requests
requests模块的介绍:能够帮助我们发起请求获取响应
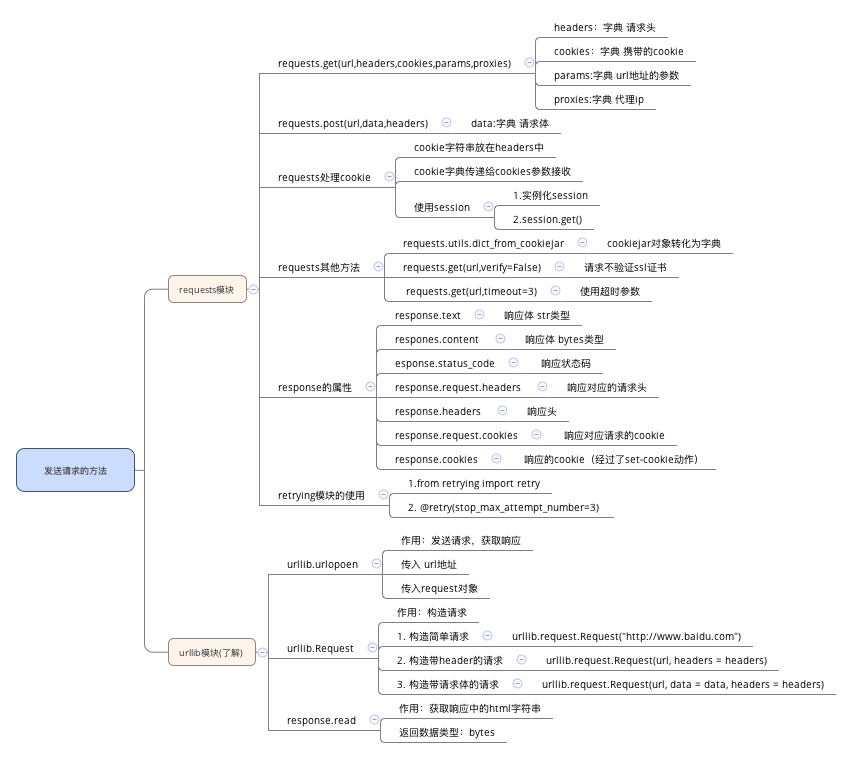
requests的基本使用:requests.get(url)
以及response常见的属性:
response.text 响应体 str类型
respones.content 响应体 bytes类型
response.status_code 响应状态码
response.request.headers 响应对应的请求头
response.headers 响应头
response.request._cookies 响应对应请求的cookie
response.cookies 响应的cookie(经过了set-cookie动作)
掌握 requests.text和content的区别:text返回str类型,content返回bytes类型
掌握 解决网页的解码问题:
response.content.decode()
response.content.decode("GBK")
response.text
掌握 requests模块发送带headers的请求:requests.get(url, headers={})
掌握 requests模块发送带参数的get请求:requests.get(url, params={})
cookie字符串可以放在headers字典中,键为Cookie,值为cookie字符串
可以把cookie字符串转化为字典,使用请求方法的cookies参数接收
使用requests提供的session模块,能够自动实现cookie的处理,包括请求的时候携带cookie,获取响应的时候保存cookie
requests.utils.dict_from_cookiejar能够实现cookiejar转化为字典
请求方法中添加verify=False能够实现请求过程中不验证证书
请求方法中添加timeout能够实现强制程序返回结果的能够,否则会报错
retrying模块能够实现捕获函数的异常,反复执行函数的效果,和timeout配合使用,能够解决网络波动带来的请求不成功的问题
urllib
urllib.request中实现了构造请求和发送请求的方法
urllib.request.Request(url,headers,data)能够构造请求
urllib.request.urlopen能够接受request请求或者url地址发送请求,获取响应
urllib.parse.urlencode(data_dict).encode('utf-8')之后才能传入data参数
response.read()能够实现获取响应中的bytes字符串