面向过程编程
核心过程二字,过程指的是解决问题的步骤,即先干什么,再干什么
基于该思想编写程序就好比在设计一条流水线,是一种机械的思维方式。
优点:复杂的问题流程化,进而简单化
缺点:扩展性差
#小例子
#接受用户输入,进行用户名合法性校验,拿到合法的用户名 def check_user(): name=input('username>>').strip() while True: if name.isalpha(): return name else: print('用户名必须全为字母傻叉') user=check_user() print(user) # 接收用户输入密码,进行密码合法性校验,拿到合法的密码 def check_pwd(): while True: pwd1=input('password>>:').strip() if len(pwd1)<5: print('密码长度至少5位') continue pwd2=input('again>>:').strip() if pwd1==pwd2: return pwd1 else: print('两次输入的密码不一致') pwd=check_pwd() print(pwd) # 将合法的用户名与密码写入文件 def insert(user,pwd,path='db.txt'): with open(path,mode='a',encoding='utf-8') as f: f.write('%s:%s '%(user,pwd)) def register():#注册功能分为三个小步骤去实现 user=check_user() pwd=check_pwd() insert(user,pwd) register()#实现成功
# 接口层
#
# 数据处理层
#
# # 只负责读写文件
#用户功能层
def register():# continue #后面有代码的情况下加continue
while True:#检测用户名
name=input('请输入用户名>>:').strip()
#检测用户是否重复,如果重复了则重新输入,否则break
res=select(name)#res=['egon','123']
if res:
print('用户已经存在')
else:
break
while True:#检测密码
pwd1=input('pwd>>:').strip()
pwd2 = input('pwd>>:').strip()
if pwd1 !=pwd2:
print('两次输入密码不一致,重新输入')
else:
break
def tell_info():
name=input('>>:').strip()
info=select(name)
print(info)
#接口层
def check_user_interface(name):
res=select(name)
if res:
return True
else:
return False
#数据处理层
def select(name):#与用户交互的功能
with open('db.txt','r',encoding='utf-8')as f:
for line in f:
info=line.strip('
').split(':')
if name ==info[0]:
return info
#先让用户处理,结果交给接口层,接口层再交给数据处理层
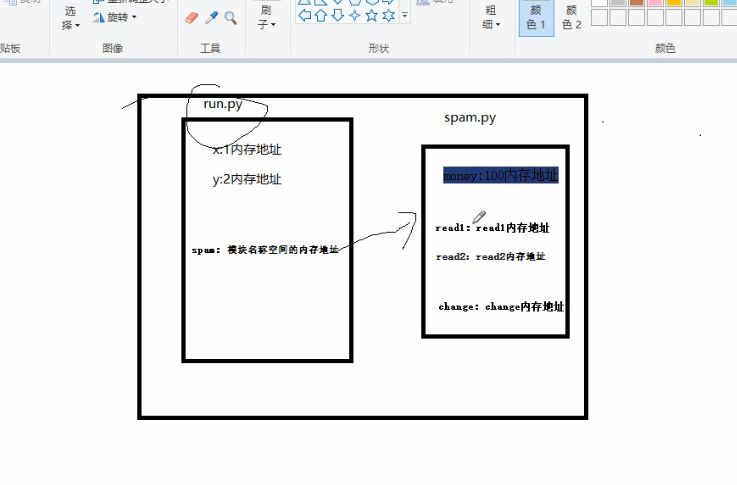
1.什么是模块
模块是一系列功能的集合体
常见的模块形式(自定义模块,第三方模块,内置模块):
1.一个moudle.py文件就是一个模块,文件名是moudle.py,而模块名是moudle
2.一个包含有__int__.py的文件夹也是模块
3.已被编译为共享库或DLL的C或C++的扩展
4.使用c编写并链接到python解释器的内置模块
2.为什么要用模块
1.用第三方或者内置模块是一种拿来主义,可以极大的提升开发效率
2.自定义模块即将我们自己程序中需要用到的公共的功能写入一个python文件
然后程序的各部分组建可以通过导入的方式来引用/中用模块中自定义的功能
3.如何使用模块
大前提:模块是被执行文件导入使用,模块的导入必须搞明白谁是执行文件,谁是被导入的模块
import
首次import m1导入模块都发生三件事:
1、先创建一个模块的名称空间
2、执行m1.py将执行过程中产生的名称都放入模块的名称空间中
3、在当前执行文件中拿到一个名字m1,该名字是指向模块的名称空间的
使用方法:指名道姓的访问m1名称空间中的名字 func,优点是不会与当前名称空间中的名字相冲突,
缺点是每次访问都要加上m1.func
from.....import
首次from m1 import func导入模块都发生三件事:
1、先创建一个模块的名称空间
2、执行m1.py,将执行过程中产生的名称都放入模块的名称空间中
3、在当前执行文件中直接拿到一个功能名func,该名字是直接指向模块名称空间中某一个功能的
使用方法:直接使用功能即可,优点是无需加任何前缀,缺点是容易与当前名称空间中的名字冲突
def func()
pass
func()
模块的搜索路径
内存----->内置模块----->sys.path
1个py文件就是一个模块,在导入时必须从某一个文件夹下找到该py文件
模块的搜索路径指的就是在导入模块时需要检索的文件夹
导入模块时查找模块的顺序是
1、先从内存中已经导入的模块中寻找
2、内存中如果没有找内置的模块
3、环境变量sys.path中寻找
强调:sys.path的第一个值是当前执行文件所在的文件夹
import sys print(sys.path) #当前文件所在的环境变量 import sys sys.path.append(r'C:UsersAdministratorPycharmProjectsuntitledday16dir') print(sys.path) #关于报错 内存没有,内置没有,找了一圈都没有,所以报错了 from dir import mmm mmm.f1()
********强烈区分开谁是执行文件,谁是被导入的模块
区分python文件的两种用途