https://github.com/thunguyenphuoc/HoloGAN.
Abstract
我们提出了一种新的生成对抗网络(GAN),用于从自然图像中的三维表征的无监督学习。大多数生成模型都依赖于2D内核来生成图像,并且很少对3D世界进行假设。因此,这些模型倾向于在需要强的3D理解的任务中创建模糊的图像或伪影,如novel-view合成任务。相反,HoloGAN学习了世界的3D表征,并以一种真实的方式呈现这种表征。与其他GANs不同,HoloGAN通过学习三维特征的rigid-body变换,提供了对生成对象的姿态的显式控制。我们的实验表明,使用显式3D特征使HoloGAN能够分解3D姿态和身份,进一步分解为形状和外观,同时仍然能够生成比其他生成模型具有类似或更高视觉质量的图像。HoloGAN只能从未标记的二维图像中进行端到端训练。特别是,我们不需要姿态标签,3D形状,或同一对象的多个视图。这表明,HoloGAN是第一个以完全无监督的方式从自然图像学习3D表征的生成模型。
1. Introduction
学习去理解三维物体和二维图像之间的关系是计算机视觉和计算机图形学的一个重要课题。在计算机视觉领域,它在机器人、自动驾驶汽车或安全等领域都有应用。在计算机图形学中,它有利于内容生成和操作的应用程序。其应用范围从三维场景的逼真渲染,到基于草图的三维建模,到novel-view的合成或重绘。
最近的生成图像模型,尤其是生成对抗网络(GANs),在生成高分辨率和视觉质量 [1, 5, 27, 28, 62]的图像上取得了令人印象深刻的结果,同时他们的条件版本在图像到图像翻译[23, 50]、图像编辑[11、12、60]和运动转移[6、30]上取得了很大的进步。然而,GANs在其应用程序中仍然相当有限,因为它们不允许显式地控制生成的图像中的属性,而条件GANs在训练期间需要标签(图2左),这些标签并不总是可用的。
即使赋予了姿态信息这样的标签,当前的生成图像模型仍然在需要对3D结构有基本理解的任务中挣扎,比如从单个图像合成novel-view。例如,使用2D内核来执行3D操作,比如通过平面外旋转来生成新的视图,是非常困难的。目前的方法要么需要大量的标记训练数据,如多视图图像或分割掩模[41,52],要么产生模糊的结果[13,14,33,54,57]。尽管最近的工作已经通过使用3D数据来解决这个问题[40,64],但是3D真实数据的捕获和重建非常昂贵。因此,从未标记的2D图像中直接学习3D表征也是一种实际的需求。
出于这些观察,我们专注于设计一种新颖的体系结构,允许图像3D表征的非监督学习,这使得人们可以直接在生成图像模型中操纵视图、形状和外观(图1)。我们的网络设计的关键是将一个与3D世界相关的强归纳bias与深度生成模型相结合去为任务学习更好的表征。计算机图形的传统表示,如voxels和网格,在三维中是显式的,并且易于操作,例如,通过刚体变换进行操作。然而,它们的代价是内存的低效率或离散复杂对象时的模糊性。因此,直接用这样的表示来构建生成模型是很重要的[43,46,49]。隐式表示,如高维潜在向量或深层特征,在空间上的紧凑和语义上的表达受到生成模型的青睐。然而,这些特性并不是设计用来处理显式3D转换的[9,14,20,25,45],其导致了在任务,比如视图操作,上可视化的伪影和模糊。

我们提出HoloGAN,一个无监督的生成图像模型,用来学习不仅能在三维中是显式的,而且在语义上是可表达的三维对象的表征。这种表征可以直接从未标记的自然图像中学习。与其他GAN模型不同,HoloGAN同时使用3D和2D特征来生成图像。HoloGAN首先学习3D表征,然后将其转换为一个目标姿态,并投影为2D特征,最后渲染生成最终图像(图2右)。与最近使用手工制作的可微渲染器[18,22,29,34,36,51,64]不同,HoloGAN使用投影单元[40]从头开始学习透视投影和3D特征渲染。这种新颖的架构使HoloGAN能够直接从自然图像中学习3D表征,因为其没有使用好的手工制作的可微的渲染器。为了生成相同场景的新视图,我们直接应用三维的rigid-body转换到学习的三维特征,并使用共同训练的神经渲染器可视化结果。这已被证明比在高维潜在向量空间[40]中执行3D转换产生更清晰的结果。
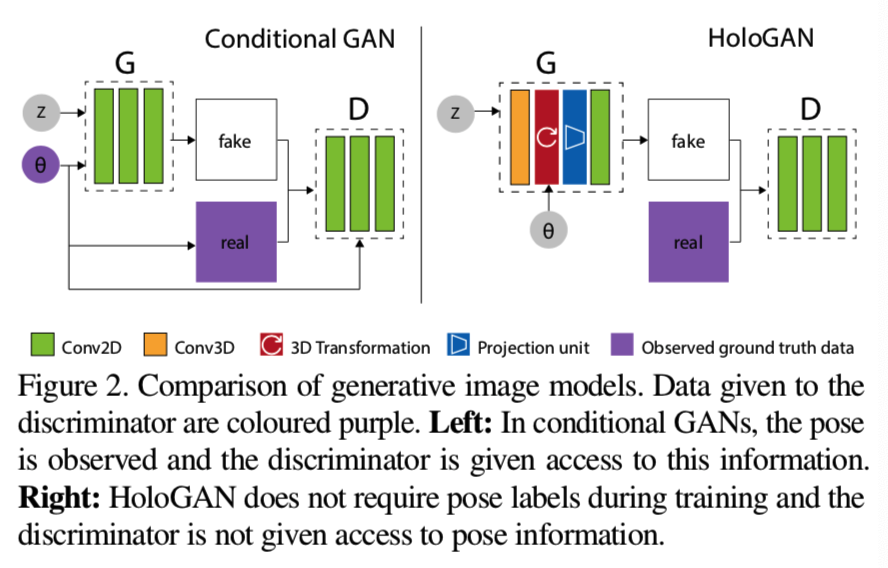
HoloGAN可以以一种无监督的方式进行端到端训练,仅使用未标记的2D图像,不需要对姿态、3D形状、对象的多视图或几何先验(如在该行业中常见的三维表征的对称性和平滑性[3,26,45])进行任何监督。就我们所知,HoloGAN是第一个可以从自然图以一个纯粹的无监督的方式直接学习3D表征的生成模型。总而言之,我们的主要技术贡献是:
- 这是一种新的结构,将关于3D世界的强归纳bias和深层生成模型结合起来,从图像中学习三维物体的解耦表征(姿态、形状和外观)。该表示在3D上是显式的,在语义上是可表达的。
- 是一个无条件的GAN,第一次允许在不牺牲视觉图像保真度的情况下支持视图操作。
- 是一种无监督的训练方法,能够在不使用标签的情况下进行解耦表征学习。
2.Related work
HoloGAN是GANs、结构感知图像合成和解耦表征学习的交叉点。在本节中,我们回顾这些领域的相关工作。
2.1. Generative adversarial networks
GANs学会将样本从任意的潜在分布映射到能够欺骗鉴别器网络将其归类为真实数据[16]的数据。最近关于GAN架构的工作集中在提高训练稳定性或生成图像的视觉保真度,如多分辨率GANs[27,61],或自我注意生成器[1,62]。然而,在设计GAN架构上要做的工作要少得多,这种架构能够实现无监督的解耦表征学习,从而能够控制生成图像的属性。通过注入随机噪声并在每次卷积时调整图像的“style”,StyleGAN[28]可以将细微的变化(如头发、雀斑)从高级特征(如姿势、身份)中分离出来,但不提供对这些元素的显式控制。Chen等人[8]提出的类似方法表明,该网络设计也获得了更强的训练稳定性。这些方法的成功表明,对于训练稳定性和图像保真度,网络结构比GAN损失的具体选择更为重要。因此,我们也专注于HoloGAN的结构设计,但目标是学习分离姿势,形状和外观,并能对这些元素进行直接操作。
2.2. 3D-aware neural image synthesis
最近在神经图像合成和新视图合成方面的工作已经发现成功地提高了三维感知网络生成的图像的保真度。使用几何模板的工作极大地提高了图像的保真度[15,32],但不能很好地推广到无法用模板描述的复杂数据集。RenderNet[40]介绍了一个使用卷积神经网络(CNN)的可微的渲染器,它可以学习直接从3D形状渲染2D图像。然而,RenderNet在训练过程中需要3D形状和相应的渲染图像。其他方法学习3D嵌入,其可用于生成相同场景的新视图,而无需任何3D监督[48,51]。然而,Sitzmann等人[51]需要多个视图和姿势信息作为输入,而Rhodin等人[48]需要对成对图像、背景分割和姿势信息的监督。视觉对象网络(VONs)[64]的目的是分离几何和纹理,首先从三维生成模型中提取三维对象样本,使用手工制作的可微层将这些对象渲染到normal, depth and silhouette maps中,最后应用一个经过训练的图像-图像转换网络。然而,VONs需要显式的3D数据来进行训练,并且只适用于简单的白色背景下的单目标图像。我们的HoloGAN也学习了一个3D表征,并渲染它产生一个2D图像,但没有使用任何3D形状,并可用于包含复杂背景和多对象场景的真实图像上。
与我们最接近的研究是Pix2Scene[45],它从图像学习隐含的3D场景表征,也是以无监督的方式。但是,这种方法将隐式表征映射到一个surfer表征以进行渲染,而HoloGAN使用带有深度voxels的显式3D表征。此外,使用手工制作的可微渲染器,Pix2Scene只能处理简单的合成图像(统一的材质和光照条件)。另一方面,HoloGAN学会了从零开始渲染,因此可以为更复杂的自然图像工作。
2.3. Disentangled representation learning
解耦表征学习的目的是学习一种因式表示,其中一个因素的变化只影响生成的图像中相应的元素,而其他因素不受影响。解耦学习中的大多数工作利用了数据集提供的标签[2,47,55],或者从集合监督中获益(例如,同一场景的视频或多幅图像;超过两个域具有相同的属性)[10,14,33]。
最近在无监督的解耦表征学习方面的努力,如β-VAE[20]或InfoGAN[9,24],主要集中在设计损失函数上。然而,这些模型对先验的选择很敏感,不能控制学习的因素,也不能保证学习的解耦因素在语义上有意义。此外,β-VAE还需要在生成图像的质量和解耦水平之间进行权衡。最后,这两种方法与更复杂的数据集(具有复杂背景和光照的自然图像)进行斗争。相比之下,通过重新设计生成器网络的架构,HoloGAN学会了成功地分离姿态、形状和外观,以及提供显式的姿态控制,实现形状/外观编辑,甚至能用于更复杂的自然图像数据集。
3. Method
为了从没有标签的二维图像中学习三维表征,HoloGAN通过引入三维世界的强归纳偏差到生成器网络中来扩展传统的无条件GANs。具体来说,HoloGAN通过学习世界的3D表征来生成图像,并将其渲染得逼真,从而欺骗了判别器。因此视图操作可以直接应用三维刚体转换到学习的三维特征来实现。换句话说,由生成器创建的图像是一个视图依赖的映射,从一个学习的3D表征到二维图像空间。这与其他GANs直接学习映射噪声矢量z到2D特征,以产生图像是不同的。
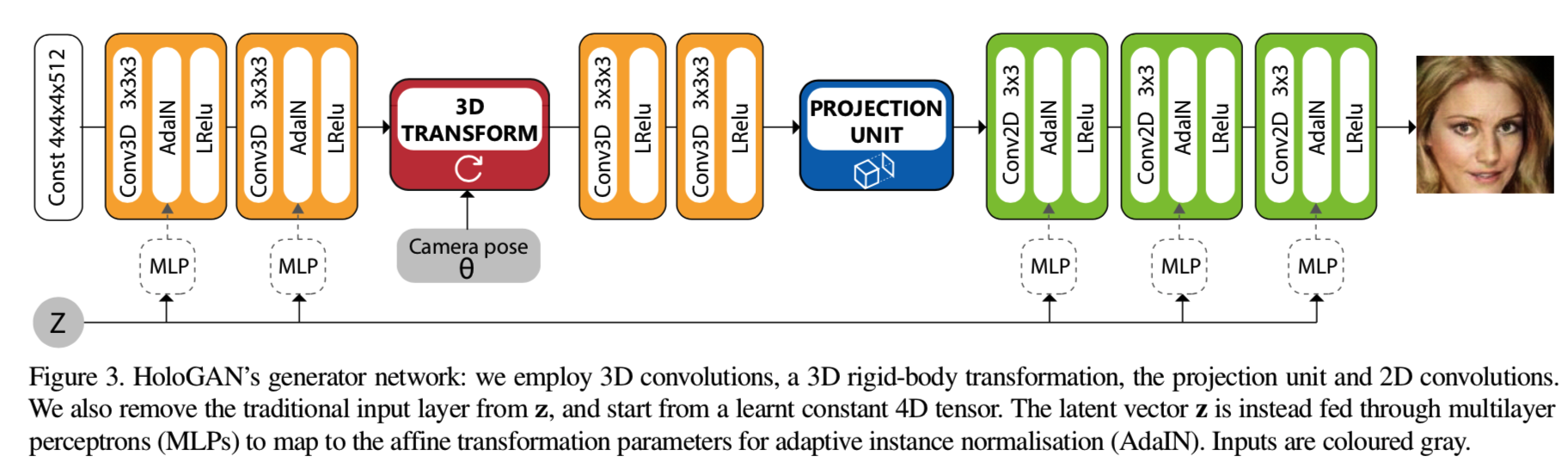
图3说明了HoloGAN生成器架构:首先HoloGAN使用3D卷积(3.1节)学习3D表征(假定为规范姿势),转换该表征为某种姿势,使用投影单元(3.2节)投射和计算能见度,并使用2D卷积计算最终图像中的每个像素的阴影颜色值。HoloGAN与RenderNet[40]分享了许多渲染的见解,不同在于HoloGAN可以处理自然图像,不需要预先训练的神经渲染器,也不需要配对的3D形状-2D图像训练数据。
在训练期间,我们从一个均匀分布采样随机姿势和使用这些姿势转换三维特征,然后将它们渲染成图像。我们假设每幅图像都有一个相应的全局姿态(pose),并证明这个假设仍然适用于多目标的图像。这种随机的姿态扰动促使生成器网络学习一种解耦表征,这种表征既适用于三维变换,也适用于生成可以欺骗判别器的图像。虽然姿态转换可以从数据中学习,但我们在HoloGAN中提供了一个可微的且能直接显示实现的操作。使用显式rigid-body转换的新视图合成已证明能产生更清晰的图像与更少的伪影[40]。更重要的是,这提供了一个能与显式3Drigid-body转换兼容的归纳偏差。因此,学习的表征在三维是显式的,并解开了姿态和身份之间的耦合。
Kulkarni等人[33]将学习到的解耦表征分为内在元素和外在元素。内在元素描述形状、外观等,外在元素描述姿态(立面、方位角)和光照(位置、强度)。HoloGAN的设计通过使用更多关于3D世界的归纳偏差,自然有助于这种分离:采用native 3D转换,来直接控制姿势(即θ,如图3所示)到学习到的3D特征,用来控制身份(即z,如图3所示)。
3.1. Learning 3D representations
HoloGAN从一个学习到的常量张量中生成3D表示(见图3的4x4x4x512)。随机噪声向量z被当作一个“style”控制器,并在每次卷积后使用多层感知器(MLP)![]() 将z映射到仿射参数,用于自适应实例归一化(AdaIN)[21]。
将z映射到仿射参数,用于自适应实例归一化(AdaIN)[21]。
给定一个图像x层![]() 的一些特征
的一些特征![]() ,和噪音“style”向量z,AdaIN可定义为:
,和噪音“style”向量z,AdaIN可定义为:
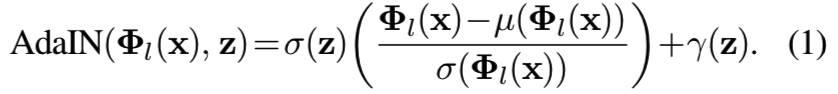
其中μ()为计算均值, σ()为计算标准差
这可以看作是通过一个模板(学习的常量张量,即图3的4x4x4x512)的变换来生成图像,使用AdaIN来匹配训练图像不同级别![]() (被认为用来描述图像“style”)特征的均值和标准偏差。通过实验,我们发现这种网络结构比直接将噪声向量z输入到第一层生成器的网络结构能更好地分离姿态和身份。
(被认为用来描述图像“style”)特征的均值和标准偏差。通过实验,我们发现这种网络结构比直接将噪声向量z输入到第一层生成器的网络结构能更好地分离姿态和身份。
HoloGAN从StyleGAN[28]继承了这种基于style的策略,但在两个重要方面有所不同。HoloGAN首先从一个学习过的4D常数张量(大小为4×4×4×512,最后一个维度为特征通道)中学习三维特征,然后将其投影到二维特征中生成图像,而StyleGAN只学习二维特征。其次,HoloGAN在训练中通过将三维特征与rigid-body变换相结合来学习一种解耦的表征,而StyleGAN则在每个卷积中注入独立的随机噪声。因此,StyleGAN学会了根据特征分辨率将2D特征分割成不同层次的细节,从粗糙的(如姿势、身份)到更精细的细节(如头发、雀斑)。我们在HoloGAN观察到类似的分离。然而,HoloGAN进一步分离了姿势(由3D变换控制)、形状(由3D特征控制)和外观(由2D特征控制)。
值得强调的是,为了生成128×128(与VON相同)的图像,我们使用了尺寸为16×16×16×64的深度3D表示。即使在如此有限的分辨率下,比其他使用全三维几何的方法,如分辨率为128×128×128×1的VON网格[64],HoloGAN仍然可以生成具有竞争力的质量和更复杂的背景的图像。
3.2. Learning with view-dependent mappings
除了使用3D卷积来学习3D特征之外,在训练过程中,我们通过将这些学习到的特征转化为随机姿态,再投影到2D图像中,从而引入更多关于3D世界的偏差。正如DR-GAN中的Tran等人[55]所观察到的那样,这种随机姿势变换对于保证HoloGAN学习出一种可以从所有可能的视图中分解和渲染的3D表征是至关重要的。然而,HoloGAN执行显式的3D rigid-body转换,而DR-GAN使用隐式的向量表征来执行此转换。
Rigid-body transformation. 我们假设一个虚拟针孔 摄像机相对于被渲染的3D特征处于标准姿态(轴对齐并沿负z轴放置)。我们通过三维旋转、缩放和三线性重采样来参数化rigid-body变换。尽管我们的框架在本质上支持翻译,但我们没有在这项工作中使用它。假设物体坐标系的上向量为全局y轴,旋转包括围绕y轴(方位角)和x轴(仰角)的旋转。姿态采样范围的详细信息包括在补充文件中。
Projection unit. 为了从二维图像中学习有意义的三维表示,HoloGAN学习了一个可微投影单元[40],它可以在遮挡下推理。特别地,投影单元接收一个4D张量(3D特征),并返回一个3D张量(2D特征)。由于训练图像是用不同的视角捕捉的,因此HoloGAN需要学习视角投影。
然而,由于我们不了解相机特性,所以我们使用了两层3D卷积(没有AdaIN)在3D表示投影到2D特征之前将其变形为透视frustum(即图3红色和蓝色中间的两层卷积)。
投影单元由一个g层组成,该reshapin层将通道维与深度维连接起来,从而将张量维从4D(W×H×D×C)降为3D(W×H×(D·C)),以及一个带有非线性激活函数(该实验中使用的是leakyReLU[37])的MLP来学习遮挡。
3.3. Loss functions
Identity regulariser. 为了生成高分辨率图像(128×128像素),我们发现增加身份规范Lidentity有利于确保一个从生成图像中重建的向量与使用在生成器G中的潜在向量z相匹配 。我们发现其仅鼓励HoloGAN在姿势多种多样时,使用用于身份的z去保持对象的身份,帮助模型学习数据集中姿势的全部变量。我们引入了一个编码器网络F,它与判别器共享大部分卷积层,但使用一个额外的全连接层来预测重构的潜在向量。身份损失为:
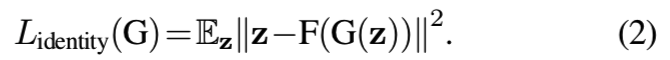
Style discriminator . 我们的生成器设计去匹配不同层次的训练图像的“style”,有效地控制不同尺度的图像属性。因此,除了能够区分真假图像的图像判别器之外,我们还提出了在特征水平上执行相同任务的多尺度风格鉴别器。特别是,风格判别器试图将均值μ(Φl)和标准差σ(Φl)分类,它们用来描述图像“style”[21]。经验上,多尺度风格识别器有助于防止模式崩溃,并实现长时间训练。给定层![]() 的style判别器
的style判别器![]()
![]() ,style损失定义为:
,style损失定义为:
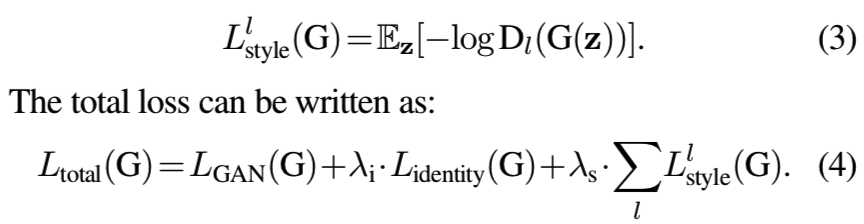
其中所有实验使用![]() 。LGAN使用的是DC-GAN[44]的GAN损失
。LGAN使用的是DC-GAN[44]的GAN损失
4. Experiment settings
Data. 我们使用各种数据集训练HoloGAN: Basel Face [42], CelebA [35], Cats [63], Chairs [7], Cars [58], 和 LSUN bedroom [59]。对Cats和Chairs我们训练HoloGAN的分辨率为64×64像素,对于Basel Face, CelebA, Cars 和 LSUN bedroom分辨率为128×128像素。关于数据集和网络架构的更多细节可以在补充文档中找到。
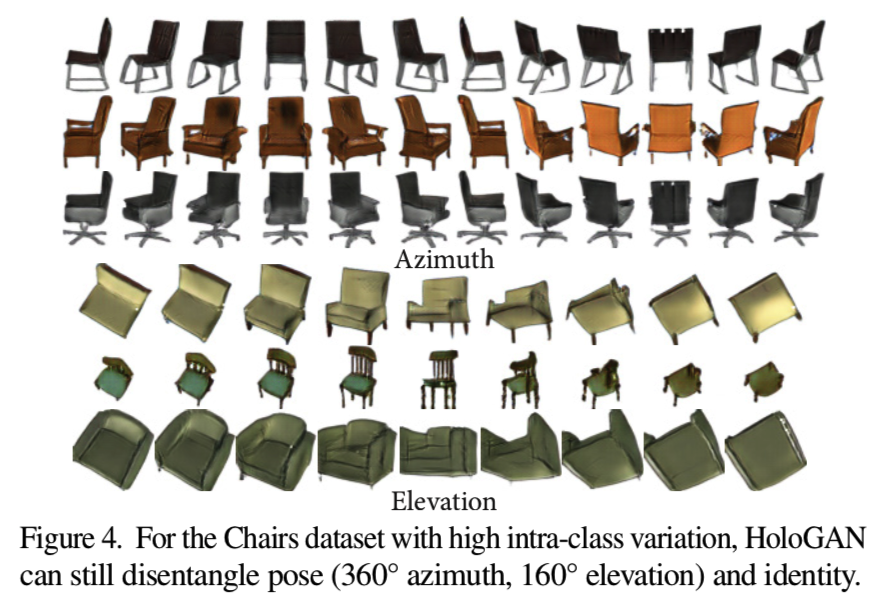
注意,只有Chairs数据集包含同一对象的多个视图;所有其他数据集只包含唯一的单个视图。对于这个数据集,由于ShapeNet [7] 3D椅子模型(6778个形状)的数量有限,我们为每把椅子从60个随机抽样视图中渲染图像。在训练过程中,我们确保每一batch椅子都包含着完全不同类型的椅子,防止网络使用set监督,即在同一批椅子中从不同的角度看同一把椅子,来进行作弊。
Implementation details. 生成器采用自适应实例归一化(AdaIN)[21],判别器采用实例归一化[56]和光谱归一化[39]相结合的方法。详见我们的补充文件。
我们使用Adam求解器[31]从头开始训练HoloGAN。为了在训练期间生成图像,对![]() 进行采样,也从均匀分布中采样随机姿势(更多关于姿态采样的细节可以在补充文档中找到)。我们对所有数据集使用|z| = 128,除了128x128的Cats数据集,其我们使用|z| = 200。
进行采样,也从均匀分布中采样随机姿势(更多关于姿态采样的细节可以在补充文档中找到)。我们对所有数据集使用|z| = 128,除了128x128的Cats数据集,其我们使用|z| = 200。
5. Results
我们首先展示HoloGAN在复杂性的增加的数据集上的定性结果(第5.1节)。其次,我们提供了定量证据,表明HoloGAN能够比其他基于2D的GAN模型生成具有可比或更高视觉保真度的图像(章节5.2)。我们还展示了使用我们学习的3D表征进行图像生成的有效性(第5.3节),与显式的3D几何图形(二进制voxel网格)作比较。然后我们展示HoloGAN如何学习解耦形状和外观(第5.4节)。最后,我们进行消融研究,以证明我们的网络设计和训练方法的有效性(第5.5节)。
5.1. Qualitative evaluation
从图1、图4、图6和图7b可以看出,HoloGAN可以在多个不同数据集保持相同身份的情况下,沿方位角和仰角平滑地改变姿态。请注意,LSUN数据集包含多个对象的各种复杂布局。这使得它成为一个非常具有挑战性的数据集,学习从对象身份的姿态。
在补充文档中,我们展示了Basel Face数据集的结果。在保持姿态不变的情况下,利用噪声向量进行线性插值,证明了HoloGAN能够平滑地插值两个样本的身份。这表明,尽管在训练中没有看到任何姿势标签或3D形状,但HoloGAN正确地学习了明确的深层3D表示,将姿势与身份分离。


Comparison to InfoGAN [9]. 在从分辨率为64×64像素的CelebA数据集[35]上学习从姿态中分离身份的任务中,我们将我们的方法与InfoGAN方法相对比。由于该数据缺乏公开可用的代码和超参数,我们使用已发表论文中的CelebA数字。我们也在Cars数据集上尝试了官方的InfoGAN实现,但无法成功地训练模型,因为InfoGAN似乎对先验分布的选择和要恢复的潜在变量的数量高度敏感。
从图5可以看出,HoloGAN成功地恢复了,并且在保持生成图像中目标的身份的同时,对方位角提供了更好的控制。HoloGAN还可以恢复仰角高度(图6b,右),尽管在CelebA数据集中仰角变化有限,但InfoGAN不能变化仰角。最重要的是,不能保证InfoGAN总是恢复控制对象姿态的因素,而HoloGAN通过rigid-body变换显式地控制了这一点。

5.2. Quantitative results
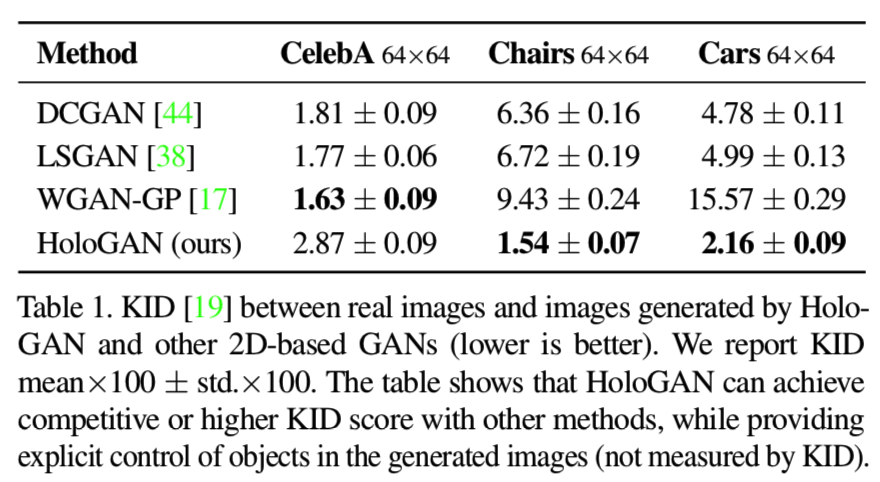
为了评估生成图像的视觉保真度,我们使用 Bin ́kowski et al. [4]的Kernel Inception Distance (KID)进行评估。KID计算真实图像和生成图像的特征表示(从Inception模型[53]开始计算)之间的最大平均差异平方。与FID[19]相比,KID有一个无偏估计量。KID得分越低,生成的图像的视觉质量越好。在表1中的3个数据集上,我们将HoloGAN与其他最近的GAN模型:DCGAN[44]、LSGAN[38]和WGAN-GP[17]进行了比较。注意,KID没有考虑特征的分离,这是HoloGAN的一个主要贡献。
我们使用了一个公开可用的实现,并对所有三个数据集使用了该实现提供的相同的超参数(为CelebA调优)。同样,对于HoloGAN,我们对所有三个数据集使用相同的网络架构和超参数。我们从每个模型中抽取20,000张图片来计算KID的分数,如下所示。
表1显示,HoloGAN可以在更具挑战性的数据集,如Chairs(具有较高的类内差异性)和Cars(具有复杂的背景和光照条件),上生成具有竞争性(对于CelebA)或甚至更好的KID得分的图像。这也表明,HoloGAN架构具有更强的鲁棒性,能够在不同数据集之间以相同的超参数集(除了方位角范围)一致地生成高视觉逼真度的图像。我们在补充文档中包含了这些模型的可视化示例。更重要的是,HoloGAN学会了一种允许对生成图像进行操作的不纠缠表示。这是一个巨大的优势,与β-VAE[20]这样的方法相比,后者必须在图像质量和已学会特征的解纠缠程度之间做出妥协。
5.3. Deep 3D representation vs. 3D geometry
在此,我们在生成汽车图像的任务上将我们的方法与最先进的视觉对象网络(VON)[64]进行比较。我们使用作者提供的训练过的模型和代码。虽然VON也采用了一种分离的方法来生成图像,但它在训练中依赖于3D形状和silhouette masks,而HoloGAN没有。图7b显示,我们的方法可以生成具有复杂背景、真实阴影和具有竞争性的视觉保真度的汽车图像。请注意,为了生成128×128的图像,VON使用128×128×128×1分辨率的全二进制voxel几何,而HoloGAN使用高达16×16×16×16×64分辨率的深度voxel表示,这在空间上更加紧凑和富有表现力,因此HoloGAN可以生成复杂的背景和阴影。如图7a中着重标明的(红色线)结果,VON也倾向于改变汽车的身份,比如在某些视图改变颜色或形状,而HoloGAN则保持汽车在所有视图中的身份。此外,HoloGAN可以在360度视图下生成汽车图像(图7),而VON在从后面视图生成图像中效果不好。
传统的voxel网格会占用大量内存。HoloGAN暗示了使用显式的深度voxel表示来生成图像的巨大潜力,而不是在传统的渲染管道中使用完整的3D几何图形。例如,在图6c中,我们使用16×16×16×64分辨率的3D表示来生成整个卧室场景的图像。
5.4. Disentangling shape and appearance
这里我们展示了除了姿势之外,HoloGAN还学会了将身份进一步划分为形状和外观。我们抽取了两个潜在代码z1和z2,并输入到HoloGAN。z1控制3D特性(在透视变形和投影之前),z2控制2D特性(在投影之后)。图8显示了具有相同姿势的生成图像,他们有相同的z1,但是每行有不同的z2。可以看到,3D特性控制对象的形状,而2D特性控制外观(纹理和照明)。这表明,通过使用3D卷积来学习3D表示,使用2D卷积来学习阴影,HoloGAN学会了直接从未标记的图像中分离形状和外观,允许单独操作这些因素。在补充文档中,我们提供了进一步的结果,在这些结果中,我们为不同分辨率的3D特征使用了不同的潜在代码,并展示了控制整体形状的特征和更细粒度的细节(如性别或妆容)之间的分离。

5.5. Ablation studies
我们现在进行了一系列的研究,以证明我们的网络设计和训练方法的有效性。
Training without random 3D transformations. 对于HoloGAN来说,在训练过程中随机旋转3D特征是至关重要的,因为它可以鼓励生成器学习姿态和身份之间的一种不耦合的表征。在图9中,我们显示了在训练期间使用和不使用3D转换的结果。对于未经三维变换训练的模型,我们在模型训练完成后,通过人工旋转学习到的三维特征来生成旋转后的物体图像。可以看出,该模型仍然可以生成视觉逼真度较好的图像,但是当姿态发生变化时,完全不能生成有意义的图像,而HoloGAN可以很容易地生成相同物体在不同姿态下的图像。我们相信,训练期间的随机变换迫使生成器学习有意义的经过几何变换的特征,同时仍然能够生成可以欺骗鉴别器的图像。因此,我们的训练策略鼓励HoloGAN学习身份和姿态的一种解耦的表征。

Training with traditional z input. 通过从一个学习好的常数张量开始,并使用噪声向量z作为不同级别的“style”控制器,HoloGAN可以更好地从身份中分离出姿势。这里我们执行另一个实验,我们将z输入到生成器网络的第一层,就像其他GAN模型一样。从图9可以看出,使用传统输入训练的模型混淆了姿势和身份。因此,当物体旋转时,模型也会改变物体的身份,而HoloGAN可以沿方位角平滑地改变姿态并保持身份不变。
一项额外的消融研究显示身份调节器的有效性,其包括在补充文件中。
6. Discussion and conclusion
虽然HoloGAN能够成功地学会从身份中分离出姿势,但它的表现取决于训练数据集中所包含的姿态的变化和分布。例如,对于CelebA和Cats数据集,模型无法恢复仰角和方位角(见图6a,b),因为大多数人脸图像是在眼睛水平面上拍摄的,因此只包含有限的仰角变化。使用错误的姿势分布也可能导致角度映射错误。目前,在训练过程中,我们从均匀分布中随机采样。因此,未来的工作可以探索以无监督的方式从训练数据中学习姿态分布,以解释不均匀的姿态分布。其他的探索方向包括进一步解耦物体的外观,如纹理和光照。最后,将HoloGAN与训练技术(如progressive GANs[27])结合起来生成更高分辨率的图像将是很有趣的。
在这项工作中,我们展示了HoloGAN,一个生成图像模型,通过对3D世界采用强归纳偏差,以无监督的方式从自然图像中学习3D表征。HoloGAN可以用未标记的2D图像进行端到端训练,并学会分解具有挑战性的因素,如3D姿态、形状和外观。这种分离提供了对这些因素的控制,同时能够生成与基于2D的GANs类似或更高的视觉质量的图像。我们的实验表明,HoloGAN成功地在不同复杂度的多个数据集上学习有意义的3D表征。因此,我们确信,与现有的显式(meshs、voxels)或隐式[14,45]3D表征相比,显式深度3D表征对于GAN模型的可解释性和可控性都是至关重要的一步。