P(y|X)=P(y)*P(X|y)/P(X)
样本中的属性相互独立;
![]()
原问题的等价问题为:

数据处理
为防止P(y)*P(X|y)的值下溢,对原问题取对数,即:

注意:若某属性值在训练集中没有与某个类同时出现过,则直接P(y)或P(X|y)可能为0,这样计算出P(y)*P(X|y)的值为0,没有可比性,且不便于求对数,因此需要对概率值进行“平滑”处理,常用拉普拉斯修正。
先验概率修正:令Dy表示训练集D中第y类样本组合的集合,N表示训练集D中可能的类别数

即每个类别的样本个数都加 1。
类条件概率:另Dy,xi表示Dc中在第 i 个属性上取值为xi的样本组成的集合,Ni表示第 i 个属性可能的取值数
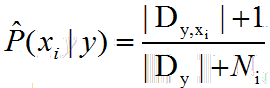
即该类别中第 i 个属性都增加一个样本。
--------------------------------------------------------------
数据预处理
训练模型

测试样本

函数调用

参考
python朴素贝叶斯分类MNIST数据集
import struct
from numpy import *
import numpy as np
import time
def read_image(file_name):
#先用二进制方式把文件都读进来
file_handle=open(file_name,"rb") #以二进制打开文档
file_content=file_handle.read() #读取到缓冲区中
offset=0
head = struct.unpack_from('>IIII', file_content, offset) # 取前4个整数,返回一个元组
offset += struct.calcsize('>IIII')
imgNum = head[1] #图片数
rows = head[2] #宽度
cols = head[3] #高度
images=np.empty((imgNum , 784))#empty,是它所常见的数组内的所有元素均为空,没有实际意义,它是创建数组最快的方法
image_size=rows*cols#单个图片的大小
fmt='>' + str(image_size) + 'B'#单个图片的format
for i in range(imgNum):
images[i] = np.array(struct.unpack_from(fmt, file_content, offset))
# images[i] = np.array(struct.unpack_from(fmt, file_content, offset)).reshape((rows, cols))
offset += struct.calcsize(fmt)
return images
#读取标签
def read_label(file_name):
file_handle = open(file_name, "rb") # 以二进制打开文档
file_content = file_handle.read() # 读取到缓冲区中
head = struct.unpack_from('>II', file_content, 0) # 取前2个整数,返回一个元组
offset = struct.calcsize('>II')
labelNum = head[1] # label数
# print(labelNum)
bitsString = '>' + str(labelNum) + 'B' # fmt格式:'>47040000B'
label = struct.unpack_from(bitsString, file_content, offset) # 取data数据,返回一个元组
return np.array(label)
def loadDataSet():
#mnist
train_x_filename="train-images-idx3-ubyte"
train_y_filename="train-labels-idx1-ubyte"
test_x_filename="t10k-images-idx3-ubyte"
test_y_filename="t10k-labels-idx1-ubyte"
# #fashion mnist
# train_x_filename="fashion-train-images-idx3-ubyte"
# train_y_filename="fashion-train-labels-idx1-ubyte"
# test_x_filename="fashion-t10k-images-idx3-ubyte"
# test_y_filename="fashion-t10k-labels-idx1-ubyte"
train_x=read_image(train_x_filename)#60000*784 的矩阵
train_y=read_label(train_y_filename)#60000*1的矩阵
test_x=read_image(test_x_filename)#10000*784
test_y=read_label(test_y_filename)#10000*1
train_x=normalize(train_x)
test_x=normalize(test_x)
# #调试的时候让速度快点,就先减少数据集大小
# train_x=train_x[0:1000,:]
# train_y=train_y[0:1000]
# test_x=test_x[0:500,:]
# test_y=test_y[0:500]
return train_x, test_x, train_y, test_y
def normalize(data):#图片像素二值化,变成0-1分布
m=data.shape[0]
n=np.array(data).shape[1]
for i in range(m):
for j in range(n):
if data[i,j]!=0:
data[i,j]=1
else:
data[i,j]=0
return data
#(1)计算先验概率及条件概率
def train_model(train_x,train_y,classNum):#classNum是指有10个类别,这里的train_x是已经二值化,
m=train_x.shape[0]
n=train_x.shape[1]
# prior_probability=np.zeros(n)#先验概率
prior_probability=np.zeros(classNum)#先验概率
conditional_probability=np.zeros((classNum,n,2))#条件概率
#计算先验概率和条件概率
for i in range(m):#m是图片数量,共60000张
img=train_x[i]#img是第i个图片,是1*n的行向量
label=train_y[i]#label是第i个图片对应的label
prior_probability[label]+=1#统计label类的label数量(p(Y=ck),下标用来存放label,prior_probability[label]除以n就是某个类的先验概率
for j in range(n):#n是特征数,共784个
temp=img[j].astype(int)#img[j]是0.0,放到下标去会显示错误,只能用整数
conditional_probability[label][j][temp] += 1
# conditional_probability[label][j][img[j]]+=1#统计的是类为label的,在每个列中为1或者0的行数为多少,img[j]的值要么就是0要么就是1,计算条件概率
#将概率归到[1.10001]
for i in range(classNum):
for j in range(n):
#经过二值化的图像只有0,1两种取值
pix_0=conditional_probability[i][j][0]
pix_1=conditional_probability[i][j][1]
#计算0,1像素点对应的条件概率
probability_0=(float(pix_0)/float(pix_0+pix_1))*10000+1
probability_1 = (float(pix_1)/float(pix_0 + pix_1)) * 10000 + 1
conditional_probability[i][j][0]=probability_0
conditional_probability[i][j][1]=probability_1
return prior_probability,conditional_probability
#(2)对给定的x,计算先验概率和条件概率的乘积
def cal_probability(img,label,prior_probability,conditional_probability):
probability=int(prior_probability[label])#先验概率
n=img.shape[0]
# print(n)
for i in range(n):#应该是特征数
probability*=int(conditional_probability[label][i][img[i].astype(int)])
return probability
#确定实例x的类,相当于argmax
def predict(test_x,test_y,prior_probability,conditional_probability):#传进来的test_x或者是train_x都是二值化后的
predict_y=[]
m=test_x.shape[0]
n=test_x.shape[1]
for i in range(m):
img=np.array(test_x[i])#img已经是二值化以后的列向量
label=test_y[i]
max_label=0
max_probability= cal_probability(img,0,prior_probability,conditional_probability)
for j in range(1,10):#从下标为1开始,因为初始值是下标为0
probability=cal_probability(img,j,prior_probability,conditional_probability)
if max_probability<probability:
max_probability=probability
max_label=j
predict_y.append(max_label)#用来记录每行最大概率的label
return np.array(predict_y)
def cal_accuracy(test_y,predict_y):
m=test_y.shape[0]
errorCount=0.0
for i in range(m):
if test_y[i]!=predict_y[i]:
errorCount+=1
accuracy=1.0-float(errorCount)/m
return accuracy
if __name__=='__main__':
classNum=10
print("Start reading data...")
time1=time.time()
train_x, test_x, train_y, test_y=loadDataSet()
train_x=normalize(train_x)
test_x=normalize(test_x)
time2=time.time()
print("read data cost",time2-time1,"second")
print("start training data...")
prior_probability, conditional_probability=train_model(train_x,train_y,classNum)
for i in range(classNum):
print(prior_probability[i])#输出一下每个标签的总共数量
time3=time.time()
print("train data cost",time3-time2,"second")
print("start predicting data...")
predict_y=predict(test_x,test_y,prior_probability,conditional_probability)
time4=time.time()
print("predict data cost",time4-time3,"second")
print("start calculate accuracy...")
acc=cal_accuracy(test_y,predict_y)
time5=time.time()
print("accuarcy",acc)
print("calculate accuarcy cost",time5-time4,"second")