
前面的章节都是围绕这微服务的安全在讲一些东西,包括微服务本身api的安全、网关的安全、怎么去做安全中心,包括认证服务器,权限的服务。权限的设计,怎么来实现SSO。然后sentinel来实现统一的熔断,限流,这些都是和安全相关的知识点。前面讲的这些东西都是保证你的服务不出问题的。但是一个永远不出现问题的服务是不可能存在的,这时候我们就需要一些可见性的保证,让我来及时的发现问题,然后去排查这些问题。

本节会讲三套系统分别对应调用链监控、指标监控、日志监控
各自的特点,
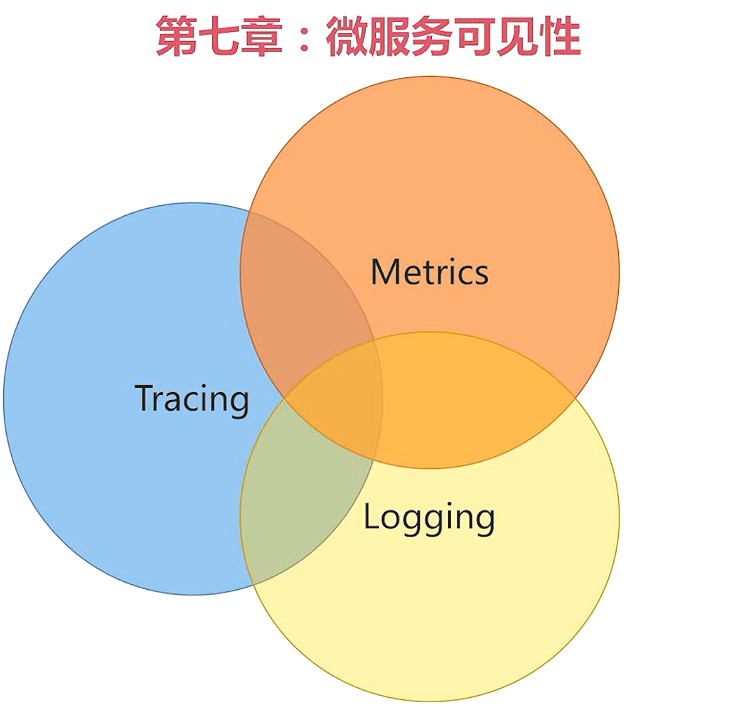
Metrics:所有可以用数字表示的都可以用Metrics来追踪,比如说你现在内存的使用情况,cpu使了几个核,当前的qps是多少,服务的响应时间是多少,等等这些可以用一个数字或者是几个数字来表示的信息都可以用Metrics来追踪。
Metrics在时间上是聚合的,例如可以统计在一分钟之内系统流量是多少,或者一小时你的系统流量是多少,一分钟内你系统的平均响应时间是多少,可以按照一定的时间维度把这些数据来聚合。
Logging:描述一些离散的不连续的事件,它里面是一些文字的信息。比如说一个用户下了一个订单,几点几分下的这个订单,下的订单买的是什么东西,订单金额是多少,下单成功了还是失败了。这些信息都是可以用日志来追踪的,
Tracing:最大的特点是,针对单次请求的,追踪的是在这一次请求里面,发生了什么事情,比如说你调了一个下单的服务,那么在调用这个下单服务一次请求里面,发生了什么事情,指从订单服务又调用了哪个服务,比如说从订单服务又调用了用户服务,又调用了商品服务、价格服务,然后你访问了哪个数据库,执行了什么sql,发了什么消息,消息又被谁消费了。在这一个下单服务,一次请求里面,发生了什么事,然后这些信息你可以通过一个Tracing系统来它展示出来,让你可以非常清晰的来看到。
从重要性上来说,最重要的应该是Logging,它是我们系统或者应用的一个记录。问题排查取证的依据,它的优先级是最高的。出了问题我们马上第一反应就是看日志。
优先级第二高的就是Metrics,度量系统是我们关注事件的聚合,比如说你的服务是不是健康,响应时间是不是在你希望的时间之内,这些都是你要关注的事情。当达到一定指标的时候,我们会争对这个关注的事情指标设置一个告警,然后会有自适应的机制,争对Metrics可以有很多自动化的东西,比如说当我的系统响应时间到了一定程度以后,我就报警,或者是自动扩容,加一些机器来分担我的压力。
最后是tracing。主要是优化系统,排插问题的一个高阶的方法,通过tracing我们可以发现在一次请求之中,它的瓶颈在哪里,比如说刚才举的例子,你调了订单服务,你又调了用户服务,商品服务,价格服务,那么现在你订单服务响应时间变慢了,那么问题到底出在哪里,是出在订单服务本身还是出在我依赖的商品服务,或者价格服务。tracing是帮我们定位问题,优化系统的一个手段。
下面从Metrics来开始。