机初始化的网络在同一任务上的行为。
。这个学习过程在下图中展示。从图1可以看出,经过Reptile训练后,网络可以快速收敛到一个采样的正弦波,并推断出远离采样点的值。作为比较,我们还展示了MAML和一个随机初始化的网络在同一任务上的行为。
5 Analysis
在这个部分,我们提供了两个可替换的有关为什么Reptile能够运作的解释
5.1 Leading Order Expansion of the Update
在这里,我们将使用泰勒级数展开来近似Reptile和MAML执行的更新。我们将说明这两种算法包含相同的主导阶项:第一个项最小化预期损失(联合训练),第二个和更有趣的项最大化任务内泛化。具体来说,它最大化了来自同一任务的不同小批量的梯度之间的内积。如果不同batches的梯度有正的内积,那么在一个batches上采取的梯度step可以改善另一个batches的性能。
与MAML的讨论和分析不同,我们不考虑每个任务的训练集和测试集;相反,我们只假设每个任务给我们一个k个损失函数序列L1,L2,…,Lk;例如,不同minibatches的分类损失。我们将使用以下定义:

k个损失函数序列L1,L2,…,Lk表示的是k个steps求得的损失,比如一开始参数为Φ1,然后经过一个step,参数变为Φ2,此时对应的损失为L2;再经过一次step,参数变为Φ3,此时对应的损失为L3;...; 经过k-1次后参数就变为Φk,此时对应的损失为Lk。
首先计算如下带有![]() 的SGD梯度:
的SGD梯度:
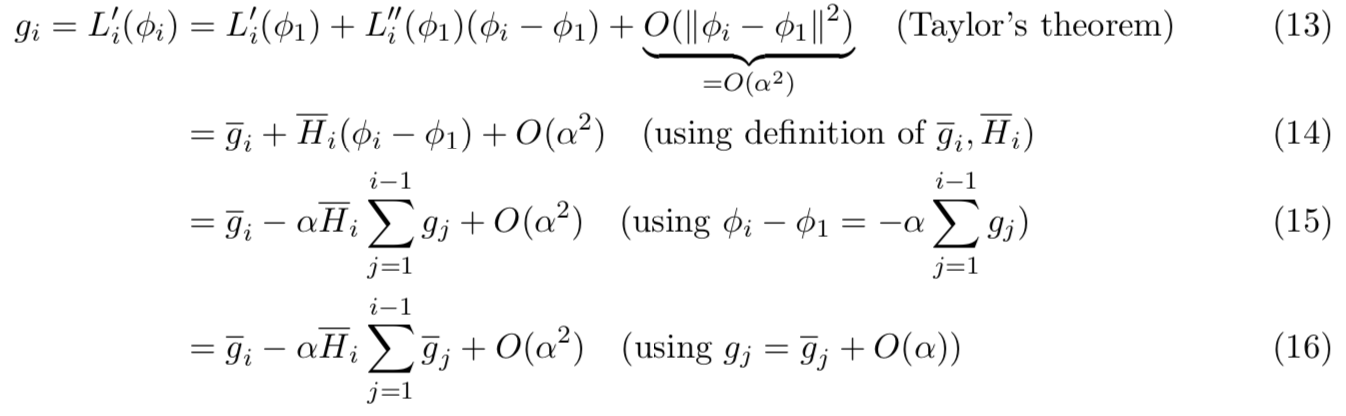
这个式子的作用就是如何将参数为Φi的一阶损失的计算变为由Φ1表示的式子,说明SGD是如何计算的梯度,得到具有一阶和二阶的式子
这一部分就是batch_size个任务训练数据如果使用SGD计算梯度的过程
接下来,我们将粗略估计MAML的梯度。定义![]() 为更新minibatch i的参数向量的操作符:
为更新minibatch i的参数向量的操作符:![]()

这一部分表示的是在测试数据上训练,全局更新参数的步骤
这表示的是在训练某个任务时,会训练K个steps,一个step对应一个minibatch,然后更新一次参数,这样一步步运行第k个step计算的损失就是Lk(Φk),然后该损失对Φ1求导,这样就能够得到训练这个任务的梯度更新,即从初始化参数Φ1的变化
接下来则是解释主导阶:
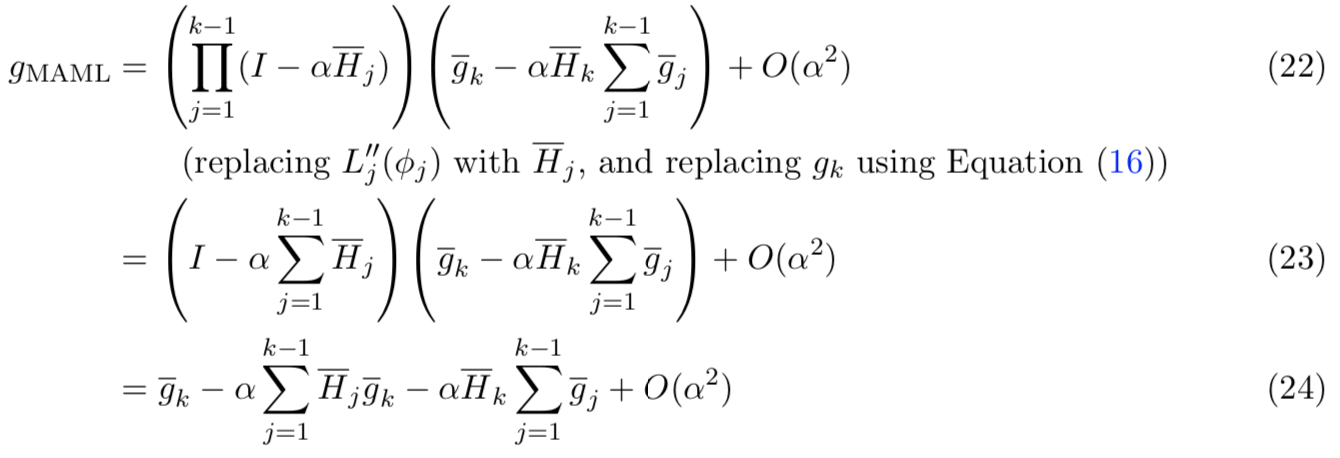
这样梯度就变为了只与初始参数Φ1相关的一阶、二阶式子
为便于说明,让我们考虑k = 2的情况,稍后我们将给出一般公式。三种算法的梯度为:
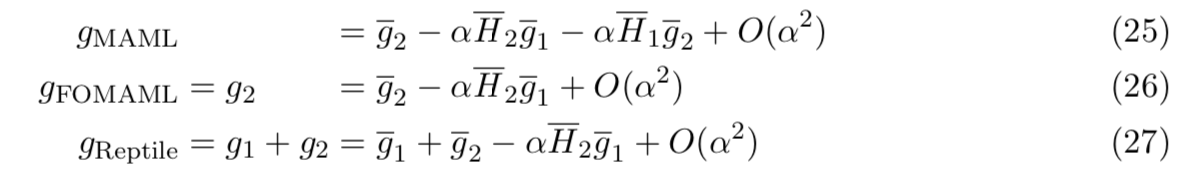
gMAML的结果是使用k=2代入等式(24)得到的
gReptile的结果就是使用k=2代入等式(16)得到的
可见Reptile仅在训练数据中使用SGD就能够得到和MAML类似的效果,因此后面直接使用![]() 看作梯度输入优化器Adam优化参数即可
看作梯度输入优化器Adam优化参数即可
其中如![]() 这样的项就是leading-order;
这样的项就是leading-order;![]() 这样的项就是次leading-order
这样的项就是次leading-order
正如我们将在下一段中所展示的,像![]() 这样的项可以使计算在不同小批量上的梯度之间的内积最大化,而像
这样的项可以使计算在不同小批量上的梯度之间的内积最大化,而像![]() 这样的单一梯度项则使我们在联合训练问题中达到最小值。
这样的单一梯度项则使我们在联合训练问题中达到最小值。
当我们在minibatch采样下得到三种算法梯度gFOMAML, gReptile, and gMAML的期望时,我们仅留下两类叫做AvgGrad和AvgGradInner的项。在下面的等式中,![]() 表示我们在任务得到的期望,两个minibatched分别定义为L1和L2
表示我们在任务得到的期望,两个minibatched分别定义为L1和L2
- AvgGrad被定义为期望损失的梯度:
![]()
(−AvgGrad)是能够将带到“联合训练”问题的最小值的方向;任务的期望损失
更有意思的项是AvgGradInner,定义如下:
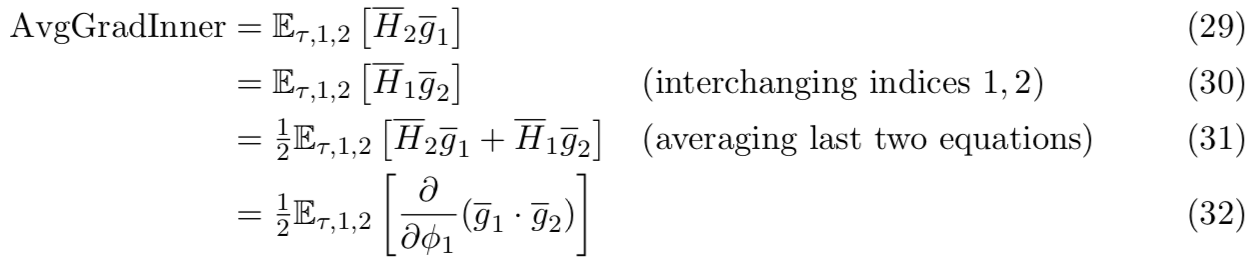
因此(−AvgGradInner)是增加给定任务的不同minibatches间梯度内积的方向,可改善泛化能力
回想我们梯度表达式,我们能得到如下用于meta-gradients的表达式,使用的是k=2的SGD,三种算法的梯度期望为:
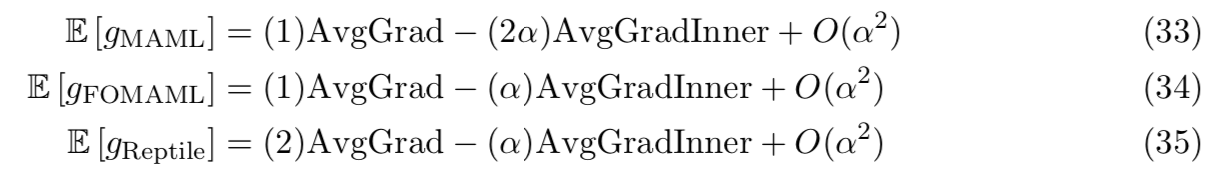
实际上,这三个梯度表达式首先都会将我们带到任务期望损失的最小值,然后更高阶的AvgGradInner项能通过最大化给定任务梯度间的内积来实现更快的学习
最后,我们能够扩展这三个计算到通用情况上,即 k>=2:
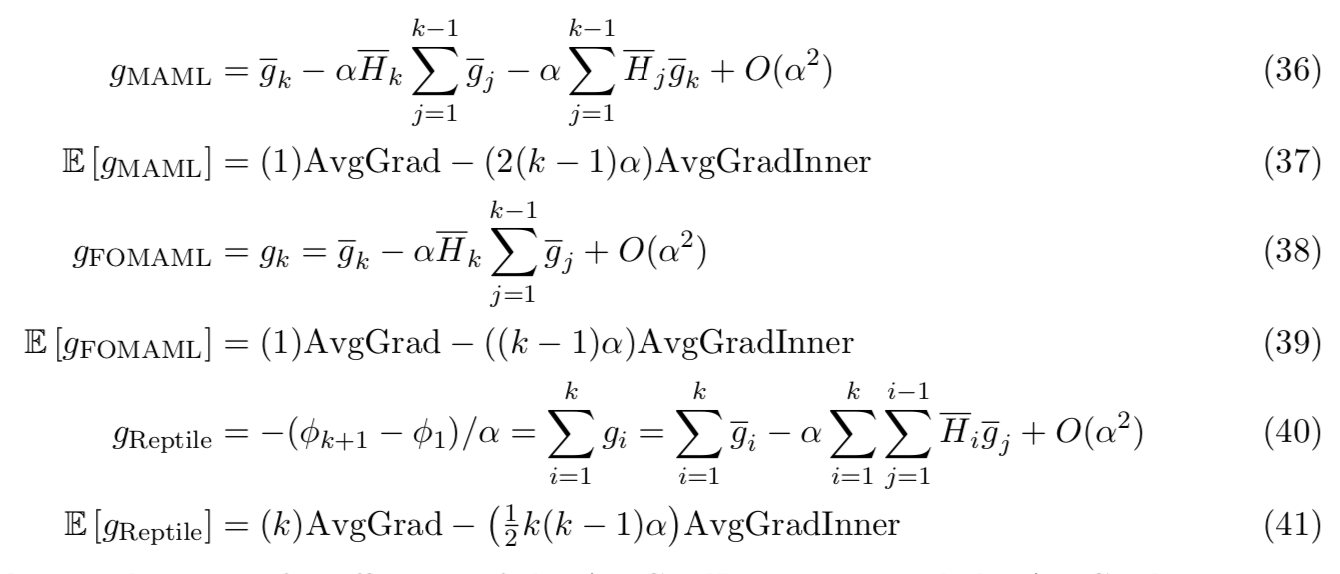
当k=2时,AvgGradInner项和AvgGradInner项的相关系数比率是![]() 。可是,该比率将随着stepsize α和迭代次数k线性增加。注意泰勒级数近似只对小的αk可用。
。可是,该比率将随着stepsize α和迭代次数k线性增加。注意泰勒级数近似只对小的αk可用。
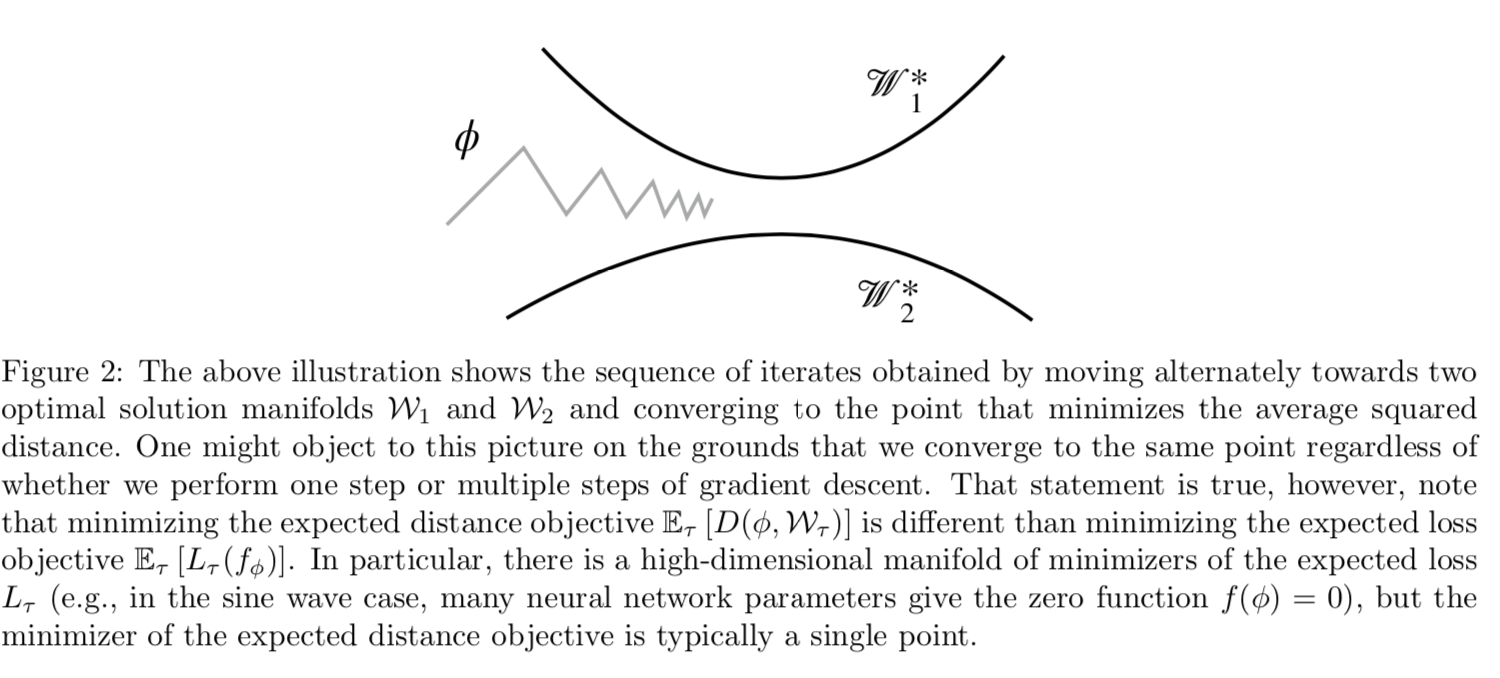
5.2 Finding a Point Near All Solution Manifolds
在这里,我们认为Reptile收敛于一个解Φ,这个解接近(欧几里得距离)每个任务的最优解的manifold。这是一种非正式的论证,不像前面的泰勒级数分析那样严肃。
让Φ表示网络的初始化,并让![]() 表示任务的最优参数集。我们希望找到使所有任务的距离
表示任务的最优参数集。我们希望找到使所有任务的距离![]() 小的Φ:
小的Φ:

我们展示了Reptile对应于在该目标上实行SGD
给定non-pathological集![]() ,然后对于几乎所有点
,然后对于几乎所有点![]() ,平方距离
,平方距离![]() 的梯度是
的梯度是![]() ,其中
,其中![]() 是Φ到S的投射(最近点)。因此:
是Φ到S的投射(最近点)。因此:
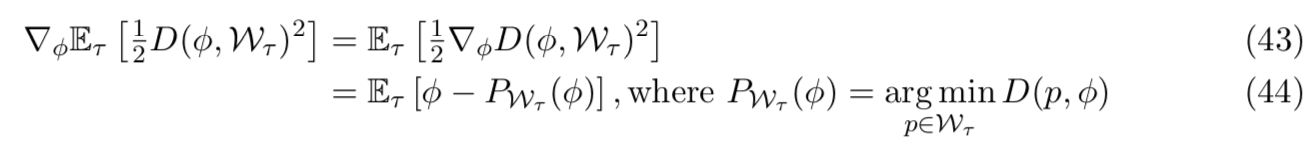
Reptile的每个迭代对应于采样一个任务和实行一个随机梯度下降:

实际上,我们并不能计算![]() ,其定义为
,其定义为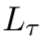 的一个最小值。但是我们能够使用梯度下降局部最小化该损失。因此,在Reptile中,我们在一开始用Φ初始化的上使用k个steps的梯度下降的结果来替
的一个最小值。但是我们能够使用梯度下降局部最小化该损失。因此,在Reptile中,我们在一开始用Φ初始化的上使用k个steps的梯度下降的结果来替![]()
6 Experiments
6.1 Few-Shot Classification
我们在两个流行的few-shot分类任务上评估了我们的方法:Omniglot[11]和Mini-ImageNet[18]。这些数据集使我们的方法容易与其他few-shot的学习方法,如MAML,相比较。
在few-shot分类任务中,我们有一个包含许多类C的元数据集D,其中每个类C本身是一组示例实例{c1, c2,…,cn}。如果我们做的是K-shot, N-way分类,那么我们通过从总类C中选N个类,然后为每个类选择K + 1个例子来采样任务。我们将这些示例分割为一个训练集和一个测试集,其中测试集包含每个类的单个示例。模型可以看到整个训练集,然后它必须能够分类从测试集中随机选择的样本。例如,如果你训练模型用于5-shot,5-way分类,然后你将给模型25个样本(每类5个样本,有5个类),并让它分类第26个样本。
除了上面的设置之外,我们还尝试了传导(transductive)设置,其中模型一次对整个测试集进行分类。在我们的传导实验中,信息通过batch normalization[9]在测试样品之间共享。在我们的非传导(non-transductive)实验中,batch normalization统计使用所有的训练样本和单一的测试样本来计算。我们注意到Finn等人[4]使用传导来评估MAML。
在我们的实验中,我们使用与Finn等[4]相同的CNN架构和数据预处理。在整个实验中,我们在内循环中使用Adam optimizer[10],在外循环中使用vanilla SGD。对于Adam,我们将其设置为β1 = 0,因为我们发现momentum会全面降低性能。在训练过程中,我们没有对Adam的滚动矩数据进行重置或插值;相反,我们让它在每个内循环训练步骤中自动更新。但是,在评估测试集时,我们备份并重置了Adam统计数据,以避免信息泄漏。
在Omniglot和Mini-ImageNet上的结果如表1和表2所示。虽然MAML、FOMAML和Reptile在所有这些任务上都具有非常相似的性能,但Reptile在Mini-ImageNet上的性能略好于替代方案,在Omniglot上的性能略差。传导似乎在所有情况下都能提高性能,这表明进一步的研究应该密切关注在测试过程中对batch normalization的使用。

6.2 Comparing Different Inner-Loop Gradient Combinations
在本实验中,我们在每个内循环中使用4个不重叠的mini-batches,产生梯度g1、g2、g3和g4。然后,我们比较了使用不同的gi的线性组合进行外循环更新时的学习性能。注意,两步Reptile对应g1 + g2,两步FOMAML对应g2。
为了更容易地比较不同的线性组合,我们用几种方法简化了实验设置。首先,我们在内部和外部循环中都使用vanilla SGD。其次,我们没有使用meta-batches。第三,我们把实验限制在5-shot 5-way的Omniglot。通过这些简化,我们不必过多地担心超参数或优化器的影响。
图3显示了各种内循环梯度组合的学习曲线。对于一个以上项的梯度组合,我们对内部梯度进行求和和平均来校正有效步长增加。
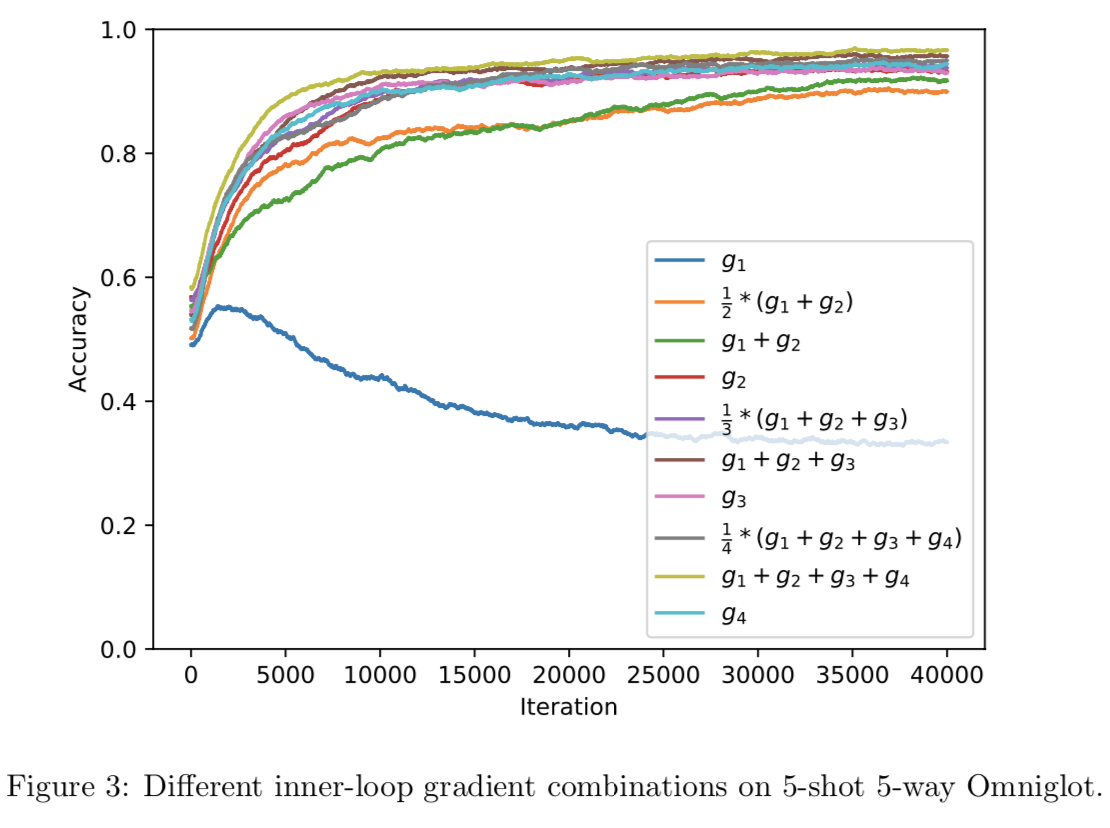
正如预期的那样,只使用第一个梯度g1是相当无效的,因为它等于优化所有任务的预期损失。令人惊讶的是,两步Reptile(即g1 + g2,绿色)明显比两步FOMAML(即g2,红色)更糟糕,这可能是因为两步Reptile中对比AvgGrad,给AvgGradInner的权重更少(公式(34)和(35))。最重要的是,所有的方法都会随着mini-batches数量的增加而改进。当使用所有梯度的累加(爬行类)而不是只使用最终梯度(FOMAML)时,这种改进更为显著。这也表明Reptile可以从执行许多内部循环步骤中获益,这与6.1节中找到的最佳超参数一致。
6.3 Overlap Between Inner-Loop Mini-Batches
Reptile和FOMAML都在内部循环中使用随机优化。对这个优化过程的微小更改可能导致最终性能的大变化。本节探讨了Reptile和FOMAML对内部循环超参数的敏感性,还显示了如果mini-batches选择错误,FOMAML的性能会显著下降。
本节中的实验将研究shared-tail FOMAML —— 其最终的内循环mini-batch与早期的内循环batches来自同一个数据集, 和seperate-tail FOMAML —— 其最后的mini-batch来自一组不相关的数据,这两个FOMAML之间的差异。将seperate-tail FOMAML看作是一种近似于MAML的方法,可以认为是更正确的方法(Finn等人[4]使用了它),因为训练时间优化类似于测试时间优化(测试集与训练集不重叠)。事实上,我们发现seperate-tail FOMAML明显优于shared-tail FOMAML。正如我们将展示的,当用于计算元梯度(gFOMAML = gk)的数据与之前的批次显著重叠时,shared-tail FOMAML的性能会下降;然而,Reptile和seperate-tail FOMAML能维护性能,并且对内部循环超参数不是很敏感。
图4a显示,当通过训练数据循环(shared-tail,cycle)选择minibatches时,shared-tail FOMAML最多执行4次内循环迭代,但在5次迭代时性能下降,其中最终的minibatch(用于计算gFOMAML = gk)与之前的minibatches重叠。当我们使用随机抽样方法代替循环选取方法(shared-tail,replacement)时,shared-tail FOMAML退化得更缓慢。我们推测这是因为在最后一批中仍然出现了一些之前没有出现的样品。效果是随机的,所以曲线更平滑是有道理的。
图4b显示了类似的现象,但是这里我们将内部循环固定为4次迭代,并改变batch大小。对于大于25的batch size,shared-tail FOMAML的最后一个内部循环batch必须包含以前batches的样本。与图4a相似,在这里我们观察到,随机抽样下的shared-tail FOMAML比循环下的shared-tail FOMAML退化更缓慢。
在这两种参数扫描中,随着内循环迭代次数或batch size的变化,seperate-tail FOMAML和Reptile的性能不会下降。
对于上述发现有几种可能的解释。例如,我们可以假设,在这些实验中,shared-tail FOMAML的效果更差,只是因为它的有效步长远低于seperate-tail FOMAML。然而,图4c表明情况并非如此:在一次彻底扫描中,对于每一个步长选择,性能都同样糟糕。另一种假设是,shared-tail FOMAML表现不佳的原因是,在一个样本上经过几个内循环步骤后,该样本的损失梯度并不包含关于该样本的非常有用的信息。换句话说,最初的几个SGD步骤可能会使模型接近局部最优,然后进一步的SGD步骤可能只是在这个局部最优附近反弹。

7 Discussion
在测试时执行梯度下降的元学习算法由于其简单性和泛化特性[5]很具有吸引力。微调的有效性(例如,在ImageNet[2]上训练的模型)给了我们对这些方法更多的信心。本文提出了一种新的算法——Reptile,其训练过程与联合训练只有细微的不同,只使用一阶梯度信息(如一阶MAML)。
对于Reptile的工作原理,我们给出了两个理论解释。首先,通过用泰勒级数近似更新,我们证明了SGD自动给出了MAML计算的同样类型的二阶项。这个项调整初始权值以最大化同一任务上不同小批量的梯度之间的点积,即它鼓励在同一任务的小批量之间泛化梯度。我们还提供了第二个非正式的论点,即Reptile找到了一个接近(欧氏距离)所有训练任务的最优解manifold的点。
虽然本文研究的是元学习设置,但第5.1节中的泰勒级数分析在一般情况下可能对随机梯度下降有一定的影响。这表明,在进行随机梯度下降时,我们会自动执行类似MAML的更新,从而最大化不同小批量之间的泛化。这个观察结果部分地解释了为什么微调(例如,从ImageNet到更小的数据集[20])效果很好。这一假设表明,联合训练加上微调将继续成为元学习在各种机器学习问题上的强大基础。
8 Future Work
我们看到了未来工作的几个有希望的方向:
- 理解SGD在多大程度上自动优化泛化,以及这种效果是否能在非元学习设置中被放大。
- 在强化学习设置中应用Reptile。到目前为止,我们得到了消极的结果,因为联合训练是一个强大的基线,所以Reptile的一些修改可能是必要的。
- 探索是否可以通过更深层次的分类器架构来提高Reptile的few-shot学习性能。
- 探索正则化是否可以提高few-shot学习性能,因为目前训练和测试错误之间存在很大的差距。
- 评估Reptile在[14]的few-shot密度建模任务的效果。