SQL查询流程:
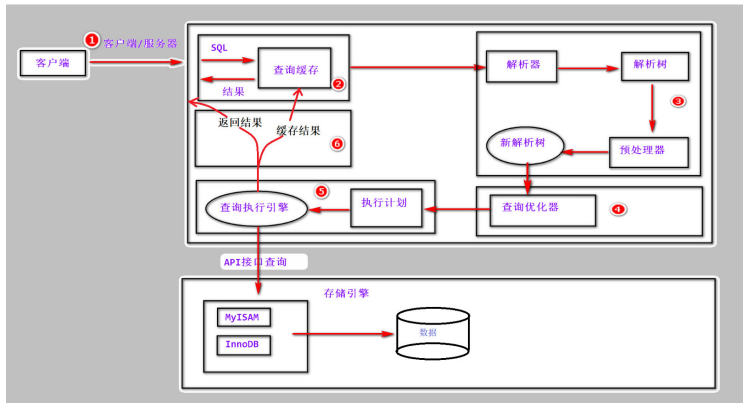
- 1. 通过客户端/服务器通信协议与 MySQL 建立连接
- 2. 查询缓存,这是 MySQL 的一个可优化查询的地方,如果开启了 Query Cache 且在查询缓存过程中查 询到完全相同的 SQL 语句,则将查询结果直接返回给客户端;如果没有开启Query Cache 或者没有查询到 完全相同的 SQL 语句则会由解析器进行语法语义解析,并生成解析树。
- 3. 预处理器生成新的解析树。
- 4. 查询优化器生成执行计划。
- 5. 查询执行引擎执行 SQL 语句,此时查询执行引擎会根据 SQL 语句中表的存储引擎类型,以及对应的 API 接口与底层存储引擎缓存或者物理文件的交互情况,得到查询结果,由MySQL Server 过滤后将查询结 果缓存并返回给客户端。若开启了 Query Cache,这时也会将SQL 语句和结果完整地保存到 Query Cache 中,以后若有相同的 SQL 语句执行则直接返回结果。
MySQL物理文件:
日志文件:
- error log 错误日志 排错 /var/log/mysqld.log【默认开启】
- bin log 二进制日志 备份 增量备份 DDL DML DCL
- Relay log 中继日志 复制 接收 replication master
- slow log 慢查询日志 调优 查询时间超过指定值
-- 查看错误日志文件路径 show variables like 'log_error'; +---------------+---------------------+ | Variable_name | Value | +---------------+---------------------+ | log_error | /var/log/mysqld.log | +---------------+---------------------+
-- 慢查询日志文件路径 show variables like 'slow_query_log_file'; +---------------------+-----------------------------------+ | Variable_name | Value | +---------------------+-----------------------------------+ | slow_query_log_file | /var/lib/mysql/localhost-slow.log | +---------------------+-----------------------------------+ -- bin log 日志文件 需要在 my.cnf 中配置 log-bin=/var/log/mysql-bin/bin.log server-id=2 -- 查看 relay log 相关参数 show variables like '%relay%'
配置文件&数据文件:
配置文件 my.cnf:
在 my.cnf 文件中可以进行一些参数设置, 对数据库进行调优。
[client] #客户端设置,即客户端默认的连接参数 port = 3307 #默认连接端口 socket = /data/mysqldata/3307/mysql.sock #用于本地连接的socket套接字 default-character-set = utf8mb4 #编码 [mysqld] #服务端基本设置 port = 3307 MySQL监听端口 socket = /data/mysqldata/3307/mysql.sock #为MySQL客户端程序和服务器之间的本地通讯指定一 个套接字文件 pid-file = /data/mysqldata/3307/mysql.pid #pid文件所在目录 basedir = /usr/local/mysql-5.7.11 #使用该目录作为根目录(安装目录) datadir = /data/mysqldata/3307/data #数据文件存放的目录 tmpdir = /data/mysqldata/3307/tmp #MySQL存放临时文件的目录 character_set_server = utf8mb4 #服务端默认编码(数据库级别)
-- 查看数据文件的位置 show variables like '%dir%'; +-----------------------------------------+----------------------------+ | Variable_name | Value | +-----------------------------------------+----------------------------+ | datadir | /var/lib/mysql/ | +-----------------------------------------+----------------------------
1、.frm文件 不论是什么存储引擎,每一个表都会有一个以表名命名的.frm文件,与表相关的元数据(meta)信息都存放在 此文件中,包括表结构的定义信息等。 2、.MYD文件 myisam存储引擎专用,存放myisam表的数据(data)。每一个myisam表都会有一个.MYD文件与之呼应,同 样存放在所属数据库的目录下 3、.MYI文件 也是myisam存储引擎专用,存放myisam表的索引相关信息。每一个myisam表对应一个.MYI文件,其存放的 位置和.frm及.MYD一样 4、.ibd文件 存放innoDB的数据文件(包括索引)。 5. db.opt文件 此文件在每一个自建的库里都会有,记录这个库的默认使用的字符集和校验规。
MySQL查询和慢查询日志分析:
等待时间长:
- 1.锁表导致查询一直处于等待状态,后续我们从MySQL锁的机制去分析SQL执行的原理
执行时间长:
- 1.查询语句写的烂
- 2.索引失效
- 3.关联查询太多join
- 4.服务器调优及各个参数的设置
需要遵守的优化原则:
- 第一条: 只返回需要的结果
一定要为查询语句指定 WHERE 条件,过滤掉不需要的数据行
避免使用 select * from , 因为它表示查询表中的所有字段
- 第二条: 确保查询使用了正确的索引
经常出现在 WHERE 条件中的字段建立索引,可以避免全表扫描;
将 ORDER BY 排序的字段加入到索引中,可以避免额外的排序操作;
多表连接查询的关联字段建立索引,可以提高连接查询的性能;
将 GROUP BY 分组操作字段加入到索引中,可以利用索引完成分组。
- 第三条: 避免让索引失效
在 WHERE 子句中对索引字段进行表达式运算或者使用函数都会导致索引失效
使用 LIKE 匹配时,如果通配符出现在左侧无法使用索引
如果 WHERE 条件中的字段上创建了索引,尽量设置为 NOT NULL
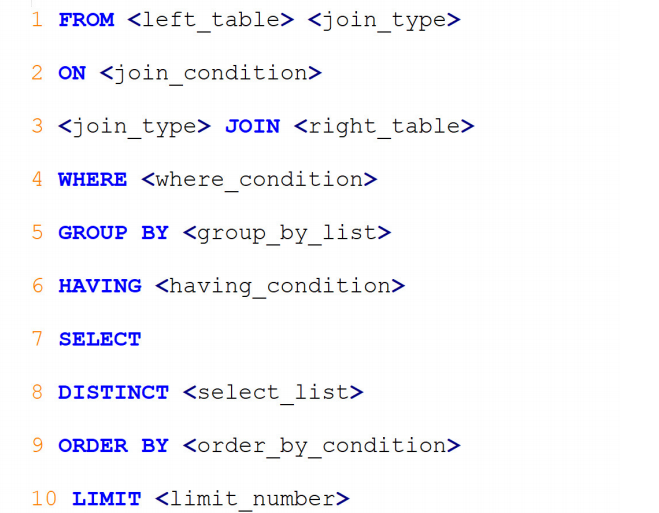
SQL的执行顺序:
我们写的sql:

sql的执行顺序:
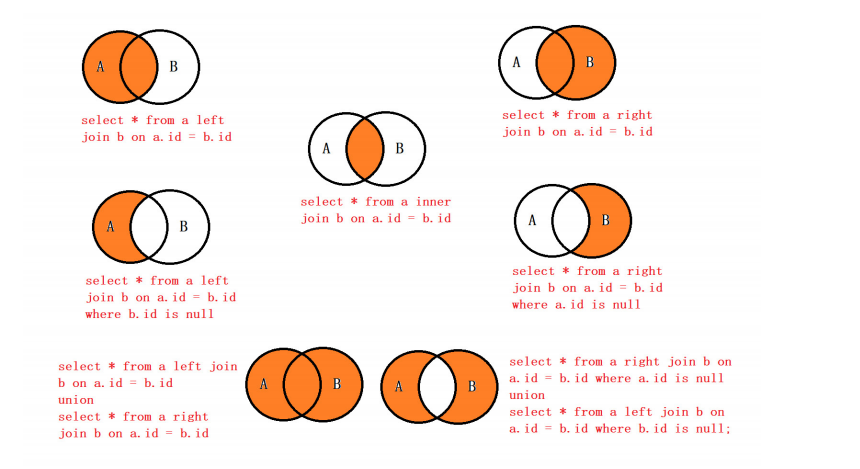
MYSQL的7种join:
慢查询日志分析:
MySQL的慢查询,全名是慢查询日志,是MySQL提供的一种日志记录,用来记录在MySQL中响应时间 超过阈值的语句。
默认情况下,MySQL数据库并不启动慢查询日志,需要手动来设置这个参数。
如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影 响。
慢查询日志支持将日志记录写入文件和数据库表。
SHOW VARIABLES LIKE "%query%" ; slow_query_log:是否开启慢查询日志, 1 表示开启, 0 表示关闭。 slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。 long_query_time: 慢查询阈值,当查询时间多于设定的阈值时,记录日志。
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的 mysql> SHOW VARIABLES LIKE '%slow_query_log%'; +---------------------+-----------------------------------+ | Variable_name | Value | +---------------------+-----------------------------------+ | slow_query_log | OFF | | slow_query_log_file | /var/lib/mysql/localhost-slow.log | +---------------------+-----------------------------------+
可以通过设置slow_query_log的值来开启 mysql> set global slow_query_log=1; mysql> SHOW VARIABLES LIKE '%slow_query_log%'; +---------------------+-----------------------------------+ | Variable_name | Value | +---------------------+-----------------------------------+ | slow_query_log | ON | | slow_query_log_file | /var/lib/mysql/localhost-slow.log | +---------------------+-----------------------------------+
使用 set global slow_query_log=1 开启了慢查询日志只对当前数据库生效,MySQL重启后则 会失效。
如果要永久生效,就必须修改配置文件my.cnf(其它系统变量也是如此)
-- 编辑配置 vim /etc/my.cnf -- 添加如下内容 slow_query_log =1 slow_query_log_file=/var/lib/mysql/lagou-slow.log -- 重启MySQL service mysqld restart mysql> SHOW VARIABLES LIKE '%slow_query_log%'; +---------------------+-------------------------------+ | Variable_name | Value | +---------------------+-------------------------------+ | slow_query_log | ON | | slow_query_log_file | /var/lib/mysql/lagou-slow.log | +---------------------+-------------------------------+
那么开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢?
这个是由参数 long_query_time 控制,默认情况下long_query_time的值为10秒
mysql> show variables like 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+
注意:使用命令 set global long_query_time=1 修改后,需要重新连接或新开一个会话才能 看到修改值。
mysql> set global long_query_time=1;
mysql> show variables like 'long_query_time'; +-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | long_query_time | 1.000000 | +-----------------+----------+
log_output 参数是指定日志的存储方式。 log_output='FILE' 表示将日志存入文件,默认值 是'FILE'。
log_output='TABLE' 表示将日志存入数据库,这样日志信息就会被写入到 mysql.slow_log 表中。
mysql> SHOW VARIABLES LIKE '%log_output%'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_output | FILE | +---------------+-------+
系统变量 log-queries-not-using-indexes :未使用索引的查询也被记录到慢查询日志中(可选 项)。如果调优的话,建议开启这个选项。
mysql> show variables like 'log_queries_not_using_indexes'; +-------------------------------+-------+ | Variable_name | Value | +-------------------------------+-------+ | log_queries_not_using_indexes | OFF | mysql> set global log_queries_not_using_indexes=1; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'log_queries_not_using_indexes'; +-------------------------------+-------+ | Variable_name | Value | +-------------------------------+-------+ | log_queries_not_using_indexes | ON | +-------------------------------+-------+ 1 row in set (0.00 sec)
MySQL存储引擎:
InnoDB(推荐):
优点:
- Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别
- 支持多版本并发控制的行级锁,由于锁粒度小,写操作和更新操作并发高、速度快。
- 支持自增长列。
- 支持外键。
- 适合于大容量数据库系统,支持自动灾难恢复。
缺点:
- 它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表
应用场景 :
- 当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表, 所以在并发较高时,使用Innodb引擎会提升效率
- 更新密集的表, InnoDB存储引擎特别适合处理多重并发的更新请求
MyISAM:
优点:
- MyISAM存储引擎在查询大量数据时非常迅速,这是它最突出的优点
- 另外进行大批量插入操作时执行速度也比较快。
缺点:
- MyISAM表没有提供对数据库事务的支持。
- 不支持行级锁和外键。
- 不适合用于经常UPDATE(更新)的表,效率低。
应用场景:
- 以读为主的业务,例如:图片信息数据库,博客数据库,商品库等业务。
- 对数据一致性要求不是非常高的业务(不支持事务)
- 硬件资源比较差的机器可以用 MyiSAM (占用资源少)
MySQL索引优化:
普通索引:
CREATE INDEX <索引的名字> ON tablename (字段名); ALTER TABLE tablename ADD INDEX [索引的名字] (字段名); CREATE TABLE tablename ( [...], INDEX [索引的名字] (字段名) );
唯一索引:
CREATE UNIQUE INDEX <索引的名字> ON tablename (字段名); ALTER TABLE tablename ADD UNIQUE INDEX [索引的名字] (字段名); CREATE TABLE tablename ( [...], UNIQUE [索引的名字] (字段名) ;
主键索引:
CREATE TABLE tablename ( [...], PRIMARY KEY (字段名) ); ALTER TABLE tablename ADD PRIMARY KEY (字段名);
复合索引:
用户可以在多个列上建立索引,这种索引叫做组复合索引(组合索引)。复合索引可以代替 多个单一索引,相比多个单一索引复合索引所需的开销更小。
CREATE INDEX <索引的名字> ON tablename (字段名1,字段名2...); ALTER TABLE tablename ADD INDEX [索引的名字] (字段名1,字段名2...); CREATE TABLE tablename ( [...], INDEX [索引的名字] (字段名1,字段名2...) );
复合索引注意事项:
- 1. 何时使用复合索引,要根据where条件建索引,注意不要过多使用索引,过多使用会对 更新操作效率有很大影响。
- 2. 如果表已经建立了(col1,col2),就没有必要再单独建立(col1);如果现在有(col1)索 引,如果查询需要col1和col2条件,可以建立(col1,col2)复合索引,对于查询有一定提 高。
全文索引:
查询操作在数据量比较少时,可以使用like模糊查询,但是对于大量的文本数据检索,效率很 低。如果使用全文索引,查询速度会比like快很多倍。
CREATE FULLTEXT INDEX <索引的名字> ON tablename (字段名); ALTER TABLE tablename ADD FULLTEXT [索引的名字] (字段名); CREATE TABLE tablename ( [...], FULLTEXT KEY [索引的名字] (字段名) ;
和常用的like模糊查询不同,全文索引有自己的语法格式,使用 match 和 against 关键字,比如:
SELECT * FROM users3 WHERE MATCH(NAME) AGAINST('aabb'); -- * 表示通配符,只能在词的后面 SELECT * FROM users3 WHERE MATCH(NAME) AGAINST('aa*' IN BOOLEAN MODE);
全文索引使用注意事项:
- 全文索引必须在字符串、文本字段上建立。
- 全文索引字段值必须在最小字符和最大字符之间的才会有效。(innodb:3-84; myisam:4-84)
创建索引的原则:
- 在经常需要搜索的列上创建索引,可以加快搜索的速度;
- 在作为主键的列上创建索引,强制该列的唯一性和组织表中数据的排列结构;
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续 的;
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快 排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
- group by字段
索引原理:
hash 结构:
Hash底层实现是由Hash表来实现的,是根据键值 <key,value> 存储数据的结构。非常适合根据 key查找value值,也就是单个key查询,或者说等值查询。
B+Tree结构
非叶子节点不存储data数据,只存储索引值,这样便于存储更多的索引值 叶子节点包含了所有的索引值和data数据 叶子节点用指针连接,提高区间的访问性能

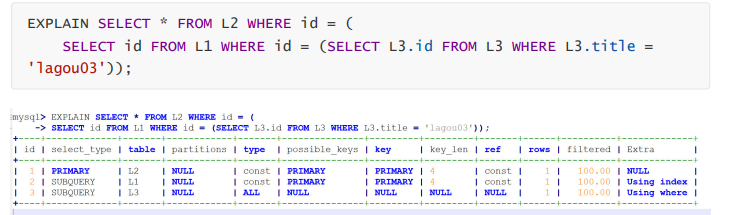
EXPLAIN性能分析:

id:
id相同,执行顺序由上至下
id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
select_type:
simple : 简单的select查询,查询中不包含子查询或者UNION
primary : 查询中若包含任何复杂的子部分,最外层查询被标记
subquery : 在select或where列表中包含了子查询
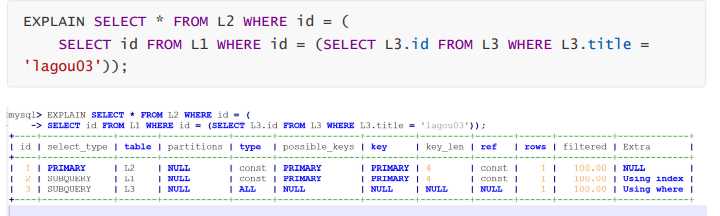
union : 如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句 的子查询中,外层select被标记为derived

type介绍:
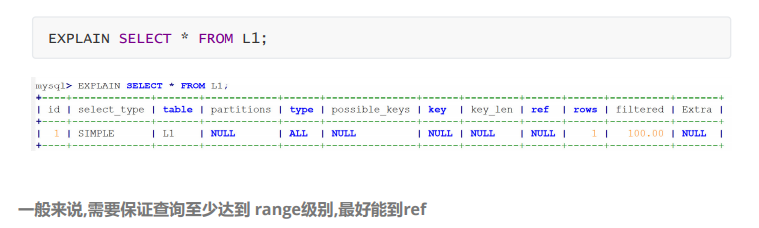
type显示的是连接类型,是较为重要的一个指标。
下面给出各种连接类型,按照从最佳类型到最坏类型 进行排序:
system > const > eq_ref > ref > range > index > ALL
system : 表仅有一行 (等于系统表)。这是const连接类型的一个特例,很少出现。
const : 表示通过索引 一次就找到了, const用于比较 primary key 或者 unique 索引. 因为只匹配 一行数据,所以如果将主键 放在 where条件中, MySQL就能将该查询转换为一个常量

eq_ref : 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配. 常见与主键或唯一索引扫描

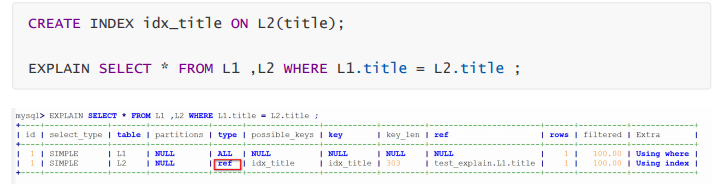
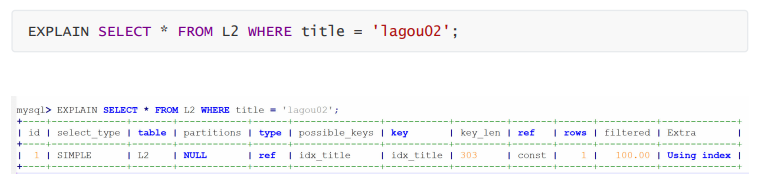
ref : 非唯一性索引扫描, 返回匹配某个单独值的所有行, 本质上也是一种索引访问, 它返回所有匹配 某个单独值的行, 这是比较常见连接类型.
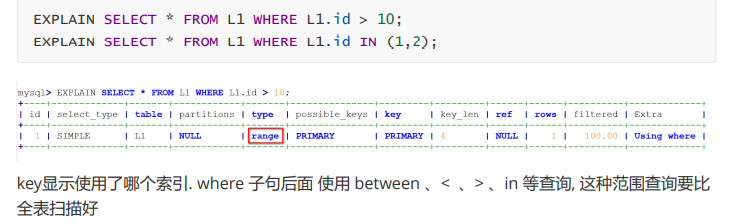
range : 只检索给定范围的行,使用一个索引来选择行。
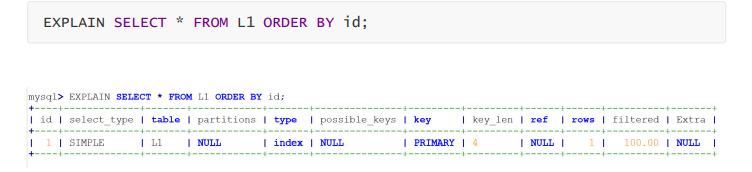
index : 出现index 是 SQL 使用了索引, 但是没有通过索引进行过滤,一般是使用了索引进行排序分 组
ALL : 对于每个来自于先前的表的行组合,进行完整的表扫描。
possible_keys:显示可能应用到这张表上的索引, 一个或者多个. 查询涉及到的字段上若存在索引, 则该索引将 被列出, 但不一定被查询实际使用
key :实际使用的索引
key_len介绍:
表示索引中使用的字节数, 可以通过该列计算查询中使用索引的长度.
CREATE TABLE T1( a INT PRIMARY KEY, b INT NOT NULL, c INT DEFAULT NULL, d CHAR(10) NOT NULL ); EXPLAIN SELECT * FROM T1 WHERE a > 1 AND b = 1;

ALTER TABLE T1 ADD INDEX idx_b(b);

ALTER TABLE T1 ADD INDEX idx_d(d);
