参考:https://gitee.com/milkboy_lyf/learn-to-cluster/tree/master/vegcn
Learning to Cluster Faces via Confidence and Connectivity Estimation
Abstract
人脸聚类是挖掘未标记人脸数据的重要工具,在人脸标注和人脸检索等方面有着广泛的应用。最近的研究表明,有监督的聚类可以显著提高性能。然而,它们通常涉及启发式步骤,并需要大量重叠的子图,严重限制了它们的准确性和效率。在本文中,我们提出了一个完全可学习的聚类框架,而不需要大量的重叠子图。相反,我们将聚类问题转化为两个子问题。具体来说,我们设计了两个图卷积网络,分别为GCN-V和GCN-E,分别用来估计顶点的置信度和边的连通性。利用顶点置信度和边连通性,我们可以在连通图上自然地组织更多相关的顶点,并将它们分组到一个集群。在两个大规模基准上的实验表明,我们的方法显著提高了聚类精度,从而提高了在上面训练的识别模型的性能,且它比现有的监督方法的效率高了一个数量级。
1. Introduction
由于带注释的人脸数据集的爆炸式增长[19,11,17],近年来人脸识别取得了很大的进展[31,27,33,7,40]。随着这种趋势,对注释数据的需求日益增长,导致了过高的注释成本。为了利用大量未标记的人脸图像,最近的研究[14,39,35,38]提供了一种有前景的基于聚类的pipelline,并证明了其在改进人脸识别模型方面的有效性。他们首先进行聚类,为未标记的图像生成“伪标签”,然后利用它们以监督的方式训练模型。这些方法成功的关键在于一种有效的人脸聚类算法。
现有的人脸聚类方法大致分为两类,即无监督方法和有监督方法。无监督方法,如K-means[22]和DBSCAN[9],依赖于特定的假设,缺乏处理真实数据集中复杂的集群结构的能力。为了提高对不同数据的适应性,已经提出了监督聚类方法[35,38]来学习聚类模式。然而,准确性和效率都远不能令人满意。特别是,为了使用大规模的人脸数据聚类,现有的监督方法用许多小的子图来组织数据,导致两个主要问题。首先,处理子图涉及基于简单假设的启发式步骤。子图生成[38]和预测聚合[35]都依赖于启发式过程,从而限制了它们的性能上限。此外,这些方法所需的子图通常高度重叠,导致过多的冗余计算成本。
因此,我们寻求一种算法,学习更准确和有效的聚类方法。为了获得更高的准确性,我们希望框架的所有组件都是可学习的,超越启发式程序的限制。另一方面,为了减少冗余计算,我们打算减少所需的子图的数量。先前的研究[39,35,38]表明,在一个连通图上的集群通常具有一些结构模式。我们观察到这种结构模式主要来源于顶点和边。直观地说,就是将每个顶点连接到一个对属于某个特定类有较高的置信度的邻居上,这样可以从连通图中推导出许多树。获得的树自然地将相互连接的组件作为了集群。基于这一动机,我们设计了一种完全可学习的聚类方法,不需要大量的子图,从而得到更准确且有效的效果
特别地,我们将聚类问题转化为两个子问题。一种是估计一个顶点的置信度,它衡量一个顶点属于一个特定类的概率。另一种是估计边的连通性,即两个顶点属于同一类的概率。通过顶点置信度和边连通性,我们以一种自然的方式进行聚类,即每个顶点连接到一个具有更高置信度和最强连通性的顶点。如图1所示,每个顶点都找到一条连接到具有更高置信度的顶点的边,最后连接到同一顶点的顶点属于同一集群。
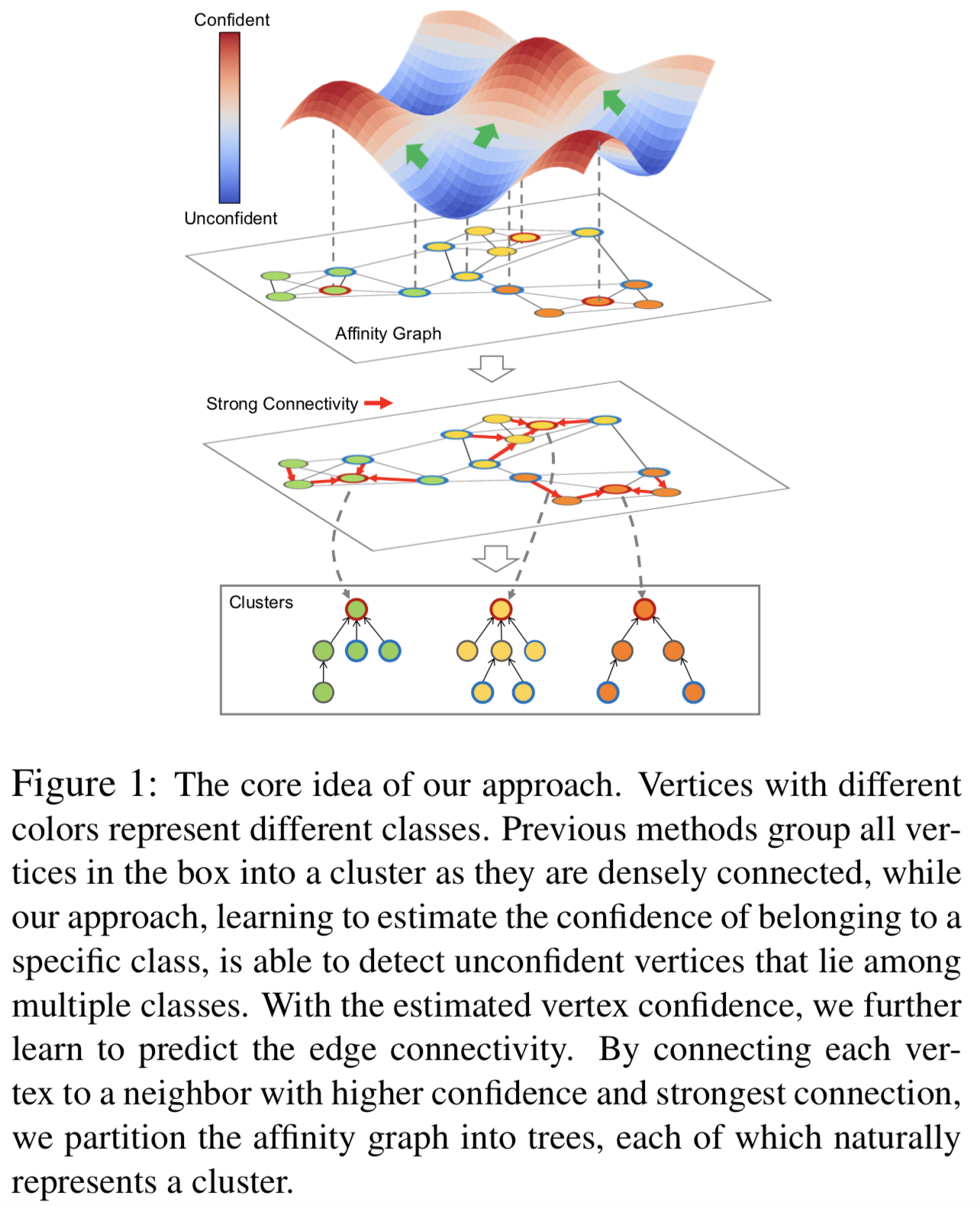
提出了两个可学习组件,即置信估计器和连通性估计器,分别用来估计顶点置信和边的连通性。这两个组件都基于一个GCN去从数据中学习,表示为GCN-V(顶点置信度)和GCN-E(边连通性)。具体来说,GCN-V以整个图为输入,同时估计所有顶点的置信度。GCN-E以局部候选集构造的图作为输入,计算属于同一类的两个顶点的可能性。
实验表明,我们的方法不仅比现有监督方法快了一个数量级,而且在500万未标记数据的两个F-score指标下,也优于最先进的方法[38]。主要贡献在于三个方面:(1)我们提出了一种新的聚类框架,该框架将聚类定义为一种基于可学习组件的置信度和连通性估计。我们的方法比现有的基于学习的方法快一个数量级。(3)该方法在大规模人脸聚类和fashion聚类方面均达到了最先进的性能。这些被发现的集群将人脸识别模型提升到一个可以与有监督的对照方法相媲美的水平。
2. Related Work
Unsupervised Face Clustering. 随着深度学习的出现,最近的研究主要采用了基于CNN的模型的深度特征,并着重于相似性度量的设计。Otto等人[1]提出了一种approximate rank-order 度量。Lin等人[20]引入minimal covering spheres of neighborhoods作为相似性度量。除了专门针对人脸聚类设计的方法外,经典的聚类算法也可以应用于人脸聚类。基于密度的聚类是最相关的方法。DB-SCAN[9]计算经验密度,将集群指定为数据空间中的密集区域。OPTICS[3]采用了类似的概念,并解决了数据点的排序问题。
我们的方法与基于密度的聚类方法有共同的直觉,即计算每个样本[9]的“密度”,关注样本[3]之间的相对顺序。然而,我们的方法与上面所有的无监督方法有本质上的不同:我们框架中的所有组件都是可学习的。这让我们学会了捕捉人脸集群的内在结构。
Supervised Face Clustering. 最近的研究表明,在人脸聚类中引入监督信息可以带来相当可观的性能提高。Zhan等人[39]训练了MLP分类器来聚合信息,从而发现更稳健的连接。Wang等人[35]利用GCN捕获图上下文信息,进一步改进了连接预测。这两种方法都是通过寻找具有动态阈值的连接组件来获得聚类。Yang等人[38]设计了一种分区算法来生成多尺度子图,并提出了一个两阶段监督框架来从中找出所需的集群。
虽然本文提出的方法采用了监督聚类的思想,但它在两个关键方面有所不同:(1)与以往的监督聚类方法[39,35,38]不同,它不依赖启发式算法进行预处理或后处理。相反,该框架的所有组件都是可学习的,并有可能实现更高的精度。(2)它在设计上更有效率。现有的方法依赖于大量的子图来精确定位集群。[35]预测了每个顶点周围的所有连接,其中两个相邻的顶点可能有高度重叠的邻域,因此有冗余的计算成本。[38]产生了用于检测和分割的多尺度子图,其数量通常是聚类数量的数倍。相比之下,该方法采用一种有效的subgraph-free策略来估计顶点置信度,并集中在一小部分邻域上进行连通性预测。
Graph Convolutional Networks. 图卷积网络(Graph Convolutional Networks, GCNs)[18]已经成功应用于各种任务中[18,12,32,37,36]。最近的一些工作将GCN扩展到处理大规模图上。GraphSAGE[12]在每一层中采样固定数量的邻居进行聚合。FastGCN[4]通过采样顶点而不是邻居来进一步降低计算成本。本文利用图卷积网络的强大表达能力,学习大量连通图上的顶点置信度和局部子图上的边连通性。
3. Methodology
在大规模人脸聚类中,监督方法在处理复杂的聚类模式方面表现出了有效性,但其准确性受到一些手工制作组件的限制,其效率受到大量高度重叠子图的要求限制。因此,如何准确有效地聚类仍然是一个问题。为了应对这一挑战,我们提出了一种有效的替代方案,其中所有组件都是可学习的。具体来说,我们将聚类定义为估计一个连通图上顶点的置信度和边的连通性的过程,然后通过将每个顶点连接到具有较高置信度和连通性的邻居来将图划分成集群。
3.1. Framework Overview
给定一个数据集,我们从一个学习好的CNN网络抽取每张图的特征,生成特征集![]() ,其中
,其中![]() 。N是图像的数量,D表示特征的维度。样本i和样本j之间的连通性表示为
。N是图像的数量,D表示特征的维度。样本i和样本j之间的连通性表示为![]() ,其是特征
,其是特征![]() 和
和![]() 之间的cosine相似度。根据该连通值,我们使用KNN连通图
之间的cosine相似度。根据该连通值,我们使用KNN连通图![]() 表示数据集,其中每张图是属于
表示数据集,其中每张图是属于![]() 的顶点,并与其K个最近邻相关联,生成属于
的顶点,并与其K个最近邻相关联,生成属于![]() 的K条边。构造的图可被表示为一个顶点特征矩阵
的K条边。构造的图可被表示为一个顶点特征矩阵![]() 和一个对称邻接矩阵
和一个对称邻接矩阵![]()
![]() ,当
,当![]() 和
和![]() 不相连时,
不相连时,![]()
为了通过学习顶点和边的结构模式来进行聚类,我们将聚类分解为两个子问题。一个是预测顶点的置信度。置信度是用来确定一个顶点是否属于一个特定的类的。直观地说,一个高置信度的顶点通常位于属于同一类的顶点密集分布的地方,而低置信度的顶点可能位于几个集群的边界上。另一个是预测边连通性的子问题。连接度高的边表明两个连通样本往往属于同一类。利用连通图中的顶点置信度和边连通性,可以通过寻找从低置信度顶点到高置信度顶点的有向路径来实现聚类。这个过程自然地形成了许多相互隔离的树,从而很容易地将图划分为集群。我们将此过程称为基于树的分区。
该方法的关键挑战仍然是如何估计顶点置信度和边连通性。如图2所示,我们的框架由两个可学习的模块组成,即置信度估计器(Confidence Estimator)和连通性估计器(Connectivity Estimator)。前者基于GCN-V估计顶点置信度,后者基于GCN-E预测边连通性。具体来说,GCN-V以整个连通图为输入,同时估计所有顶点的置信度。GCN-E以候选集构造的图作为输入,计算属于同一类的两个顶点的置信度。根据这两个模块的输出,我们进行了基于树的划分来获取集群。

3.2. Confidence Estimator
类似于目标检测[41,8]的anchor-free方法,他们使用的热图来表示一个对象出现在图像的相应区域的可能性,置信度估计旨在为每个顶点估计一个值,从而指示在连通图的相应区域中是否有一个特定的类。
由于真实世界的数据集通常有很大的类内变化,每幅图像可能有不同的置信度值,即使它们属于同一类。对于高置信度的图像,其相邻的图像往往属于同一类,而低置信度的图像通常与其他类的图像相邻。在此基础上,我们可以根据邻域内的有标签的图像定义每个顶点的置信度![]() :
:
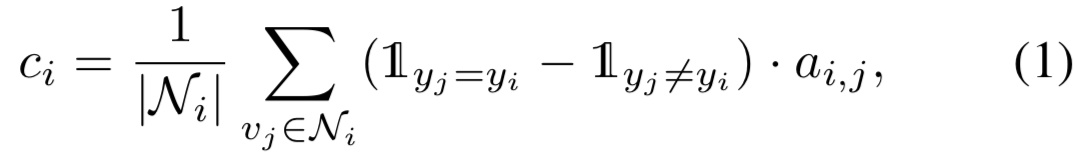
其中![]() 是
是![]() 的邻域,
的邻域,![]() 是
是![]() 的ground truth标签,
的ground truth标签,![]() 是
是![]() 和
和![]() 之间的连通值。置信度衡量邻居是否靠近,且是否来自同一个类。从直观上看,有着密集且纯连接的顶点有着较高的置信度,而连接稀疏或位于多个集群之间边界的顶点有较低的置信度。我们在第4.3.1节研究了一些不同的置信度设计。
之间的连通值。置信度衡量邻居是否靠近,且是否来自同一个类。从直观上看,有着密集且纯连接的顶点有着较高的置信度,而连接稀疏或位于多个集群之间边界的顶点有较低的置信度。我们在第4.3.1节研究了一些不同的置信度设计。
Design of Confidence Estimator. 我们假设具有相似置信度的顶点具有相似的结构模式。为了捕获这些模式,我们学习了一个图卷积网络[18],命名为GCN-V,来估计顶点的置信度。具体来说,给定邻接矩阵![]() 和顶点特征矩阵
和顶点特征矩阵![]() 作为输入,GCN预测每个顶点的置信度。GCN由
作为输入,GCN预测每个顶点的置信度。GCN由![]() 层组成,每层的计算公式为:
层组成,每层的计算公式为:
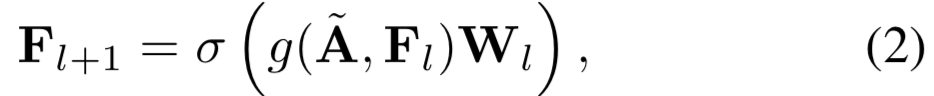
其中![]() 是一个对角degree矩阵。输入层的特征嵌入
是一个对角degree矩阵。输入层的特征嵌入![]() 即输入特征矩阵
即输入特征矩阵![]() ,
,![]() 即第
即第![]() 层嵌入。
层嵌入。![]() 是将嵌入转换到新空间的可学习矩阵。
是将嵌入转换到新空间的可学习矩阵。![]() 为非线性激活函数(这里使用的是ReLU)。为了利用输入的嵌入和邻域聚合后的嵌入去学习转换矩阵,定义
为非线性激活函数(这里使用的是ReLU)。为了利用输入的嵌入和邻域聚合后的嵌入去学习转换矩阵,定义![]() 为两者的串联:
为两者的串联:
![]()
这样的定义已经被证明比简单地对每个顶点[35]周围的邻居嵌入特征进行加权平均更有效。基于第![]() 层的输出嵌入,即
层的输出嵌入,即![]() ,我们使用一个全连接层来预测顶点的置信度:
,我们使用一个全连接层来预测顶点的置信度:
![]()
其中![]() 可训练的回归量,
可训练的回归量,![]() 是可训练的偏差。
是可训练的偏差。![]() 预测的置信度就是
预测的置信度就是![]() 的对应元素,即
的对应元素,即![]() 。
。
Training and Inference. 给定有着类标签的训练集,我们可以遵循等式(1)为每个顶点获得ground truth置信度。然后我们使用目标函数去最小化ground truth和预测置信度分数之间的均方差(MSE)来训练GCN-V,定义如下:
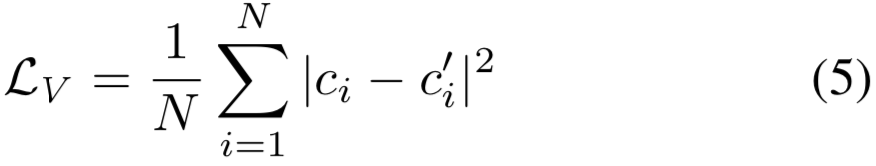
在推理时,我们使用训练好的GCN-V去预测每个顶点的置信度。获得的置信度使用在如下两处:首先,它们被用于下一个模块,以确定是否需要预测某条边的连通性,从而显著降低了计算成本。此外,它们被用于最终的聚类,以提供顶点之间的部分顺序。
Complexity Analysis. 主要的计算开销与图卷积相关(等式(2))。因为构造的图是KNN图,且![]() ,连通矩阵
,连通矩阵![]() 是一个高度稀疏矩阵。因此,因此,图卷积可以有效地实现为稀疏-密集矩阵乘法,复杂度为
是一个高度稀疏矩阵。因此,因此,图卷积可以有效地实现为稀疏-密集矩阵乘法,复杂度为![]() [18]。稀疏矩阵的边
[18]。稀疏矩阵的边![]() 的数量以NK为界,当顶点数量为
的数量以NK为界,当顶点数量为![]() 时,测试复杂度是线性的。
时,测试复杂度是线性的。
这个操作可以通过抽样邻居或抽样顶点来扩展到一个非常大的设置[12,4]。根据经验,一个1层的GCN需要37G CPU Ram,使用16个CPU在一个有5.2M顶点的图上进行推理需要92秒。
3.3. Connectivity Estimator
对于顶点![]() ,置信值大于
,置信值大于![]() 的邻居表示它们对自己属于某个特定类更有信心。为了将
的邻居表示它们对自己属于某个特定类更有信心。为了将![]() 分配给一个特定的类,一个直观的想法是将
分配给一个特定的类,一个直观的想法是将![]() 与来自同一个类的更高置信度的邻居连接起来。然而,更高置信度的邻居并不一定属于同一类。因此,我们引入连通估计器GCN-E,来度量基于局部图结构的成对关系。
与来自同一个类的更高置信度的邻居连接起来。然而,更高置信度的邻居并不一定属于同一类。因此,我们引入连通估计器GCN-E,来度量基于局部图结构的成对关系。
Candidate set. 给定预测顶点置信度,我们首先为每个顶点构造一个候选集![]() :
:
![]()
候选集的目标是挑选连接 对属于一个集群有更高的置信度的邻居 的边,![]() 仅包含有着比
仅包含有着比![]() 置信度更高的置信度的顶点。
置信度更高的置信度的顶点。
Design of Connectivity Estimator. GCN-E和GCN-V有相似的GCN结构。主要区别在于:(1)GCN-E的输入不是整个图![]() ,而是一个包含
,而是一个包含![]() 中所有顶点的子图
中所有顶点的子图![]() ; (2) GCN-E为
; (2) GCN-E为![]() 上的每个顶点输出一个值,表示它与
上的每个顶点输出一个值,表示它与![]() 为同一个类的可能性有多大。
为同一个类的可能性有多大。
具体来说,子图![]() 可以使用连通矩阵
可以使用连通矩阵![]() 和顶点特征矩阵
和顶点特征矩阵![]() 表示。我们将特征矩阵
表示。我们将特征矩阵![]() 的每一行特征减去特征
的每一行特征减去特征![]() ,用减后的特征去编码
,用减后的特征去编码![]() 和
和![]() 之间的关系,减后得到的特征矩阵表示为
之间的关系,减后得到的特征矩阵表示为![]() 。因此,GCN-E的转换可表示为:
。因此,GCN-E的转换可表示为:
![]()
其中![]() 、
、![]() 和
和![]() 的定义和等式(2)相同。
的定义和等式(2)相同。![]() 是GCN-E第
是GCN-E第![]() 层的参数。基于第
层的参数。基于第![]() 层的输出嵌入,我们使用一个全连接层获得
层的输出嵌入,我们使用一个全连接层获得![]() 中每个顶点的连通值。连通值反映了两个顶点之间的关系,我们使用
中每个顶点的连通值。连通值反映了两个顶点之间的关系,我们使用![]() 表示
表示![]() 和
和![]() 的预测连通值
的预测连通值
Training and Inference. 给定有着类标签的训练集,对于顶点![]() ,其邻居
,其邻居![]() 和
和![]() 有着相同的类,那么其连通值设置为1,否则设置为0:
有着相同的类,那么其连通值设置为1,否则设置为0:
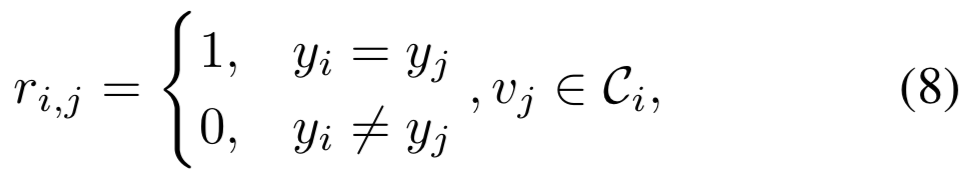
我们旨在预测反映了两个顶点是否属于同一个类的连通值。与GCN-V的等式(5)相似,我们也使用vertex-wise的MSE损失来训练GCN-E:
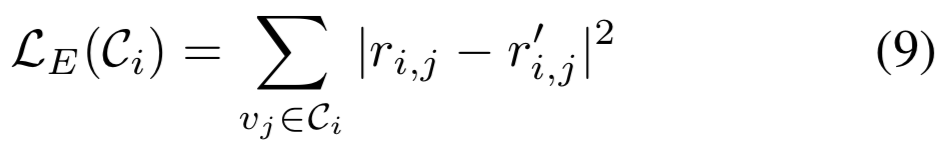
为了加速训练和推理过程,我们只将GCN-E应用于有着大估计置信度的一小部分顶点,因为它们可能比小置信度的顶点影响更多的后继顶点。我们用ρ表示使用的顶点比例。对于其他顶点,它们简单地连接到候选集中它们的M个最近邻,这表明它们连接到top-M个有着最高相似度和较高的置信度的邻居。M = 1得到基于树的划分策略,而M > 1产生有向无环图作为集群。经验结果表明,M = 1, ρ = 10%已经可以带来相当可观的性能增益(见第4.3.2节)。
Complexity Analysis. 连通性估计器的概念与[35]相似,在[35]中,它们评估子图上的每个顶点连接到中心顶点的可能性。虽然[35]的复杂度与N是线性相关的,但是在每个顶点的邻域上应用GCN会导致过多的计算需求。提出的GCN-E有两个使其更有效的关键设计:(1)我们只预测候选集中的连接,这一工作可能涉及到每个顶点较少的邻居,并且不需要手动选择每一跳的跳数和邻居数。(2)有了估计的顶点置信度,我们可以集中在一小部分高置信度的顶点上。有了这两种重要的设计,我们的速度比[35]快了一个数量级。
4. Experiments
4.1. Experimental Settings
Face clustering. MS-Celeb-1M[11]是一个由100K个身份组成的大型人脸识别数据集,每个身份大约有100张人脸图像。我们采用来自ArcFace[7]的广泛使用的注释,生成一个可靠的子集,其包含来自86K个类的580万幅图像。我们随机将清理后的数据集分成10个有着几乎相同数量的身份的数据集parts。每个part包含8.6K个身份和大约580K个图像。我们随机选择1个part作为已标注数据,其他9个部分作为未标注数据。
Fashion clustering. 我们也评估了我们的方法在人脸图像以外的数据集的有效性。我们在DeepFashion[21]的一个大子集上进行测试,即In-shop Clothes Retrieval,这是一个长尾数据集。特别地是,我们在原始split中混合了训练特征和测试特征,从3997个类别中随机抽取25752幅图像进行训练,并从3984个类别中抽取26960幅图像进行测试。注意,时尚聚类也被视为一个开放集问题,训练类别和测试类别之间没有重叠。
Face recognition. 我们在MegaFace[17]上评估人脸识别模型,这是人脸识别的最大基准。它包括一个来自FaceScrub[25]的带有3,530张图片的probe集和一个包含1百万张图片的gallery集。
Metrics. 我们评估了聚类和人脸识别的性能。人脸聚类通常用两个指标来评价[29,35,38],即pairwise F-score和BCubed F-score[2]。前者强调大的聚类,因为pairs的数量随聚类大小增长呈二次增长,而后者则根据聚类大小为聚类加权。这两个指标都是精度和召回率的调和平均值,分别称为FP和FB。利用MegaFace中的人脸识别基准对人脸识别进行了评价。我们在MegaFace中采用top-1的识别命中率,即对1M gallery图像中的top-1图像进行排序,计算top-1命中率。
Implementation Details. 为了构建KNN连通图,在MS1M设置K = 80,在Deep-Fashion设置K = 5。由于GCN-V在一个有数百万个顶点的图上进行操作,我们只使用1层的GCN来减少计算成本。对于GCN-E,它在一个不超过K个顶点的邻域上运行,因此我们使用4层的GCN来增加它的表达能力。对于这两个数据集,momentum SGD的起始学习率为0.1,权重衰减为1e−5。为了避免没有正确的连接邻居的情况,我们设置一个阈值τ来切断相似度较小的边。所有设置中,τ设置为0.8
4.2. Method Comparison
4.2.1 Face Clustering
我们将该方法与一系列聚类基线进行了比较。下面简要介绍这些方法。
(1) K-means[22],常用的聚类算法。对于N≥1.74M,我们使用mini-batch K-means,产生了类似的结果,但运行时间明显缩短。
(2) HAC[30],该方法以自底向上的方式,根据一定的条件分层 合并 紧密的集群。
(3) DBSCAN[9]根据设计的密度准则提取集群,并将稀疏背景作为噪声。
(4) MeanShift[6]精确指出包含一组收敛到同一局部最优点的集群。
(5) Spectral[24]根据相似矩阵的光谱将数据划分为连通分量。
(6) ARO[1]使用近似最近邻搜索和改进的距离度量进行聚类。
(7) CDP[39],一种基于图的聚类算法,它利用了更鲁棒的pairwise关系。
(8) L-GCN[35],一种最新的监督方法,采用GCNs来利用图上下文信息进行pairwise预测。
(9) LTC[38],另一个最近的监督方法,制定聚类为检测和分割pipeline。
(10) Ours(V),我们提出的方法是在整个图上应用GCN-V,通过将每个顶点与其候选集中最近邻相连接来获得集群。
(11) Ours(V + E),提出的方法是在GCN-V的基础上使用GCN-E来估计连通性,通过将每个顶点连接到候选集中连通度最高的邻居来获得集群。
Results 对于所有方法,我们都对相应的超参数进行调优,并报告最佳结果。表1和表2的结果表明:(1)给定集群的ground-truth数目,K-means获得较高的F-score。然而,集群数量对性能的影响很大,因此在集群数量未知的情况下很难使用。(2) HAC不要求集群的数量,但迭代合并过程计算量大。即使使用快速实现[23],当N为5.21M时,生成结果也需要将近900小时。(3)虽然DBSCAN非常高效,但它假设不同集群之间的密度是相似的,这可能是当扩展到大设置时性能严重下降的原因。(4) MeanShift对fashion聚类效果较好,但收敛时间较长。(5)Spectral clustering的性能也很好,但求解特征值分解需要大量的计算和内存,限制了其应用。(6) ARO的性能取决于邻居的数量。在时间预算合理的情况下,MS1M的性能不如其他方法。(7) CDP非常高效,在不同尺度的不同数据集上获得了较高的F-score。为了公平比较,我们将与CDP的单型号版本进行比较。(8) L-GCN持续超过CDP,但比CDP慢一个数量级。(9) LTC作为最近的一种有监督的聚类人脸方法,在大规模聚类中显示出其优势。然而,依赖于迭代proposal策略的性能提高伴随着较大的计算成本。(10)所提出的GCN-V算法在性能上始终优于之前的方法。虽然GCN-V的训练集只包含580K的图像,但它能很好地泛化到5.21M的未标记数据,证明了它在捕捉顶点重要特征方面的有效性。此外,由于GCN-V同时预测所有顶点的置信度,它比以前的监督方法快了一个数量级。(11)将GCN-E应用于20%的带有最高估计置信度的顶点。它带来了进一步的性能提高,特别是当应用到DeepFashion时。这个具有挑战性的数据集包含有噪声的邻域,因此需要更仔细地选择连接性。
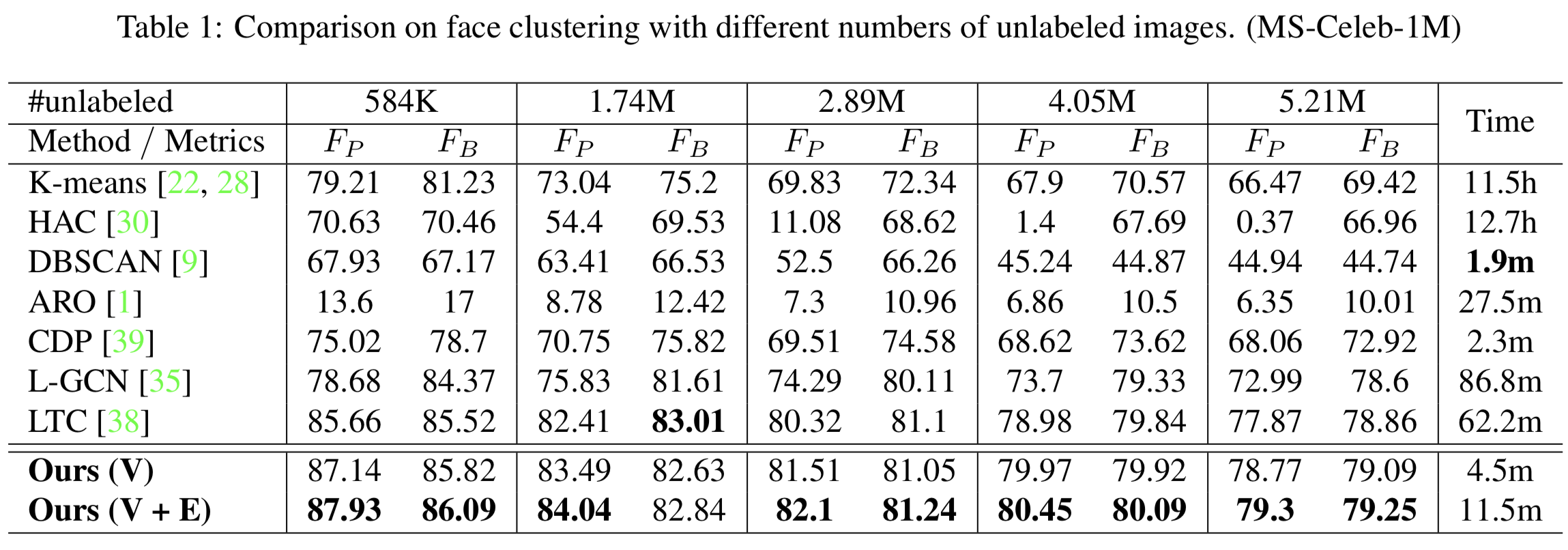

Runtime Analysis 我们使用ES-2640 v3 CPU和TitanXP测量不同方法的运行时间。对于MS-Celeb-1M,我们测量N = 584K时的运行时间。除了K-means和HAC之外,所有的比较方法都依赖于KNN图。针对算法本身的运行时间,我们使用1个GPU和16个CPU加速KNN[16]的搜索,将寻找80个最近邻的时间从34分钟缩短到101秒。对于所有的监督方法,我们分析了它们的推理时间。如表1所示,我们提出的GCN-V比L-GCN和LTC快一个数量级。GCN-E需要更多的时间来预测候选集中的连通性,但它仍然比L-GCN和LTC的效率高几倍。图3更好地说明了准确性和效率之间的权衡。对于LTC和mini-batch K-means,我们分别控制proposals的数量和batch大小,以产生不同的运行时间和精度。在实际应用中,我们可以利用LTC中的super vertex思想来进一步加速GCN-V,然后并行GCN-E来同时估计不同顶点的连通性。

4.2.2 Face Recognition
遵循[39,38]的pipeline,我们应用训练过的聚类模型将伪标签分配给未标记的数据,并利用它们来增强人脸识别模型。如第4.1节所介绍的,我们将数据集分成10个split,随机选择1个split得到ground-truth标签,记为![]() 。人脸识别实验包括4个步骤:(1)使用
。人脸识别实验包括4个步骤:(1)使用![]() 训练人脸识别模型
训练人脸识别模型![]() ;(2)在
;(2)在![]() 上使用
上使用![]() 提取人脸特征,使用从
提取人脸特征,使用从![]() 提取的特征和对应的标签训练聚类模型
提取的特征和对应的标签训练聚类模型![]() ;(3)使用
;(3)使用![]() 为未标记的图像分配伪标签;(4)使用
为未标记的图像分配伪标签;(4)使用![]() 和带有伪标签的未标记数据,以多任务方式训练最终的人脸识别模型。需要注意的是,我们使用
和带有伪标签的未标记数据,以多任务方式训练最终的人脸识别模型。需要注意的是,我们使用![]() 来训练初始的人脸识别模型和人脸聚类模型。
来训练初始的人脸识别模型和人脸聚类模型。
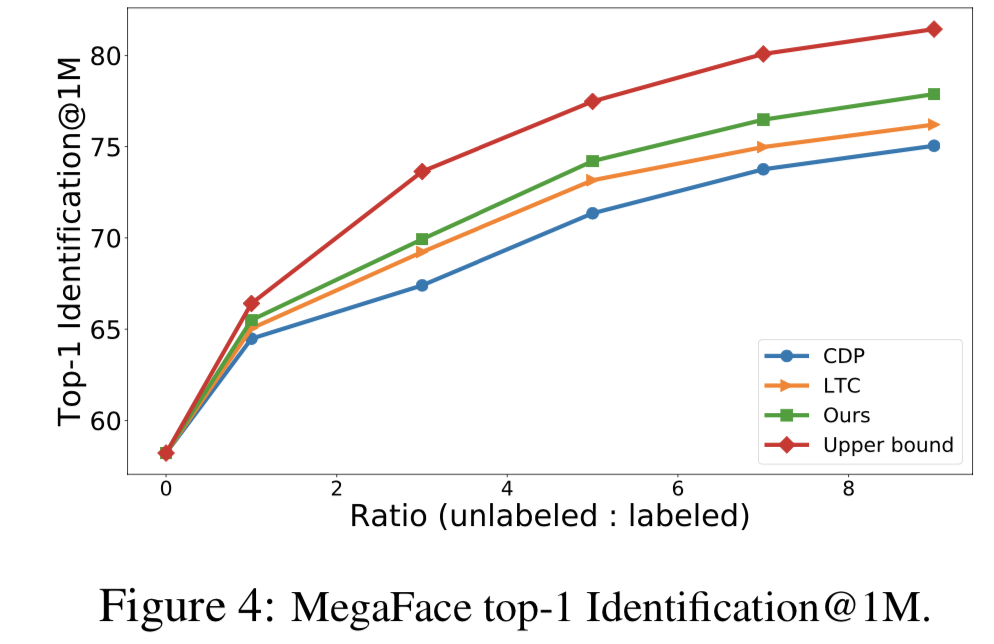
与以往假设连续获得未标记数据,并在9个分片上分别进行9次聚类的工作[39,38]不同,我们直接对5.21M未标记数据进行聚类,更具有实际意义和挑战性。通过假设所有未标记的数据都有ground-truth标签来训练上界(upper bound)。如图4所示,所有这三种方法都受益于未标记数据的增加。由于聚类性能的提高,我们的方法始终优于以往的方法,并将人脸识别模型在MegaFace上的性能从58.21提高到77.88。
4.3. Ablation Study
为了研究一些重要的设计选择,我们选择MS-Celeb-1M(584K)和DeepFashion进行消融研究。
4.3.1 Confidence Estimator
Design of vertex confidence. 我们探索不同的置信度设计。由于置信度与第2节中描述的“密度”概念有关,我们首先采用两种广泛使用的无监督密度作为置信度[9,3,26]。给定半径,第一个定义为顶点数,第二个定义为边权值之和,记为![]() 和
和![]() ,如表3所示。注意,对于这些无监督定义,置信度是直接计算的,不需要学习过程。另一方面,我们可以基于ground-truth标签定义各种监督置信度。
,如表3所示。注意,对于这些无监督定义,置信度是直接计算的,不需要学习过程。另一方面,我们可以基于ground-truth标签定义各种监督置信度。![]() 定义为与具有相同标签的所有顶点的平均相似度。
定义为与具有相同标签的所有顶点的平均相似度。![]() 定义为与中心的相似性,中心的相似性计算为具有相同标签的所有顶点的平均特征。
定义为与中心的相似性,中心的相似性计算为具有相同标签的所有顶点的平均特征。![]() 定义为等式(1)。
定义为等式(1)。![]() 表示使用top嵌入
表示使用top嵌入![]() 去重建图。为了比较不同的置信度设计,我们采用相同的连通性估计器,设ρ = 0和M = 1。在这个意义上,连通性估计器无需学习直接选择候选集中的最近邻。
去重建图。为了比较不同的置信度设计,我们采用相同的连通性估计器,设ρ = 0和M = 1。在这个意义上,连通性估计器无需学习直接选择候选集中的最近邻。
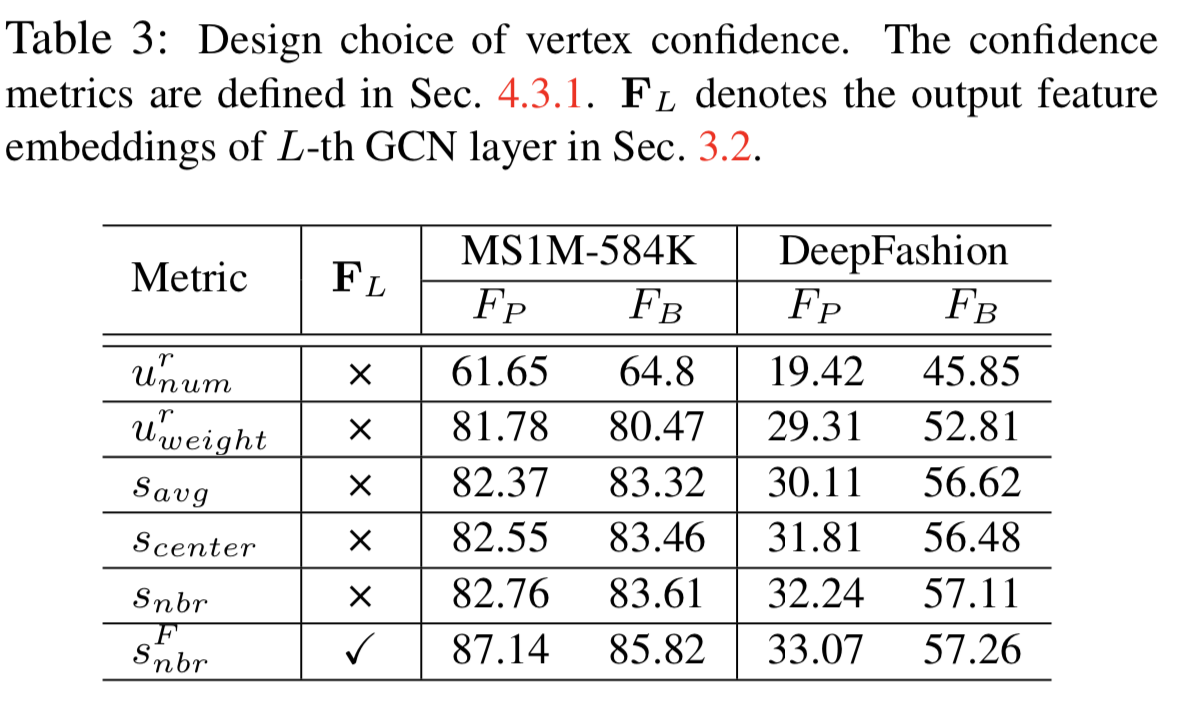
如表3所示,两种无监督密度定义的性能相对较低。高数据密度意味着集群的高概率,这种假设不一定适用于所有情况。此外,计算密度选择的半径对性能很敏感。表3显示,在不需要手动设置半径的情况下,监督置信度的性能优于非监督置信度。在这三种定义中,![]() 的性能优于
的性能优于![]() 和
和![]() 。由于
。由于![]() 是在邻域上定义的,所以GCN的学习可能比
是在邻域上定义的,所以GCN的学习可能比![]() 和
和![]() 更容易,而
更容易,而![]() 和
和![]() 是针对同一个聚类中的所有样本定义的。在实际应用中,类似于显著性检测[10,13]中的显著性map融合,我们可以对不同置信度的输出进行集成,以获得更好的性能。
是针对同一个聚类中的所有样本定义的。在实际应用中,类似于显著性检测[10,13]中的显著性map融合,我们可以对不同置信度的输出进行集成,以获得更好的性能。
Transformed embeddings. 对![]() 和
和![]() 的比较表明,利用转换后的特征重建连通图可以使两种数据集的性能都得到提高。这种思想与Dynamic图[34]的概念相同,在每个图卷积层之后重建KNN图。然而,在一个有数百万个顶点的大型图上,每一层构造KNN图将导致令人生畏的计算预算。实验结果表明,只有采用top嵌入来重建图像,才能得到较好的结果。
的比较表明,利用转换后的特征重建连通图可以使两种数据集的性能都得到提高。这种思想与Dynamic图[34]的概念相同,在每个图卷积层之后重建KNN图。然而,在一个有数百万个顶点的大型图上,每一层构造KNN图将导致令人生畏的计算预算。实验结果表明,只有采用top嵌入来重建图像,才能得到较好的结果。
4.3.2 Connectivity Estimator
The Influence of ρ. 我们将ρ从0变化到1,步长为0.1。如图5所示,只关注10%的高置信度顶点可以带来相当大的性能提升,同时只增加很少的计算成本。随着ρ的增加,更多的顶点受益于GCN-E的预测,从而FP增加。当将GCN-E应用到所有的顶点时,会有轻微的下降,因为置信度不高的顶点之间的连接通常非常复杂,可能很难找到通用的学习模式。

The Influence of M. 下表中,M =−1表示应用GCN-E时不使用候选集。它包括置信度低的邻居,从而增加了学习的难度,导致性能下降。
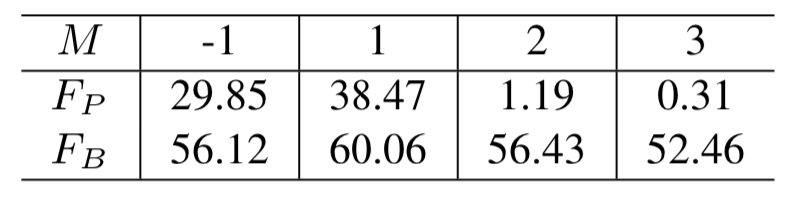
当M = 1时,每个顶点都连接到候选集中与其连接度最高的邻居。当M > 1时,不确定的顶点可能会连接到两个不同的集群。虽然它增加了已获得的集群的召回,但它可能严重损害精度。
5. Conclusion
本文提出了一种新的监督人脸聚类框架,消除了启发式步骤和大量子图的需求。该方法显著提高了大规模人脸聚类的精度和效率。实验结果表明,该方法在比训练集大10倍的测试集上有很好的泛化能力。在fashion数据集上的实验证明了它在人脸数据集之外的应用潜力。在未来,需要一个端到端的可学习聚类框架来充分释放监督聚类的力量。