Redis缓存
京淘项目架构优化
说明:为了提高数据库"查询"能力.引入缓存服务器.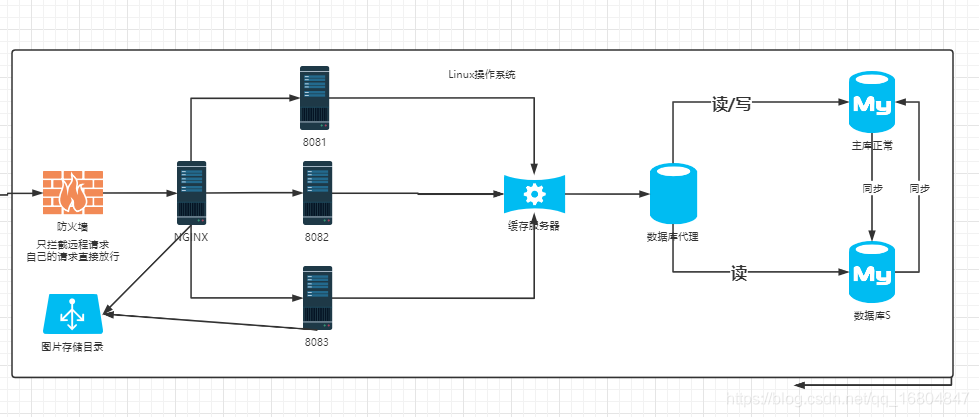
缓存机制的介绍
说明:使用缓存机制主要的目的就是为了降低用户访问物理设备的频次.从缓存服务器中直接获取数据,快速的响应用户,提高整体的查询速度.用户体验更好.
如何实现:
1.缓存机制应该采用什么样的数据结构 进行构建? K-V结构 K必须唯一
2.应该使用什么语言进行开发? C语言
3.缓存的运行环境是哪? 内存
4.内存断电即擦除, 如何保证数据的安全性?? 实现持久化(写入磁盘)操作
5.内存中的数据如何进行优化 (不能一直存? ) 内存优化的算法 LRU算法
Redis介绍
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets)
与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability).
速度快:
tomcat: 150-220/秒
nginx: 3-5万/秒
redis: 写 8.6万/秒 读 11.2万/秒 ~ 平均10万次/秒
Redis安装
上传Redis
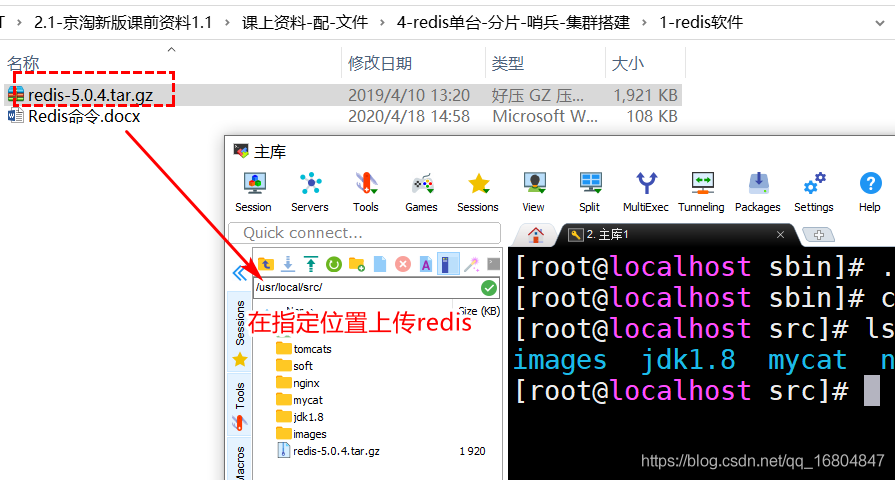
解压Redis

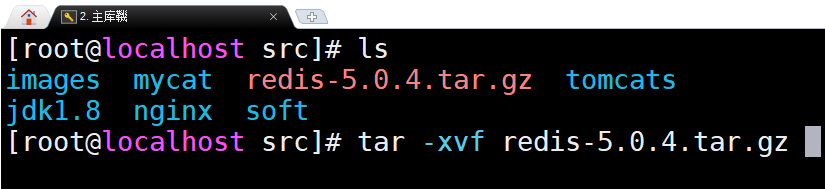
解压Redis
编译安装Redis
1.执行编译操作 make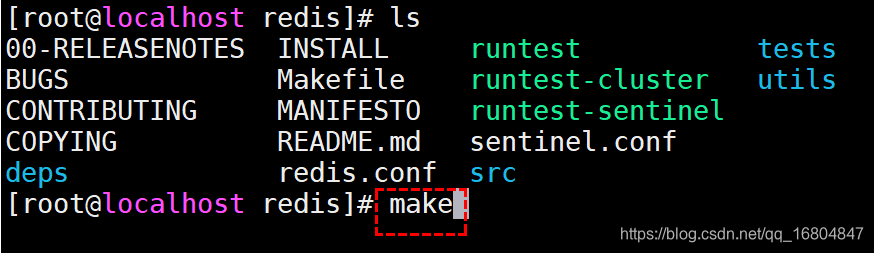
2.安装redis make install
修改redis配置文件
1).修改IP绑定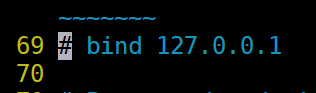
2).取消保护模式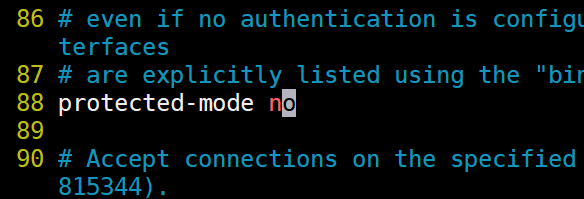
3).开启后台启动
Redis常规命令
要求:进入redis根目录中执行.
特点:redis每次启动时都会读取配置文件. 如果需要准备多台redis则需要准备多个配置文件
1.启动命令 redis-server redis.conf
没有开启后台运行的效果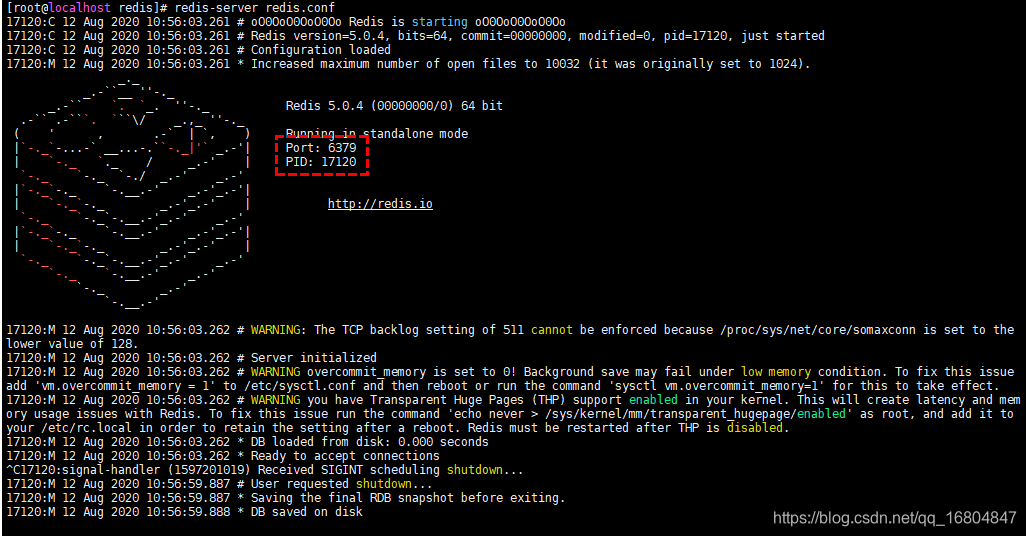
开启后台运行的效果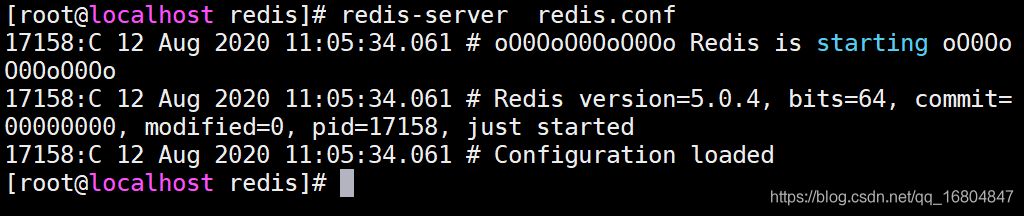
2.检索redis服务
3. 进入redis客户端中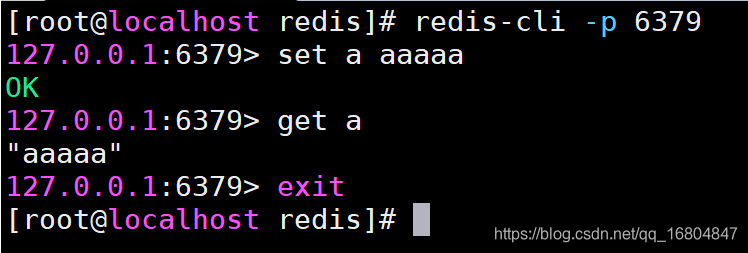
4.关闭redis
方式1: redis-cli -p 6379 shutdown
方式2: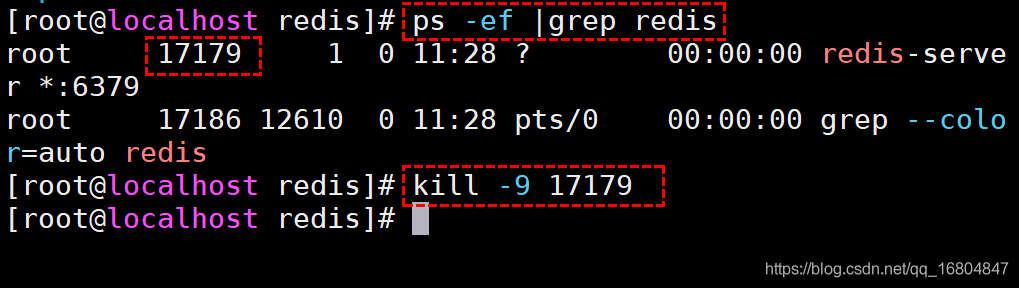
redis常见面试题
缓存穿透
特点: 用户高并发环境下,访问数据库中根本不存在的数据.
影响:由于用户高并发访问,则数据库可能存在宕机的风险.
缓存击穿
说明: 由于用户高并发的访问. 访问的数据刚开始有缓存,但是由于特殊原有 导致缓存失效.(数据’‘单个’’)
缓存雪崩
说明: 由于高并发的环境下.大量的用户访问服务器. redis中有大量的数据在同一时间超时(删除).
解决方案:不要同一时间删除数据.
Redis持久化问题
问题说明
说明:Redis中的数据都保存在内存中.如果服务关闭或者宕机则内存资源直接丢失.导致缓存失效.
持久化原理说明
说明:Redis中有自己的持久化策略.Redis启动时根据配置文件中指定的持久化方式进行持久化操作. Redis中默认的持久化的方式为RDB模式.
RDB模式
特点说明:
1.RDB模式采用定期持久化的方式. 风险:可能丢失数据.
2.RDB模式记录的是当前Redis的内存记录快照. 只记录当前状态. 持久化效率最高的
3.RDB模式是默认的持久化方式.
持久化命令:
命令1: save 同步操作. 要求记录马上持久化. 可能对现有的操作造成阻塞
名来2: bgsave 异步操作. 开启单独的线程实现持久化任务.
持久化周期:
save 900 1 在900秒内,如果执行一次更新操作,则持久化一次.
save 300 10 在300秒内,如果执行10次更新操作,则持久化一次.
save 60 10000 在60秒内,如果执行10000次更新操作,则持久化一次.
save 1 1 ???不可以 容易阻塞 性能太低.不建议使用.
用户操作越频繁,则持久化周期越短.
AOF模式
特点:
1.AOF模式默认是关闭状态 如果需要则手动开启.
2.AOF能够记录程序的执行过程 可以实现数据的实时持久化. AOF文件占用的空间较大.回复数据的速度较慢.
3.AOF模式开启之后.RDB模式将不生效.
AOF配置:
持久化周期配置:
appendfsync always 实时持久化.
appendfsync everysec 每秒持久化一次 略低于rdb模式
appendfsync no 自己不主动持久化(被动:由操作系统解决)
redis中如何选择持久化方式
思路: 如果允许数据少量的丢失,则首选RDB.(快),如果不允许数据丢失则使用AOF模式.
情景题
小张在双11前夜误操作将Redis服务器执行了flushAll命令. 问项目经理应该如何解决??
A: 痛批一顿 ,让其提交离职申请.
B: 批评教育, 让其深刻反省,并且请主管 捏脚.
C:项目经理快速解决.并且通知全部门注意.
解决方案:
修改aof文件中的命令.删除flushAll之后重启redis即可.
Redis内存优化策略
修改Redis内存

修改内存大小:
场景说明
Redis运行的空间是内存.内存的资源比较紧缺.所以应该维护redis内存数据,将改让redis保留热点数据.
LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度: 自上一次使用的时间T
最为理想的内存置换算法.
LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
least frequently used (LFU) page-replacement algorithm
即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 引用次数
RANDOM算法
随机算法
内存策略优化
- volatile-lru 在设定了超时时间的数据, 采用lru算法进行删除.
2.allkeys-lru 所有数据采用lru算法
3.volatile-lfu 在设定了超时时间的数据, 采用LFU算法进行删除.
4.allkeys-lfu 所有数据采用LFU算法
5.volatile-random 设定超时时间数据采用随机算法
6.allkeys-random 所有数据采用随机算法
7.volatile-ttl 设定了超时时间的数据 根据ttl规则删除. 将剩余时间少的提前删除
8.noeviction 内存满了 不做任何操作.报错返回.
Redis分片机制
分片机制说明
前提说明: redis可以通过修改内存的大小 实现数据的保存.但是内存的资源不易设置的过大,因为很多的时间都浪费在内存的寻址中.
需求: 如果有海量的数据,需要redis存储 问:应该如何处理?
解决方案: 可以采用Redis分片机制 实现内存数据的扩容.
知识点: 采用redis分片 只要的目的就是为了实现内存扩容.从而解决海量数据存储的问题
Redis分片入门案例
-
public class TestShards { //改类表示测试redis分片机制 /** * 说明:在Linux中有3台redis.需要通过程序进行动态链接. * 实现数据的存储. * 思考: 数据保存到了哪台redis中??? */ @Test public void test01(){ List<JedisShardInfo> shards = new ArrayList<>(); shards.add(new JedisShardInfo("192.168.126.129", 6379)); shards.add(new JedisShardInfo("192.168.126.129", 6380)); shards.add(new JedisShardInfo("192.168.126.129", 6381)); //分片的API ShardedJedis shardedJedis = new ShardedJedis(shards); shardedJedis.set("王者荣耀", "你好我是小菜鸡,坑死你"); System.out.println(shardedJedis.get("王者荣耀")); } }
一致性hash算法
一致性hash说明
一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,目的是解决分布式缓存的问题。 [1] 在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题 [2] 。
一致性hash原理
常识:
1) 一般的hash由8位16进制数组成的. 共有2^32种可能性!!!
2) hash算法对相同的数据进行hash运算时 结果必然相同.00000000-FFFFFFFF 0-F=(24)8 = 2^32
进制:
1).二进制 取值 : 0-1 规则满2进1
2).八进制 取值 : 0-7 规则满8进1 2^3=8 每三位二进制数就是一个8进制数
3).十六进制 取值 : 0-9 A-F 规则满16进一 2^4=16 每四位二进制数就是一个16进制数

一致性hash 特性
平衡性
①平衡性是指hash的结果应该平均分配到各个节点,这样从算法上解决了负载均衡问题
说明:引入虚拟节点 实现数据的平衡 但是平衡是相对的.不是绝对的.
单调性
②单调性是指在新增或者删减节点时,不影响系统正常运行 [4] 。

分散性
③分散性是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据 [4] 。
鸡蛋不要放到一个篮子里.Spring整合redis分片机制
准备Redis.pro文件
# 配置单台redis #redis.host=192.168.126.129 #redis.port=6379 # 配置多台redis redis.nodes=192.168.126.129:6379,192.168.126.129:6380,192.168.126.129:6381
编辑配置类
-
@Configuration //标识我是配置类 @PropertySource("classpath:/properties/redis.properties") public class RedisConfig { @Value("${redis.nodes}") private String nodes; //node,node,node /** * spring整合redis分片机制 */ @Bean public ShardedJedis shardedJedis(){ //1.获取每个节点的信息 String[] strNodes = nodes.split(","); List<JedisShardInfo> shards = new ArrayList<>(); //2.遍历所有node.为list集合赋值 for(String node :strNodes){ //node=ip:port String host = node.split(":")[0]; int port = Integer.parseInt(node.split(":")[1]); JedisShardInfo info = new JedisShardInfo(host,port); shards.add(info); } ShardedJedis shardedJedis = new ShardedJedis(shards); return shardedJedis; } /* @Value("${redis.host}") private String host; @Value("${redis.port}") private Integer port; //SpringBoot管理 Spring框架的优化的API @Bean public Jedis jedis(){ return new Jedis(host,port); }*/ }
分片机制AOP使用

Redis哨兵机制
redis分片机制存在的问题
说明:Redis分片机制可以实现内存数据的扩容.但是如果Redis服务器发生了宕机的现象,则会影响整个分片使用.
问题:Redis分片机制没有实现高可用. 当主机宕机之后.由从机自动的实现故障迁移.用户访问不受任何影响.
Redis主从搭建
前提条件: 如果要实现redis高可用机制,则必须首先实现主从搭建.
主从关系设定: 6379当做主机-M 6380/6381 从机-S主从配置问题说明
说明:当redis服务器已经配置了主从结构之后.如果将服务器宕机.之后再次重启.则发现从服务器又会变为主机!!!
问题说明: 执行了主从挂载命令 该命令一直保存在内存中.当redis服务器重启之后,该命令失效.如果想要一直保持主从的关系.则必须将主从的结构写入Redis.conf的配置文件中.哨兵机制原理说明

1.首先启动Redis哨兵.由哨兵监控整个Redis主从状态. 主要监控M主机. 同时获取其从机的信息.
2.哨兵利用心跳检测机制(PING-PONG)的方式监控主机是否宕机. 如果连续3次主机没有响应.则哨兵判断主机宕机.
之后开始进行选举.
3.根据从主机中获取的从机信息.之后利用 选举机制算法.挑选新的主机.
4.之后将剩余的redis修改为当前主机的的从.并且修改配置文件.Spring整合Redis哨兵
入门案例
package com.jt.test; import org.junit.jupiter.api.Test; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisSentinelPool; import java.util.HashSet; import java.util.Set; public class TestSentinel { //主要完成哨兵测试 /** * 参数说明: * masterName: 主机名称 * sentinels: 哨兵节点信息. */ @Test public void test01(){ Set<String> sentinels = new HashSet<>(); String node = "192.168.126.129:26379"; sentinels.add(node); JedisSentinelPool sentinelPool = new JedisSentinelPool("mymaster", sentinels); Jedis jedis = sentinelPool.getResource(); //获取资源 jedis.set("sentinel", "redis哨兵机制配置成功!!!!"); System.out.println(jedis.get("sentinel")); } }
搭建Redis集群
Redis分片/Redis哨兵总结
说明:
1).分片可以实现Redis内存数据的扩容.可以存储海量的内存数据. Redis分片机制没有实现高可用.如果分片中一个节点宕机,则直接影响整个服务的运行.
2).哨兵可以实现Redis节点的高可用.但是Redis中的数据不能实现内存的扩容.
哨兵服务本身没有实现高可用.如果哨兵发生了异常则直接影响用户使用.SpringBoot整合Redis集群
编辑redis.properties配置文件
redis.nodes=192.168.126.129:7000,192.168.126.129:7001,192.168.126.129:7002,192.168.126.129:7003,192.168.126.129:7004,192.168.126.129:7005
编辑配置类
@Configuration //我是一个配置类 一般都会与@Bean联用 @PropertySource("classpath:/properties/redis.properties") public class RedisConfig { /** * spring整合Redis集群 */ @Value("${redis.nodes}") private String redisNodes; @Bean public JedisCluster jedisCluster() { Set<HostAndPort> nodeSet = new HashSet<HostAndPort>(); String[] clusters = redisNodes.split(","); for (String cluster : clusters) { //host:port String host = cluster.split(":")[0]; int port = Integer.parseInt(cluster.split(":")[1]); nodeSet.add(new HostAndPort(host, port)); } return new JedisCluster(nodeSet); } }
编辑AOP注入

京淘分布式架构-jt-web服务器

为什么页面以.html结尾
说明: .html结尾的请求更容易被搜索引擎收录.增强网站的曝光率.
倒排索引: 根据关键字检索文件的位置
搜索引擎工作原理: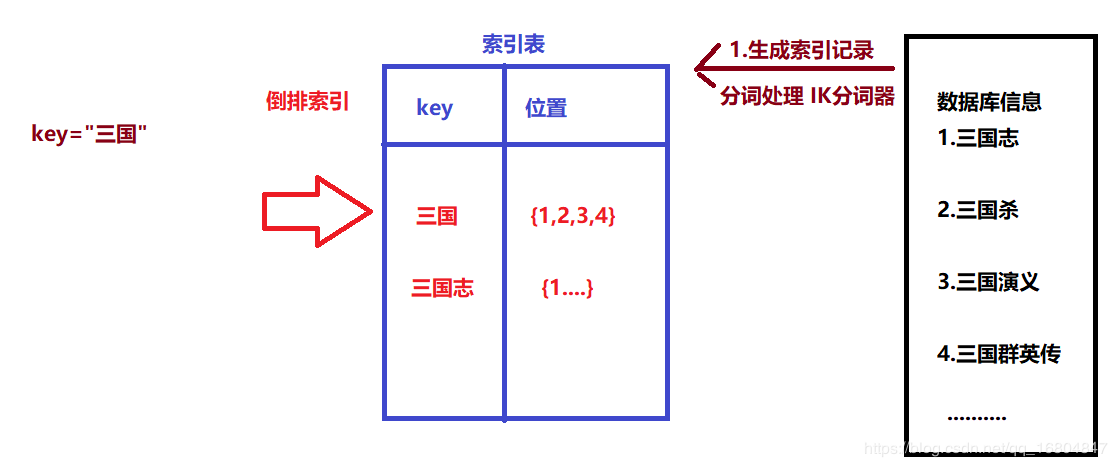
伪静态
伪静态是相对真实静态来讲的,通常我们为了增强搜索引擎的友好面,都将文章内容生成静态页面,但是有的朋友为了实时的显示一些信息。或者还想运用动态脚本解决一些问题。不能用静态的方式来展示网站内容。但是这就损失了对搜索引擎的友好面。怎么样在两者之间找个中间方法呢,这就产生了伪静态技术。伪静态技术是指展示出来的是以html一类的静态页面形式,但其实是用ASP一类的动态脚本来处理的。
总结: 以.html为结尾的展现动态页面的技术称之为伪静态.跨域实现
跨域访问测试
案例1:
页面网址:http://manage.jt.com:80/test.html
ajax请求: http://manage.jt.com:80/test.json
结论: 当请求协议://域名:port端口号都相同时 访问正常的.案例2:
页面网址: http://www.jt.com:80/test.html
ajax请求: http://manage.jt.com:80/test.json
结论: 当浏览器的地址与ajax地址不同时,请求不能正常执行.同源策略说明
说明:浏览器在发起AJAX请求时,必须遵守同源策略的规定.否则数据无法正常解析.
策略说明: 发起请求时,必须满足 协议://域名:端口都相同(和当前页面对比)时.满足同源策略要求.浏览器可以正确的发起请求,并且解析结果.,
但是如果上述的三项中有一项不同,则表示跨域访问.浏览器不予解析返回值结果.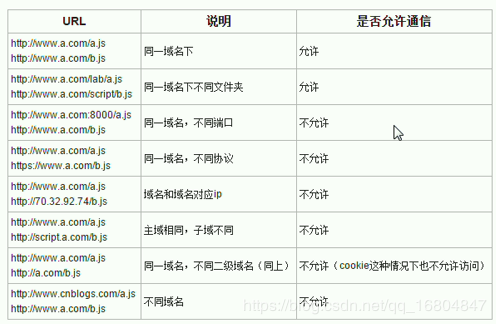
什么是跨域
定义: 当浏览器解析ajax时,ajax发起请求的地址如果与当前页面所在的地址违反同源策略时,则称之为跨域(请求)
JSONP(难)
JSONP(JSON with Padding)是JSON的一种“使用模式”,可用于解决主流浏览器的跨域数据访问的问题。由于同源策略,一般来说位于 server1.example.com 的网页无法与不是 server1.example.com的服务器沟通。
JSONP跨域实现原理
1).利用javascript中的src属性实现跨域
<script type="text/javascript" src="http://manage.jt.com/test.json"></script>
2).自定义回调函数 function callback(){}
function hello(data){ alert(data.name); }3).将返回值结果 进行特殊的格式封装 callback(JSON数据)
hello({"id":"1","name":"tomcat猫"})