Analyzing and Improving the Image Quality of StyleGAN
Abstract
基于风格的GAN架构(StyleGAN)在数据驱动的无条件生成图像建模方面产生了最先进的结果。我们公开并分析了它的一些特征伪影(artifacts),并建议在模型架构和训练方法中进行更改来处理它们。特别地,我们重新设计了生成器的标准化,重新审视渐进增长,并规范生成器以促进从潜在编码到图像的良好映射。除了改善图像质量,这一路径长度正则化器产生额外的好处,使生成器变得明显更容易逆转。这样就可以可靠地将生成的图像贡献给特定的网络。我们进一步可视化了生成器如何很好地利用它的输出分辨率,并确定一个容量问题,促使我们训练更大的模型,以获得额外的质量改进。总的来说,我们改进的模型重新定义了无条件图像建模的最新技术,包括现有的分布质量指标和可感知的图像质量。
1. Introduction
生成方法产生的图像的分辨率和质量,特别是生成对抗网络(GAN)[16],正在迅速提高[23,31,5]。目前最先进的高分辨率图像合成方法是StyleGAN[24],它已被证明在各种数据集上可靠地工作。我们的工作集中在修复其特征伪影和进一步提高结果质量上。
StyleGAN[24]的特色是它非传统的生成器架构。已经不是仅将输入潜在编码z∈Z输入网络的开始,而是使用一个网络的映射f首先将z转换成一个中间潜在编码w∈W 。然后使用仿射变换产生styles,通过adaptive instance normalization (AdaIN) [21, 9, 13, 8]来控制合成网络g的层。此外,通过向合成网络提供额外的随机噪声映射,用于随机变化。已经证明[24,38],这种设计使得中间潜在空间W比输入潜在空间Z的纠缠度小得多。在本文中,我们仅对W进行分析,因为从合成网络的角度来看,W是相关的潜在空间。
许多观测者已经注意到StyleGAN[3]生成的图像中的特征伪影。我们确定了产生这些伪影的两个原因,并描述了为了消除它们的架构和训练方法中的变化。首先,我们调查了常见的blob样伪影的起源,并发现生成器创建它们是为了规避其体系结构中的设计缺陷。在第2部分中,我们重新设计了生成器中使用的标准化,这将删除伪影。其次,我们分析了与不断增长[23]相关的伪影,其在稳定高分辨率GAN训练中非常成功。我们提出了一种实现同样目标的替代设计——训练从关注低分辨率的图像开始,然后逐步将焦点转移到越来越高的分辨率上——在训练期间不改变网络拓扑。这个新设计还允许我们推断生成的图像的有效分辨率,结果显示它比预期的要低,从而促使容量增加(第4节)。
使用生成方法生成的图像质量的定量分析仍然是一个具有挑战性的话题。Fre ́chet inception distance (FID)[20]测量在InceptionV3分类器[39]的两个分布的密度差异。Precision and Recall (P&R)[36,27]分别明确地量化生成的与训练数据相似的图像的百分比和可以生成的训练数据的百分比,从而提供了额外的可视性。我们使用这些度量来量化改进。
FID和P&R都是基于分类器网络,这些分类器网络最近被证明更关注纹理而不是形状[12],因此,这些指标不能准确地捕捉图像质量的所有方面。我们观察到感知路径长度(PPL, perceptual path length)度量[24],最初被引入作为一种估计潜在空间插值质量的方法,与形状的一致性和稳定性相关。在此基础上,我们规范化合成网络,使其有利于平滑映射(第3节),并在质量上得到了明显的提高。为了抵消它的计算开销,我们还建议减少所有正则化的执行频率,观察到这可以在不影响效率的情况下完成。
最后,我们发现新的路径长度正则的StyleGAN2生成器比原来的StyleGAN2生成器能更好地将图像投影到潜在空间W上。这使得将生成的图像赋给它的源更加容易(第5节)。
我们的实现和训练模型可在以下网站获得:https://github.com/NVlabs/stylegan2
2. Removing normalization artifacts
我们首先观察到,StyleGAN生成的大多数图像都呈现出类似水滴的特征斑点状伪影。如图1所示,即使在最终的图像中液滴并不明显,它也会出现在生成器的中间特征图中。异常在64×64分辨率左右开始出现,在所有的特征映射中都存在,并且在高分辨率下逐渐增强。这种一致性伪影的存在是令人费解的,因为鉴别器应该能够检测到它。
我们将问题定位到AdaIN操作,该操作将每个特征图的均值和方差分别归一化,从而可能破坏在特征相对大小中发现的任何信息。我们假设,雾滴伪影是生成器有意将信号强度信息传递到实例归一化(instance normalization)的结果:通过创建一个强大的、控制统计的局部尖峰,生成器可以在其喜欢的任何地方有效地缩放信号。我们的假设得到了以下发现的支持:当标准化步骤从生成器中移除时,液滴伪影完全消失。

2.1. Generator architecture revisited
我们将首先修改StyleGAN生成器的几个细节,以更好地促进我们重新设计的标准化。就质量度量而言,这些变化对它们自己有中立或小的积极影响。
图2a显示了原始的StyleGAN合成网络g[24],在图2b中,我们通过显示权重和偏差,并将AdaIN操作分解为两个组成部分:归一化和调制,将图表扩展到完整的细节。这允许我们重新绘制概念性的灰色框,以便每个框都指示网络中某一style处于活动状态的部分(即。“style block”)。有趣的是,最初的StyleGAN在样式块中应用了偏差和噪声,导致它们的相对影响与当前样式的大小成反比。我们观察到,通过将这些操作移到样式块之外,可以获得更可预测的结果,在样式块中,这些操作对非规范化数据进行操作。此外,我们注意到,在这个变化之后,仅在标准差上操作(即不需要平均值)对于归一化和调制来说是足够的了。应用偏差、噪声和归一化的常数输入也可以安全地去除,没有明显的缺点。这个变体如图2c所示,并作为我们重新设计的标准化的起点。
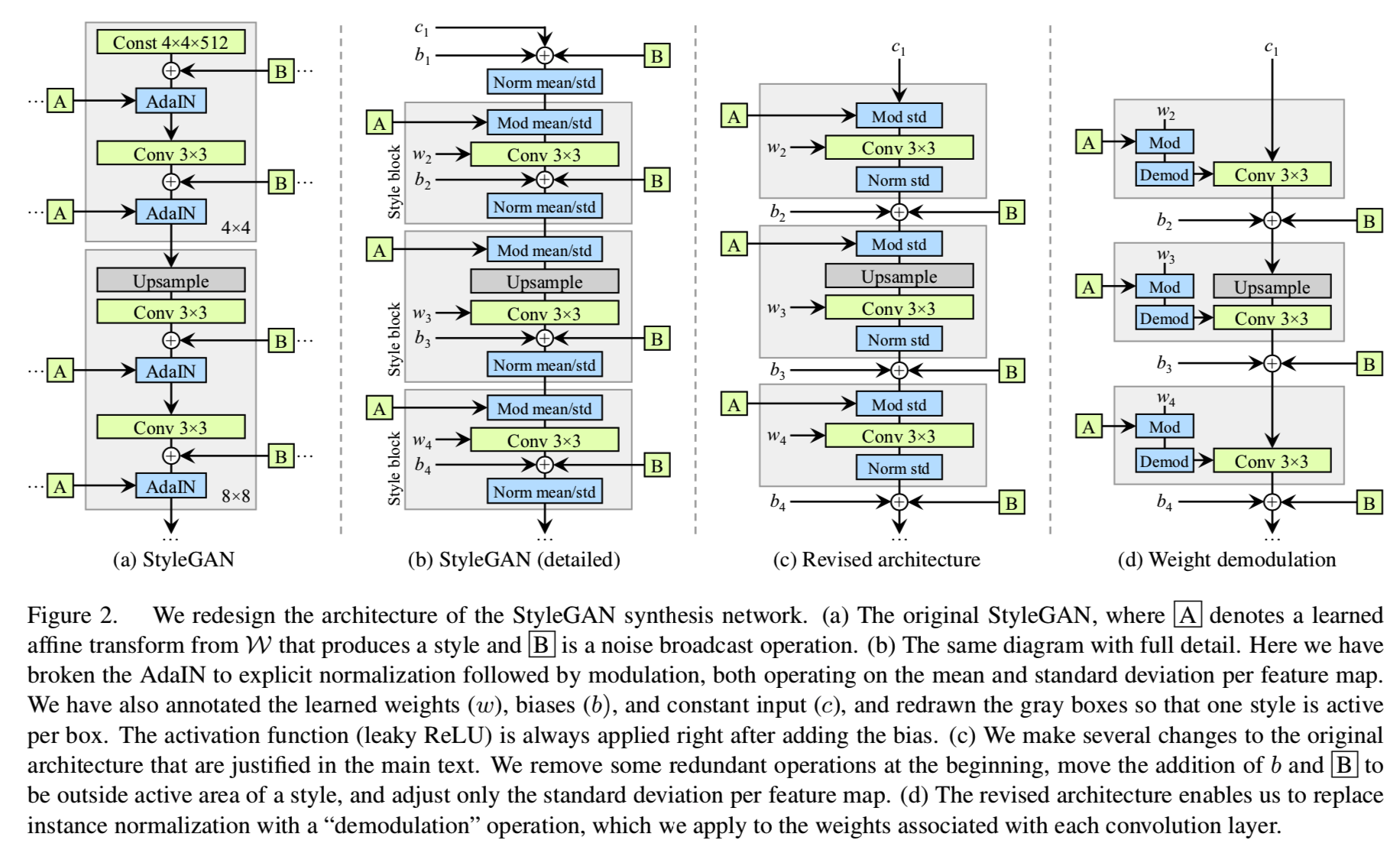
2.2. Instance normalization revisited
StyleGAN的主要优点之一是能够通过style mixing来控制生成的图像。,通过在推理时间向不同层输入不同的潜在w。在实践中,风格调制可以放大某些特征图的一个数量级或更多。为了使风格混合工作,我们必须明确地在每个样本的基础上抵消这种放大——否则随后的层将不能以一种有意义的方式对数据进行操作。
如果我们愿意牺牲特定比例的控制(见视频),我们可以简单地去除标准化,从而能够去除伪影,也稍微改善了FID[27]。现在,我们将提出一个更好的替代方案,在保留完全可控性的情况下删除伪影。主要的想法是基于期望的统计数据的输入特征映射的规范化,但没有明确的强制。
回想一下,图2c中的style block由调制、卷积和归一化组成。让我们先来考虑一下调制后的卷积效应。调制是根据输入方式对卷积的每个输入特征图进行缩放,也可以通过缩放卷积权重来实现:
![]()
其中w和w'分别表示原始的和调制后的权重,si是对应于第i个输入特征映射的缩放因子,j和k分别列举了输出特征映射和卷积的空间足迹
现在,instance normalization的目的是从根本上消除s对卷积输出特征图统计量的影响。我们注意到,这一目标可以更直接地实现。我们假设输入激活是具有单位标准差的随机变量。经过调制和卷积后,输出激活的标准差为:
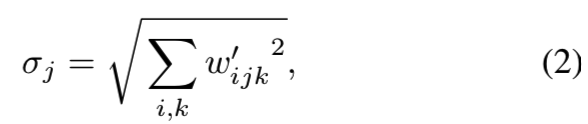
输出按相应权重的L2范数进行缩放。随后的归一化旨在将输出恢复到单位标准差。根据式2,我们可以通过将每个输出特征图j按1/ σj缩放(“解调制”)来实现。或者,我们也可以把它代入卷积权值中:

其中ε是一个小的常量,用来避免分母为0
现在我们已经将整个style block弄成一个卷积层,卷积层的权值使用公式1和3根据s进行调整(图2d)。与实例归一化相比,我们的解调技术比较弱,因为它是基于信号的统计假设,而不是特征图的实际内容。类似的统计分析在现代网络初始化器中被广泛使用[14,19],但我们没有意识到它以前被用作数据依赖标准化的替代。我们的解调也与权值归一化[37]有关,它执行同样的计算作为权值张量重新参数化的一部分。之前的研究已经确认,在GAN训练[43]的背景下,权值归一化是有益的。
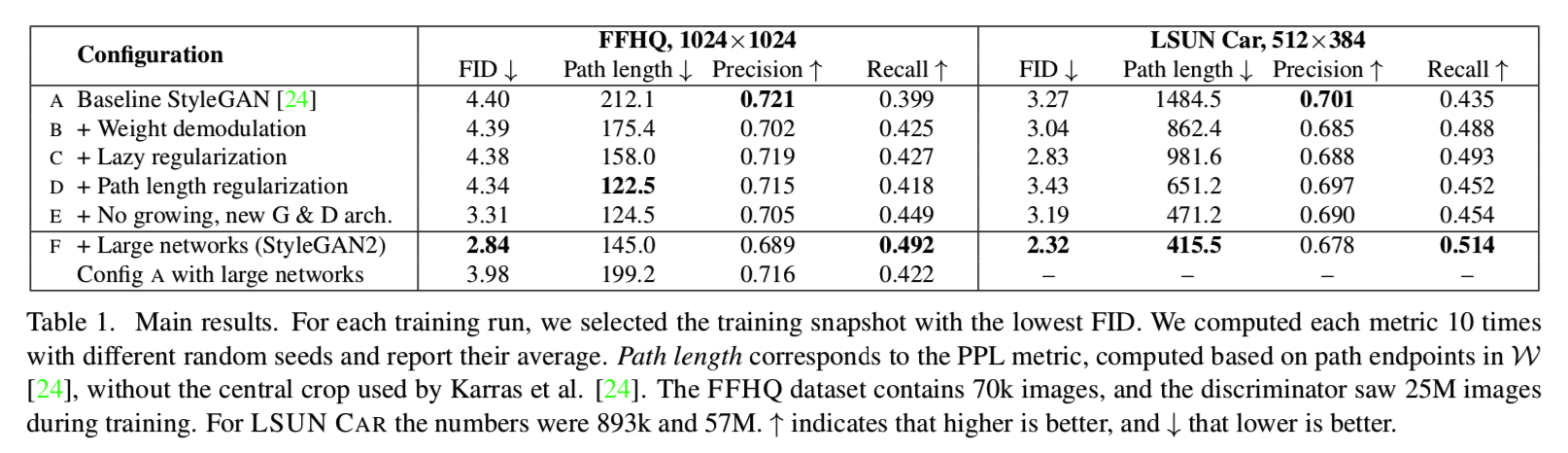
我们的新设计删除了特征伪影(图3),同时保留了完全的可控性,如所附的视频所示。FID在很大程度上没有受到影响(表1,A, B行),但是从precision到recall有明显的变化。我们认为这通常是可取的,因为通过截断可以将召回转换为精度,而反向[27]则不是正确的。在实践中,我们的设计可以有效地使用grouped convolutions来实现,详见附录b。为了避免需要考虑公式3中的激活函数,我们对激活函数进行了缩放,使其保持预期的信号方差。

3. Image quality and generator smoothness
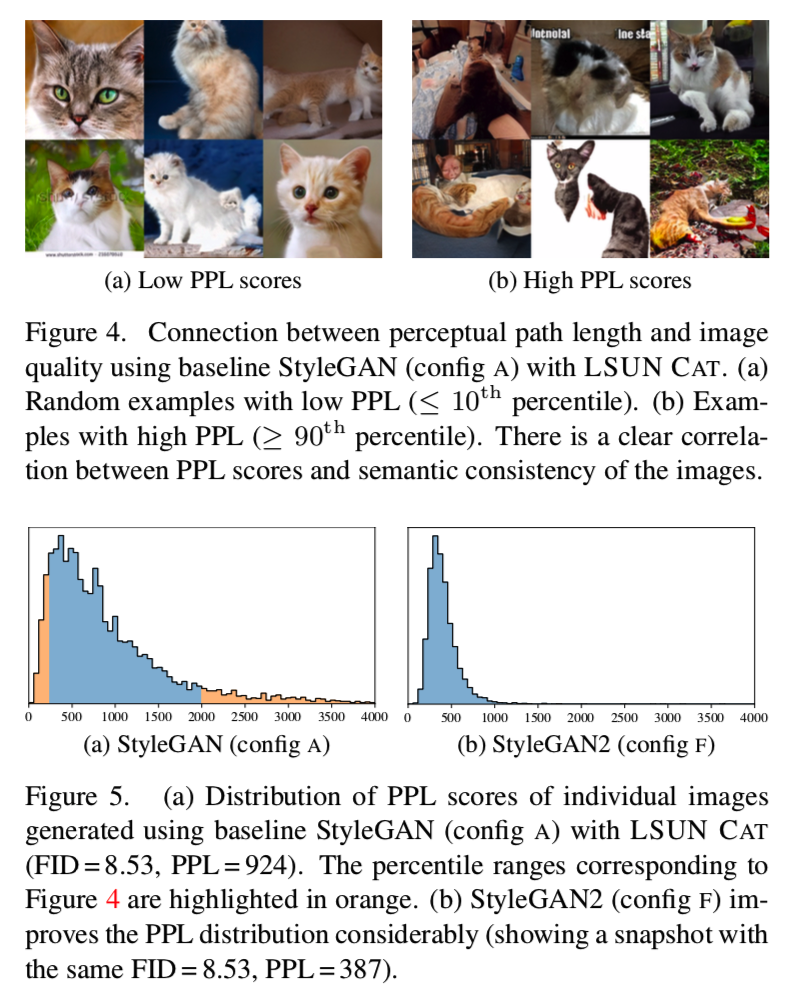
虽然像FID或Precision and Recall (P&R)这样的GAN指标成功地捕获了生成器的许多方面,但它们在图像质量方面仍然存在一些盲点。例如,参考图13和图14,它们将生成器与相同的FID和P&R分数进行对比,但总体质量却明显不同


我们观察到感知图像质量和感知路径长度(PPL)[24]之间的相关性,感知路径长度[24]最初是用于量化从潜在空间映射到输出图像的平滑性,通过测量潜在空间小扰动下生成图像之间的平均LPIPS距离[50]。再次参考图13和图14,更小的PPL(更平滑的生成器映射)似乎与更高的整体图像质量相关,而其他指标对变化是盲目的。图4通过在LSUN Cat数据集上每个图片的PPL分数证明了该相关性是十分密切的,通过从![]() 中采样潜在空间计算得到。分数低确实表明图像质量高,反之亦然。图5a为对应的柱状图,显示了分布的长尾。该模型的总体PPL只是这些每幅图像PPL得分的期望值。我们总是计算整个图像的PPL,与Karras等人[24]不同,他们使用较小的central crop。
中采样潜在空间计算得到。分数低确实表明图像质量高,反之亦然。图5a为对应的柱状图,显示了分布的长尾。该模型的总体PPL只是这些每幅图像PPL得分的期望值。我们总是计算整个图像的PPL,与Karras等人[24]不同,他们使用较小的central crop。
目前还不清楚为什么低PPL与图像质量相关。我们假设在训练过程中,当鉴别器对破碎的图像进行惩罚时,最直接的改进方法是有效地拉伸潜在空间区域,从而产生良好的图像。这将导致低质量的图像被挤压到迅速变化的小的潜在空间区域内。虽然这在短期内提高了平均输出质量,但累积的失真损害了训练的动力,从而影响了最终的图像质量。
显然,我们不能简单地鼓励最小PPL,因为这将引导生成器走向零召回的退化解决方案。相反,我们将描述一个新的正则化器,它的目标是使生成器映射更平滑,而不存在此缺点。由于得到的正则化项计算起来有些昂贵,我们首先描述一个适用于任何正则化技术的一般优化。
3.1. Lazy regularization
通常,主要损失函数(如logistic损失[16])和正则化项(如R1[30])被写成单个表达式,从而同时进行优化。我们观察到正则化项的计算频率比主要损失函数要低,从而大大降低了它们的计算成本和总体内存使用量。表1,C行显示,当R1正则化每16个小批量执行一次时,没有造成损害,我们对我们的新正则化器也采用相同的策略。附录B给出了实现细节。
3.2. Path length regularization
我们希望W中的一个固定大小的步长会导致图像中非零的固定大小的变化。我们可以通过在图像空间中进入随机方向并观察相应的w梯度来测量与这个理想的偏差。无论w方向或图像空间方向如何,这些梯度的长度应该接近相等,表明从潜在空间到图像空间的映射是条件良好的[33]。
在一个单一的![]() 中,生成器映射函数
中,生成器映射函数![]() 的局部度量缩放特性可通过
的局部度量缩放特性可通过![]() 获得。为了保持向量的期望长度,无论方向如何,我们将正则化器表示为:
获得。为了保持向量的期望长度,无论方向如何,我们将正则化器表示为:
![]()
其中y是有着正态分布的像素强度的随机图像,![]() ,z是正态分布。我们在附录C中表明,在高维情况下,当Jw在任意w处正交(直到全局尺度)时,这个先验是最小的。一个正交矩阵保持长度,并且没有在任意维上引入压缩。
,z是正态分布。我们在附录C中表明,在高维情况下,当Jw在任意w处正交(直到全局尺度)时,这个先验是最小的。一个正交矩阵保持长度,并且没有在任意维上引入压缩。
为了避免Jacobian矩阵的显式计算,使用恒等式![]() ,其使用标准后向传播[6]可以有效计算。常量a是在优化中动态设置为长度
,其使用标准后向传播[6]可以有效计算。常量a是在优化中动态设置为长度![]() 的长期指数移动平均值,允许优化自己找到一个合适的全局规模。
的长期指数移动平均值,允许优化自己找到一个合适的全局规模。
我们的regularizer与Odena等人[33]提出的Jacobian矩阵clampingregularizer密切相关。实际差别包括我们是解析地计算![]() ,而他们使用有限差值来估计
,而他们使用有限差值来估计![]() 。需要注意的是,生成器[46]的spectral normalization[31]只约束最大奇异值,对其他奇异值没有约束,因此不一定会产生更好的条件。我们发现,除了我们的贡献之外,启用spectral normalization——或者代替它们——总是会损害FID,详见附录E。
。需要注意的是,生成器[46]的spectral normalization[31]只约束最大奇异值,对其他奇异值没有约束,因此不一定会产生更好的条件。我们发现,除了我们的贡献之外,启用spectral normalization——或者代替它们——总是会损害FID,详见附录E。
在实践中,我们注意到,路径长度正则化导致更可靠和行为一致的模型,使架构探索更容易。我们还观察到,更平滑的生成器明显更容易求反(Section 5)。图5b显示,路径长度正则化清晰地收紧了每幅图像的PPL分数分布,而没有将模式推到零。然而,表1D行指出了FID和PPL在数据集中的权衡,这些数据集中的结构比FFHQ要少。
4. Progressive growing revisited
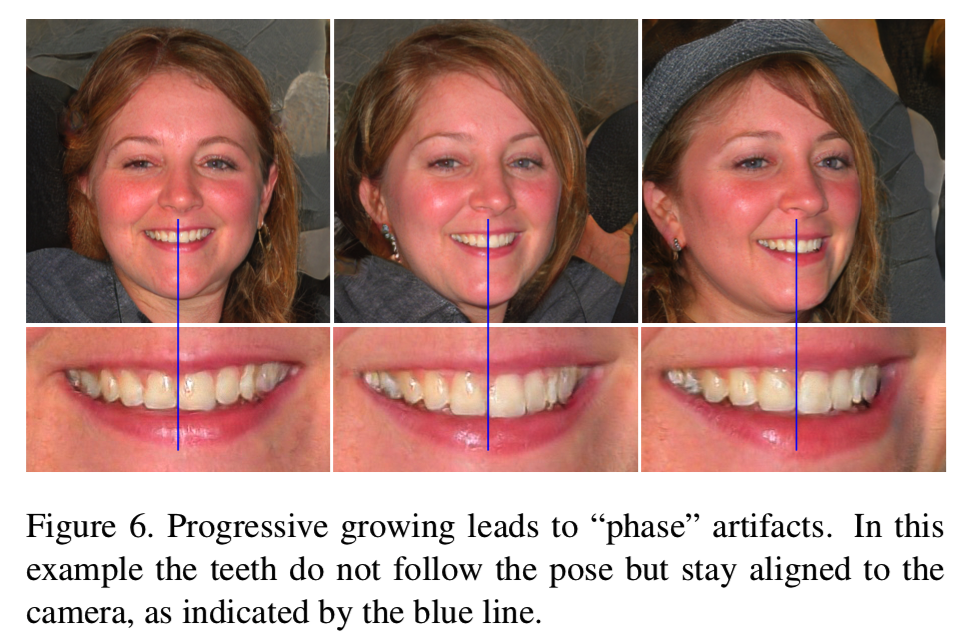
Progressive growing[23]在稳定高分辨率图像合成方面非常成功,但它会产生自己特有的伪影。关键的问题是,逐渐增长的generator似乎有一个强烈的位置偏好的细节;随附的视频显示,当牙齿或眼睛等特征应该在图像上平滑移动时,它们可能会在跳转到下一个首选位置之前停留在原地。图6显示了一个相关的工件。我们认为,问题在于,在Progressive growing过程中,每个分辨率都暂时充当了输出分辨率的作用,迫使它生成最大的频率细节,从而导致训练好的网络在中间层拥有过高的频率,从而破坏了[49]的位移不变性。附录A给出了一个示例。这些问题促使我们寻求一种替代的提法,既能保留Progressive growing的好处,又不会有缺点。
4.1. Alternative network architectures
当StyleGAN在生成器(合成网络)和鉴别器中使用简单的前馈设计时,有大量的工作致力于研究更好的网络架构。跳跃连接[34,22],残差网络[18,17,31]和层次方法[7,47,48]在生成方法上下文中也被证明是非常成功的。因此,我们决定重新评估StyleGAN的网络设计,并寻找一种能产生高质量图像而又没有Progressive growing的架构。
图7a显示了MSG-GAN[22],它使用多个跳跃连接连接生成器和鉴别器的匹配分辨率。对MSG-GAN生成器进行修改,以输出一个mipmap[42]而不是图像,并为每个真实图像计算类似的表示。在图7b中,我们通过向上采样和对不同分辨率对应的RGB输出的贡献进行求和来简化这种设计。在鉴别器中,我们同样向鉴别器的每个分辨率块提供下采样图像。在所有的上采样和下采样操作中都使用了双线性滤波。在图7c中,我们进一步修改了设计以使用残差连接。该设计类似于LAPGAN[7],但没有Denton等人使用的per-resolution鉴别器。
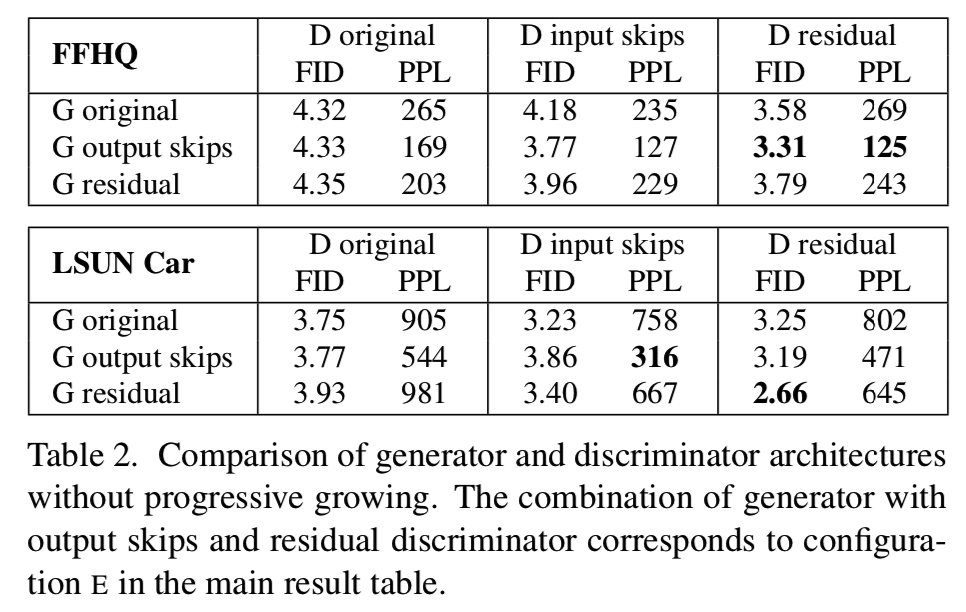
表2比较了三种生成器和三种鉴别器架构:StyleGAN中使用的原始前馈网络、skip connections和残差网络,它们都经过了训练,没有逐步增长。FID和PPL用于9种组合中的每一种。我们可以看到两个大的趋势:在所有配置中,跳过连接在生成器大大改善PPL,和残差鉴别网络显然有利于FID。后者也许并不令人惊讶,因为鉴别器的结构类似于已知残余结构是有用的分类器。然而,残差架构在生成器是有害的-唯一的例外是在LSUN Cat数据集中的FID,其中两个网络都是残差的。
在本文的其余部分,我们使用跳跃发生器和残差鉴别器,没有渐进增长。这与表1中的配置E相对应,显著改善了FID和PPL。
4.2. Resolution usage
我们想要保留的渐进增长的关键方面是,生成器首先会关注低分辨率的特性,然后慢慢地将注意力转移到更精细的细节上。图7中的架构使生成器能够首先输出不受高分辨率层显著影响的低分辨率图像,然后随着训练的进行将焦点转移到高分辨率层。由于这并没有以任何方式强制执行,所以生成器只会在有利的情况下执行。为了在实践中分析这种行为,我们需要量化在训练过程中生成器对特定分辨率的依赖程度。
由于跳跃生成器(图7b)通过显式地将多个分辨率的RGB值相加形成图像,因此我们可以通过测量对应层对最终图像的贡献大小来估计它们的相对重要性。在图8a中,我们绘制了每个tRGB层产生的像素值的标准差作为训练时间的函数。我们计算了1024个w随机样本值的标准差并将其规格化,使其和为100%
在训练开始时,我们可以看到新的跳跃生成器的行为类似于渐进式增长——现在在不改变网络拓扑的情况下实现。因此,有理由期望最高的分辨率在训练快结束时占主导地位。然而,图中显示,这种情况在实践中没有发生,这表明生成器可能无法“充分利用”目标分辨率。为了验证这一点,我们手动检查了生成的图像,并注意到它们通常缺少一些训练数据中存在的像素级细节——这些图像可以被描述为5122张图像的锐化版本,而不是真正的10242张图像。
这让我们假设我们的网络存在容量问题,我们通过将两个网络的最高分辨率层的特征图数量翻倍来测试。这使得行为更符合预期:图8b显示了最高分辨率层的贡献显著增加,而表1 F行显示FID和Recall显著提高。最后一行显示基线StyleGAN也受益于额外的容量,但其质量仍然远远低于StyleGAN2。
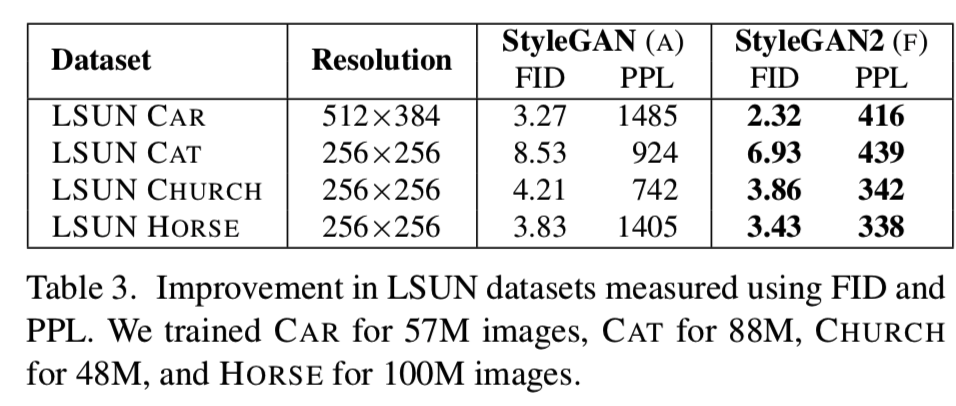
表3比较了四类LSUN中的StyleGAN和StyleGAN2,再次显示了FID的明显改善和PPL的显著进展。进一步扩大规模可能会带来额外的好处。

5. Projection of images to latent space
合成网络g的反向是一个有趣的问题,具有广泛的应用。在潜在特征空间中对给定图像进行处理,首先需要找到与其匹配的潜在码w。之前的研究[1,10]表明,如果每一层发生器都选择一个单独的w,结果会有所改善,而不是寻找一个共同的潜码w。在早期的编码器实现[32]中使用了相同的方法。在以这种方式扩展潜在空间的同时,可以找到与给定图像更接近的匹配,这也使得投影没有潜在表现的任意图像成为可能。相反,我们专注于在原始的、未扩展的潜在空间中寻找潜在代码,因为这些代码与生成器可能产生的图像相对应。
我们的投影方法与以前的方法有两个不同之处。首先,我们在优化过程中对潜在编码添加了下拉噪声,以便更全面地挖掘潜在编码空间。其次,我们还优化了styleGAN发生器的随机噪声输入,对它们进行正则化,以确保它们最终不会携带相干信号。正则化的基础是增强噪声映射的自相关系数,以在多个尺度上匹配单位高斯噪声。我们的投影方法的详细内容见附录D。
5.1. Attribution of generated images
检测操纵或生成的图像是一个非常重要的任务。目前,基于分类器的方法可以相当可靠地检测生成的图像,不管它们的确切来源是什么[29,45,40,51,41]。然而,考虑到生成方法的快速进步步伐,这可能不是一个持久的情况。除了对假图像的一般检测,我们还可以考虑这个问题的一种更有限的形式:能够将一个假图像归到它的特定源[2]上。使用StyleGAN,这相当于检查是否存在一个w∈W,能重新合成的图像的问题。
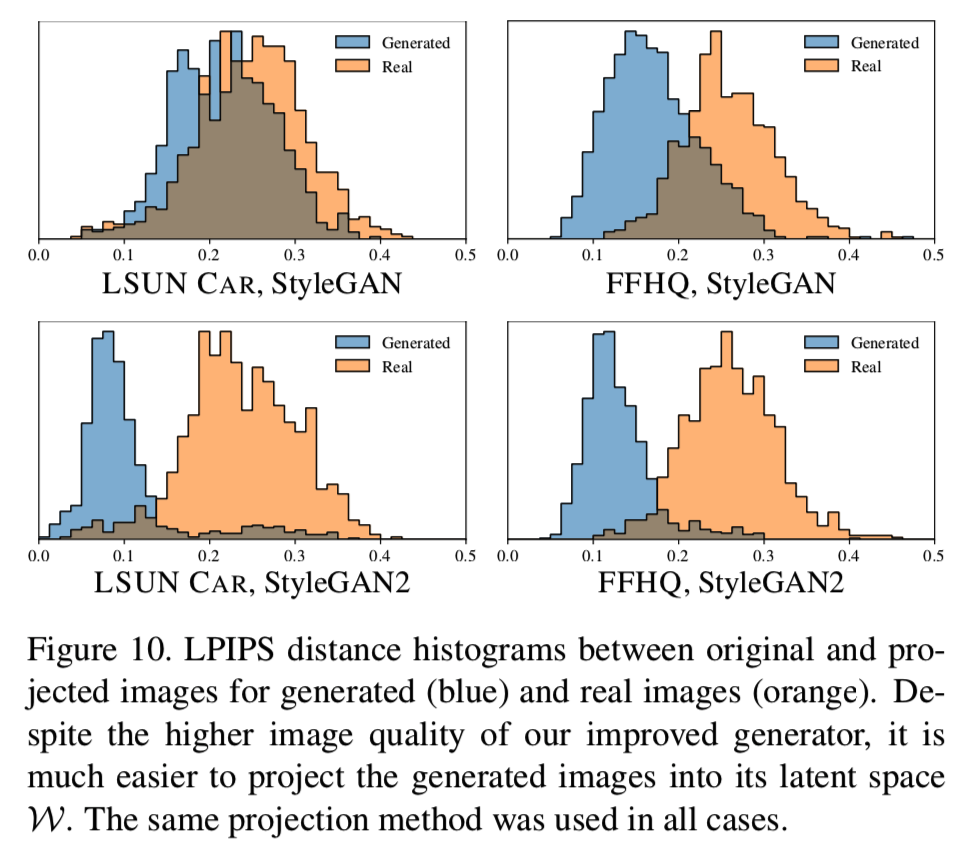
我们通过计算原始图像和重新合成图像之间的LPIPS[50]距离来衡量投影的成功程度,即![]() ,其中x是被分析的图像,
,其中x是被分析的图像,![]() 表示近似投影运算。图10显示了使用原始StyleGAN和StyleGAN2的LSUN CAR和FFHQ数据集的这些距离的直方图,图9显示了示例投影。使用StyleGAN2生成的图像可以很好地投影到W中,以至于它们几乎可以明确地归因于生成网络。然而,在最初的StyleGAN中,即使在技术上可以找到匹配的潜在代码,从W到图像的映射似乎太过复杂,无法在实践中可靠地成功。令人鼓舞的是,尽管图像质量得到了显著提高,StyleGAN2仍然使源归因变得更容易。
表示近似投影运算。图10显示了使用原始StyleGAN和StyleGAN2的LSUN CAR和FFHQ数据集的这些距离的直方图,图9显示了示例投影。使用StyleGAN2生成的图像可以很好地投影到W中,以至于它们几乎可以明确地归因于生成网络。然而,在最初的StyleGAN中,即使在技术上可以找到匹配的潜在代码,从W到图像的映射似乎太过复杂,无法在实践中可靠地成功。令人鼓舞的是,尽管图像质量得到了显著提高,StyleGAN2仍然使源归因变得更容易。
6. Conclusions and future work
我们已经确定并修复了StyleGAN的几个图像质量问题,进一步提高了质量,并大大提高了几个数据集的技术水平。在某些情况下,改进可以在运动中更清晰地看到,如所附的视频所示。附录A包括使用我们的方法得到的结果的进一步例子。尽管改进了质量,StyleGAN2使生成的图像更容易归因于其来源。
训练性能也有所提高。原始的StyleGAN(表1中配置A)在8个Tesla V100 gpu的NVIDIA DGX-1上每秒能运行37张图像,分辨率为10242,而我们的配置E在61 img/s的速度上快了40%。大部分的加速来自于由于权重解调、延迟正则化和代码优化而简化的数据流。StyleGAN2(配置F,更大的网络)的训练是31 img/s,因此只比原来的StyleGAN稍微贵一点。FFHQ的训练时间为9天,LSUN CAR的训练时间为13天。
整个项目,包括所有探究,耗电132mwh,其中0.68 MWh用于FFHQ最终模型的训练。总的来说,我们使用了大约51年的单GPU计算量(Volta类GPU)。在附录F中有更详细的讨论。
在未来,对路径长度正则化的进一步改进,如用数据驱动的特征空间度量代替像素空间L2距离,将会是卓有成效的。考虑到GANs的实际部署,我们认为找到减少训练数据需求的新方法将是很重要的。这在无法获得成千上万的训练样本的应用程序中尤为重要,而且数据集包含了大量的内在变异。