https://www.cnblogs.com/qingyunzong/p/8707885.html
http://www.360doc.com/content/16/1006/23/15257968_596289341.shtml
1.什么是hive
基于 Hadoop 的一个数据仓库工具:
hive本身不提供数据存储功能,使用HDFS做数据存储,
hive也不分布式计算框架,hive的核心工作就是把sql语句翻译成MR程序
hive也不提供资源调度系统,也是默认由Hadoop当中YARN集群来调度
可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能
(1.1)hive的优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手);
- 避免了去写MapReduce,减少开发人员的学习成本;
- 统一的元数据管理,可与impala/spark等共享元数据;
- 易扩展(HDFS+MapReduce:可以扩展集群规模;支持自定义函数);
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析…
- Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求 不高的场合;
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执 行延迟比较高。
(1.2)hive的缺点(局限性)
(1)hive的HQL表达能力有限
1)迭代式算法无法表达,比如pagerank
2)数据挖掘方面,比如kmeans
(2)hive的效率比较低
1)hive自动生成的mapreduce作业,通常情况下不够智能化
2)hive调优比较困难,粒度较粗
3)hive可控性差
2.hive和Hadoop关系
Hive利用HDFS存储数据,利用MapReduce查询数据
3.hive和传统数据库的区别
总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
4.hive数据的存储
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
² db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
² table:在hdfs中表现所属db目录下一个文件夹
² external table:与table类似,不过其数据存放位置可以在任意指定路径
² partition:在hdfs中表现为table目录下的子目录
² bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
5.hive架构
Hive架构,Driver是核心,Driver可以解析语法,最难的就是解析sql的语法,只要把SQL的语法解析知道怎么做了,它内部用MapReduce模板程序,它很容易把它组装起来,比如做一个join操作,最重要的是识别语法,认识你的语法,知道你语法有什么东西,解析出来会得到一个语法树,根据一些语法树,去找一些MapReduce模板程序,把它组装起来
例如:有二个表去join,内部有一个优化机制,有一个默认值,如果小表小于默认值,就采用map—join ,如果小表大于默认值,就采用reduce——join(其中map——join是先把小表加载到内存中),组装时候就是输入一些参数:比如:你的输入数据在哪里,你的表数据的分隔符是什么,你的文件格式是什么:然而这些东西是我们建表的时候就指定了,所以这些都知道了,程序就可以正常的跑起来
Hive有了Driver之后,还需要借助一个非常重要的东西,他就是Metastore,Metastore里边记录了hive中所建的:库,表,分区,分桶他的一些信息,描述信息都在Metastore,如果用了MySQL作为hive的Metastore:需要注意的是:你建的表不是直接建在MySQL里边了,而是把这个表的很多描述信息分在了MySQL里边记录了,什么tables表,字段表。你建的hive里边的表存在HDFS上,hive会自动把他的目录规划/usr/hive/warehouse/库文件/库目录/表目录 你的数据就在目录下,
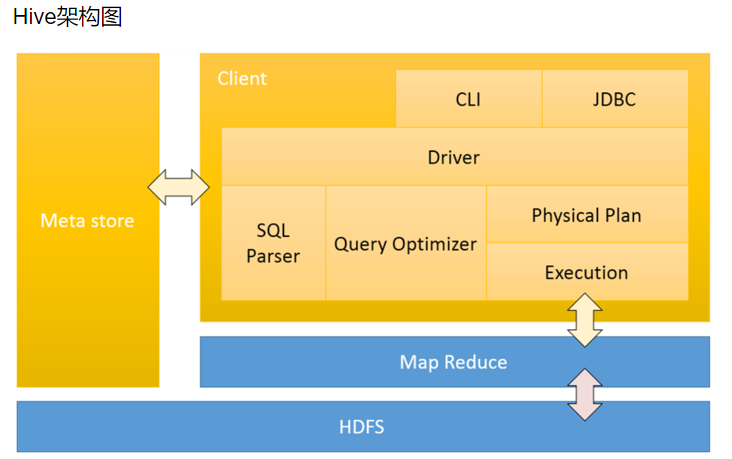
-
client 三种访问方式
1、CLI(hive shell)、command line interface(命令行接口)2、JDBC/ODBC(java访问hive),3、WEBUI(浏览器访问hive) -
Meta store 元数据存储元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列、分区字段、表的类型(是否是外部表)、表的数据所在的目录等;默认存储在自带的derby数据库中,推荐使用采用MySQL存储Metastore;
-
Driver包含:解析器、编译器、优化器、执行器;1、解析器:将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工 具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否 存在、SQL语义是否有误(比如select中被判定为聚合的字段在group by中是 否有出现);2、编译器:将AST编译生成逻辑执行计划; 优化器:对逻辑执行计划进行优化;3、执行器:把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/TEZ/Spark;
-
举例 select substring(ip,0,4) ip_prex from bg_log ;执行顺序:首先在metastore查询-->sql解析-->查询优化--->物理计划-->执行MapReduce
6.内部表和外部表
内部表:删除表的时候,会删除元数据和数据
外部表:删除表的时候,只删除元数据,不删除数据
内部表和外部表使用场景

7.分桶
分桶操作:按照用户创建表时指定的分桶字段进行hash散列
跟MR中的HashPartitioner的原理一模一样
MR中:按照key的hash值去模除以reductTask的个数
Hive中:按照分桶字段的hash值去模除以分桶的个数
hive分桶操作的效果:
把一个文件按照某个特定的字段和桶数 散列成多个文件
好处:
1、方便抽样
2、提高join查询效率
8.分区
Hive分区表的作用:让你做统计的时候少统计,把我们的数据放在多个文件夹里边,我们统计时候,可以指定分区,这样范围就会小一些,这样就减少了运行的时间
9 .简短理解Hive概念
Hive是由Facebook开源
Hive是基于Hadoop的一个开源数据仓库工具
能够将结构化数据映射成为一张数据库表(二维表),提供类SQL查询语言(支持绝大多数SQL标准语法)
底层依赖于HDFS存储数据,Hive的本质是HQL语句转化成MR程序,提交给Hadoop运行
Hive的适应场景:只适合做海量离线数据的统计分析
Hive核心组件
解释器:把HQL语句转换成一颗抽象语法树
编译器:把抽象语法树转换成一系列MR程序
Hive的底层有一系列的MR模板(Operation:GroupByOperation, JoinOperation)
优化器:执行这一系列MR程序的优化
执行器:组织相应的资源提交给Hadoop集群
10.Hive 的所有跟数据相关的概念
db: myhive, table: student 元数据:hivedb
1、Hive的元数据
指的是 myhive 和 student等等的库和表的相关的各种定义信息
该元数据都是存储在mysql中的
myhive是hive中的一个数据库的概念,其实就是HDFS上的一个文件夹,跟mysql没有多大的关系
myhive是hive中的一个数据库,那么就会在元数据库hivedb当中的DBS表中存储一个记录
这一条记录就是myhive这个hive中数据的相关描述信息
其实,hive中创建一个表,就相当于在hivedb中TBLS表中插入一条记录,并且在HDFS上项目的库目录下创建一个子目录
一个hive数据数据仓库就依赖于一个RDBMS中的一个数据库,一个数据库实例对应于一个Hive数据仓库
存储于该hive数据仓库中的所有数据的描述信息,都统统存储在元数据库hivedb中
myhive 和 hivedb的区别:
myhive是hive中的数据库: 用来存储真实数据
hivedb是mysql中的数据库: 用来多个类似myhive库的真实数据的描述数据
存储在hive数据仓库中的真实数据 student.txt
元数据 : 一定指跟 hivedb相关,跟mysql相关
数据: HDFS上的对应表的目录下的文件
HDFS上的数据和元数据
数据:block块
元数据:描述和管理这些block信息的数据, 由namenode管理
