游戏显卡中RTX2080Ti可以说是业界翘楚了,虽然不是专门为深度学习而设计,但是在深度学习上的性能表现也是不错滴。而云端深度学习卡一般都是以Tesla系列为主,虽然号称专业的深度学习卡,但是某些型号也是很渣。

不知道有没有人想过把2080ti也扔到云端,然后可以按需付费,或者进行月租。肯定有吧,而且现在也有人做了。
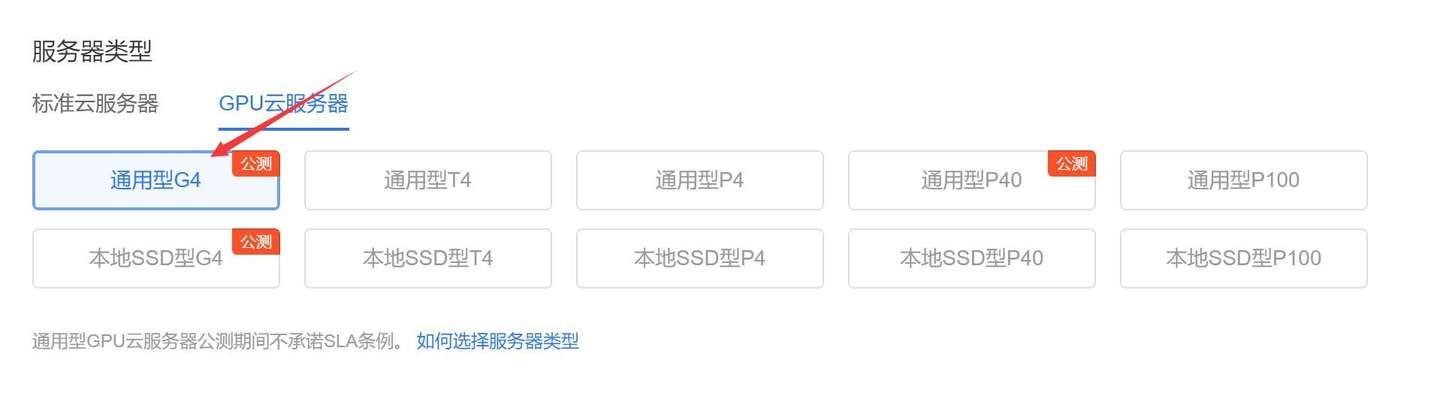
滴滴云正在公测G4云服务(就是2080ti)。之前我做过GPU服务器的比较,滴滴云的性价比是非常高,质量基本也是有保障。很幸运我也拿到了免费测试的机会(真香)。
下面就分享下在滴滴云的2080ti 跑DeepFaceLab的体验。同时也可以回答下部分群友的问题。具体而完整的安装过程我会在另一篇文章中说明,本文主要就是看看跑DFL性能如何。
测试系统为: Windows Server 2019
测试的DFL版本为:20200315
测试素材:软件自带
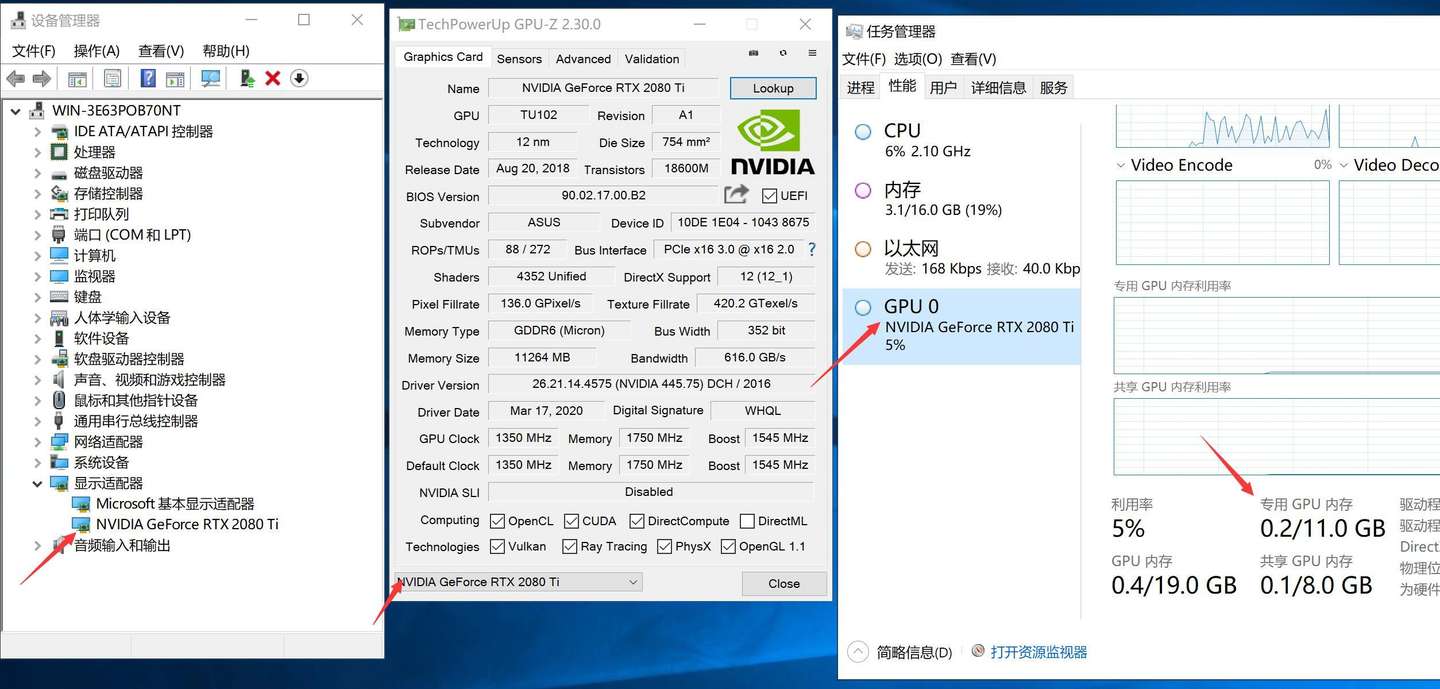
登陆系统,安装完驱动后可以通过设备管理器或者GPU-Z或者任务管理器看到看到显卡型号为NVIDIA Ge Force RTX2080Ti,显存11GB
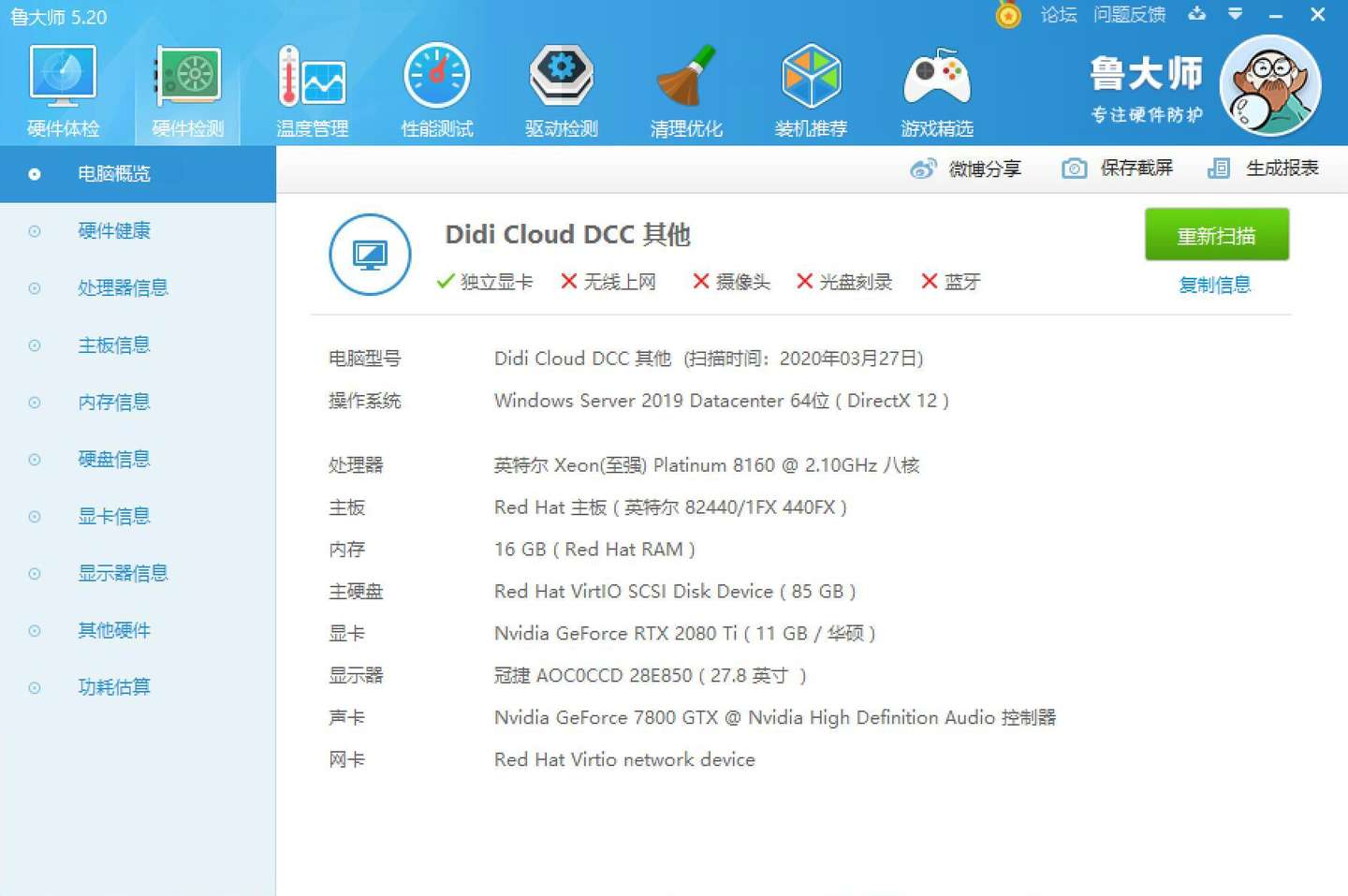
通过娱乐大师可以看到这台云端电脑的基本配置。其他配置我不关心,我就抓两个核心,显存11G,内存16G。下面就直接跑软件了,分别测试了,提取,模型,合成这几个环节的速度,大家可以对比一下自己的显卡,有2080ti的也可以看看有啥差别。
提取环节:
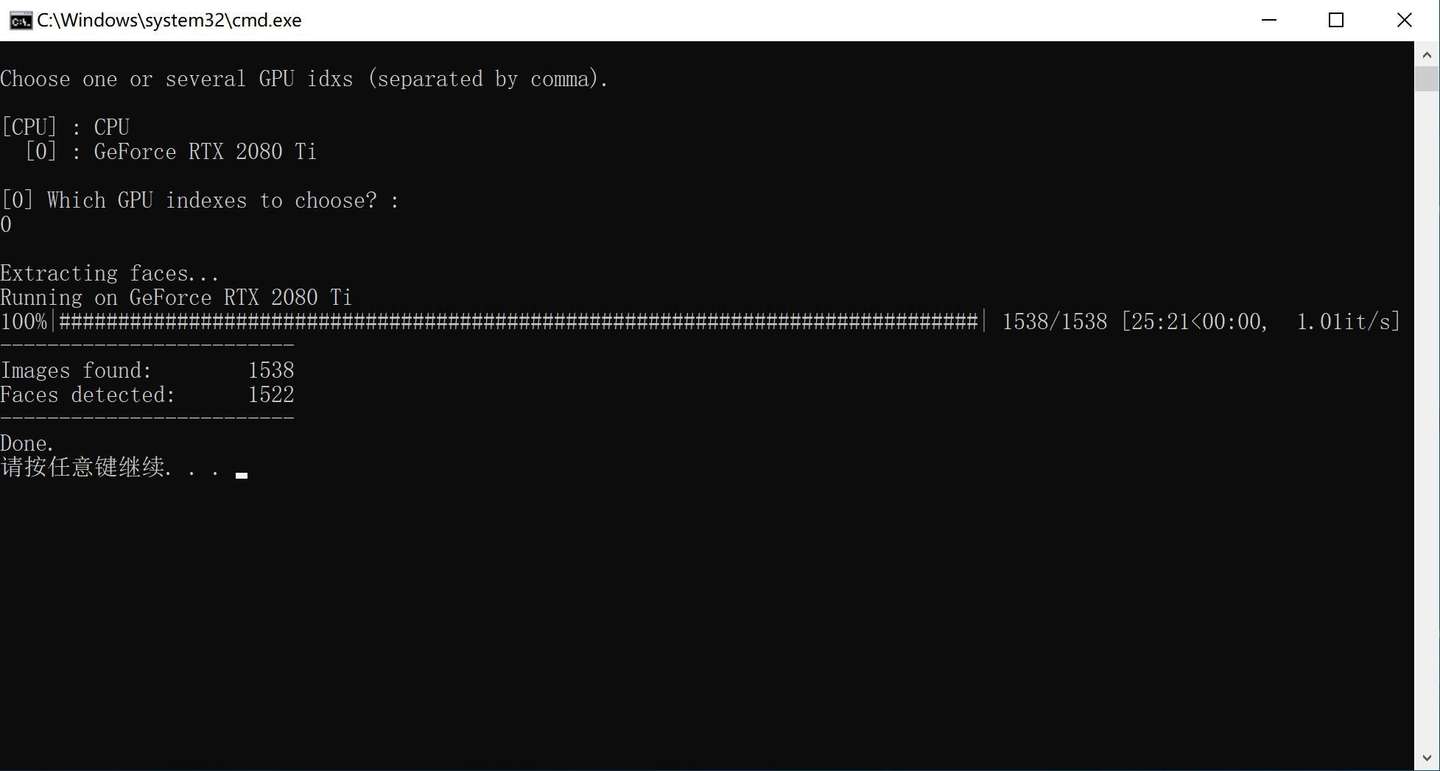
提取dst 头像的时候花了25分钟,每秒钟只处理了1张图片,这个性能让我陷入深深的怀疑,我怀疑这个阶段主要用的不是GPU而是CPU,否则没有理由2080ti不如我的1070吧?
训练环节。
这个环节没其他的,就是看单次迭代速度。
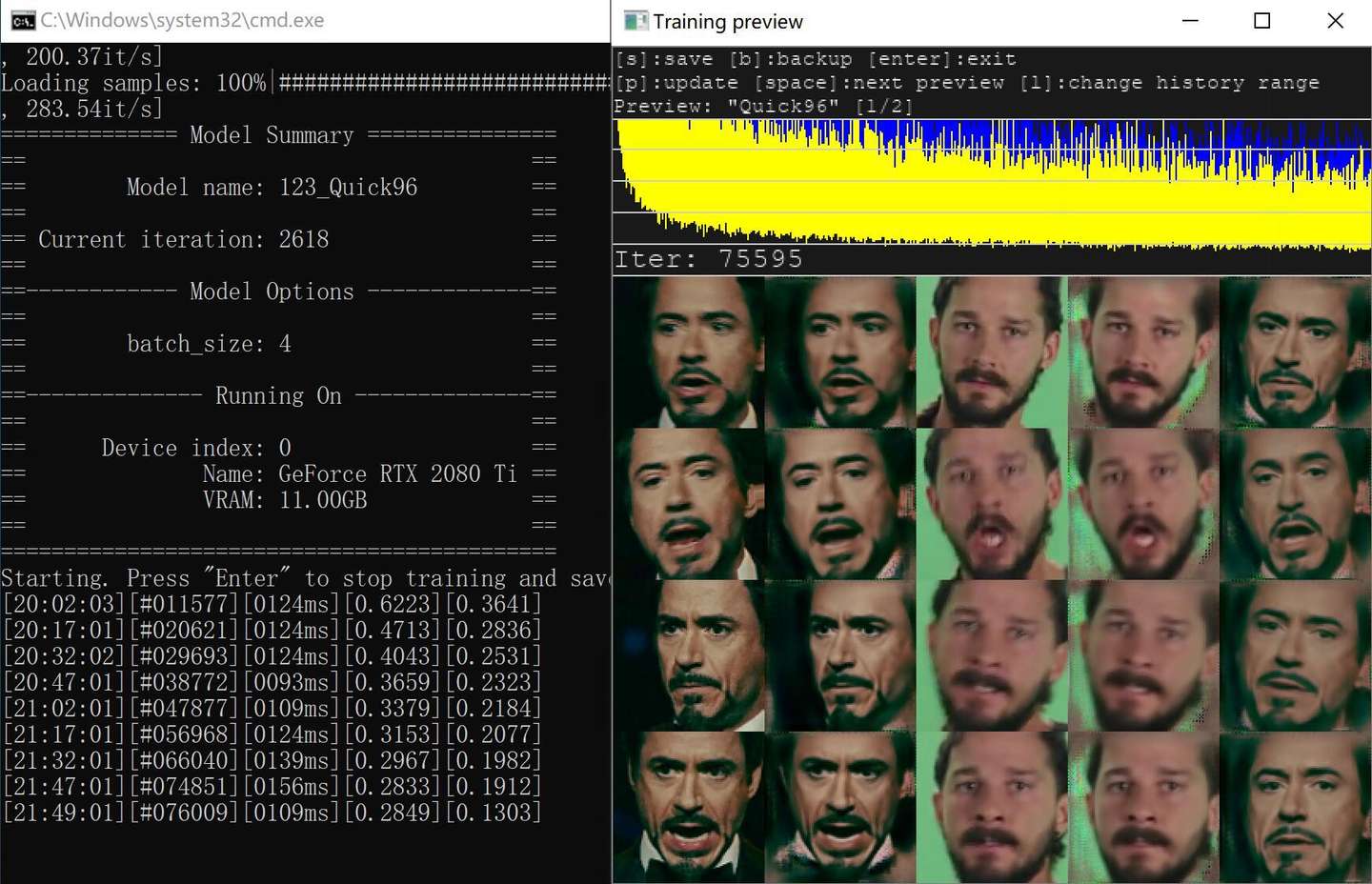
训练Quick96模型, 单次迭代时间为94ms

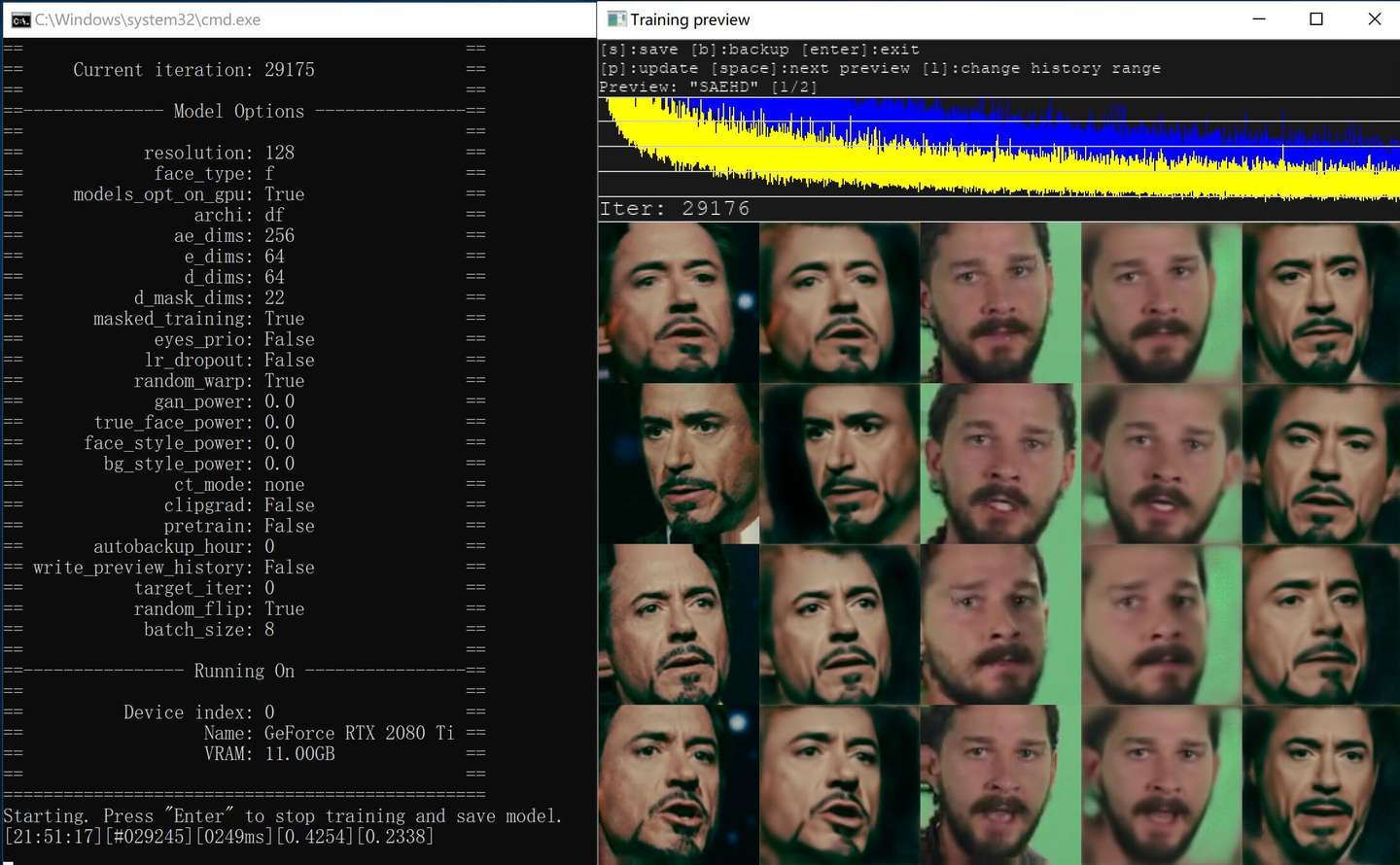
训练SAEHD模型,默认参数,单次迭代时间为249ms左右
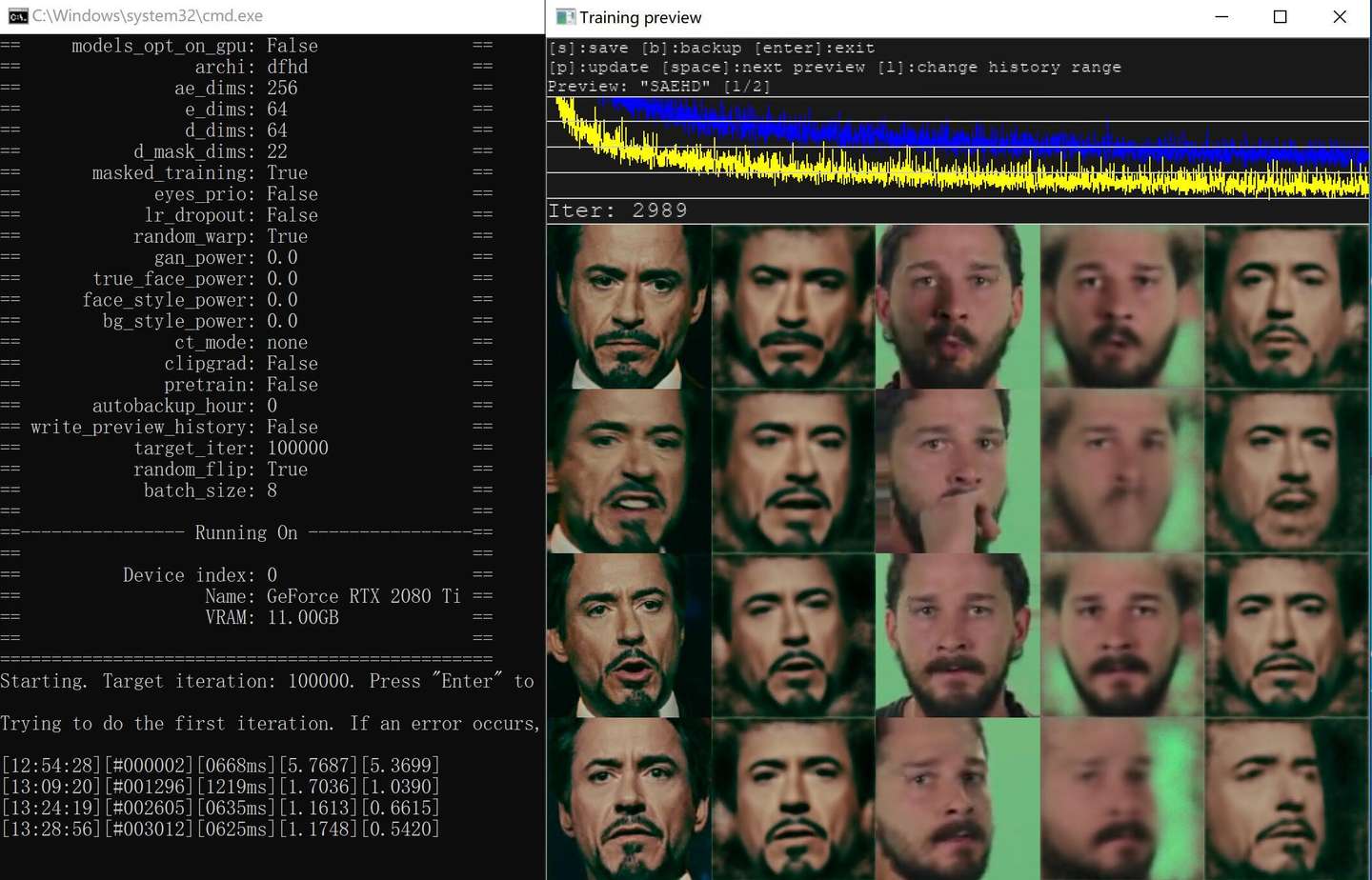
训练SAEHD模型,结构archi为dfhd,其他默认,单次迭代时间为650ms左右。
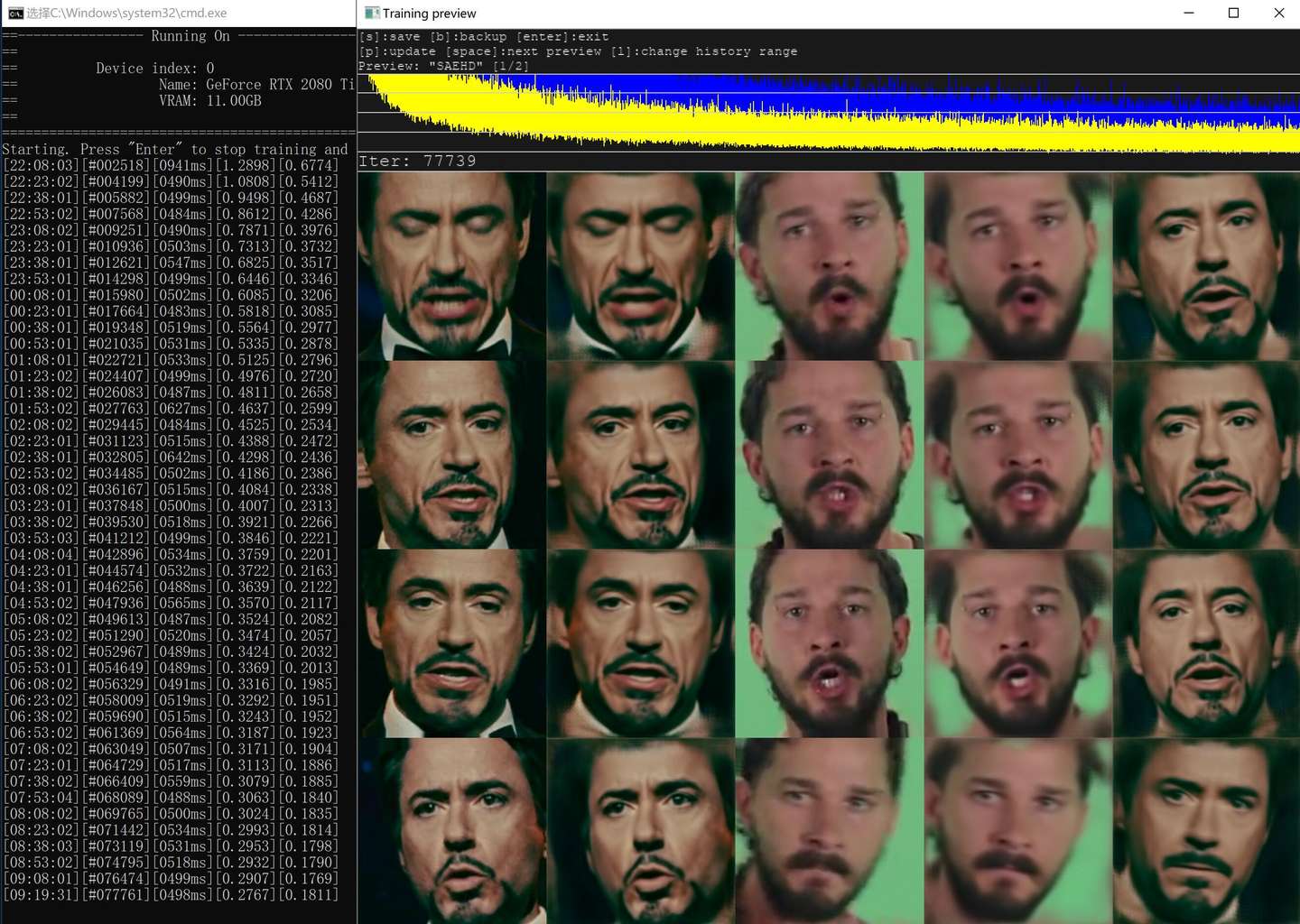
训练SAEHD模型,像素Resolution 为192,其他默认,单次迭代时间为500ms左右。
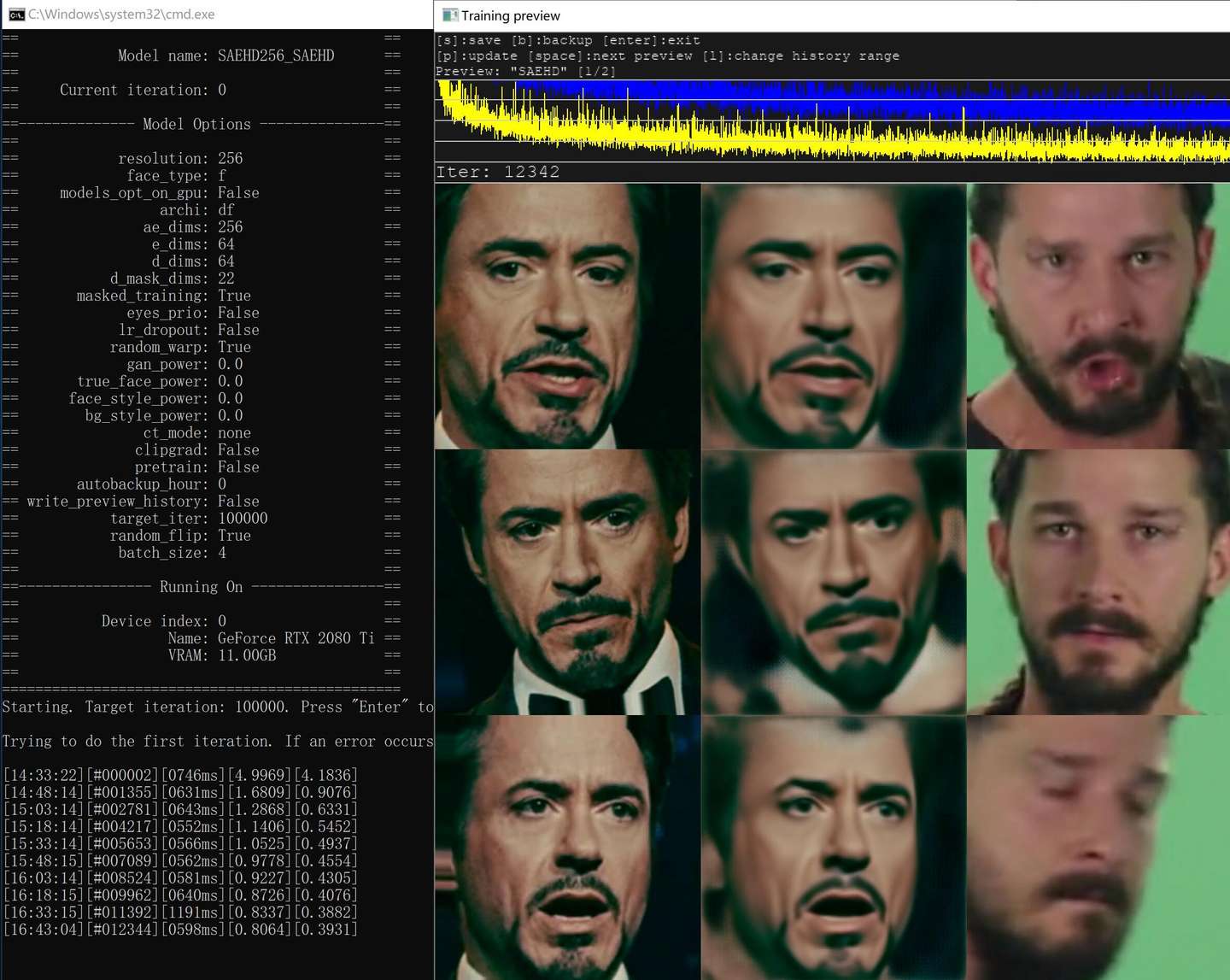
训练SAEHD模型,像素Resolution 为256 ,bs=4,其他默认,单次迭代时间为600ms左右。
合成环节:
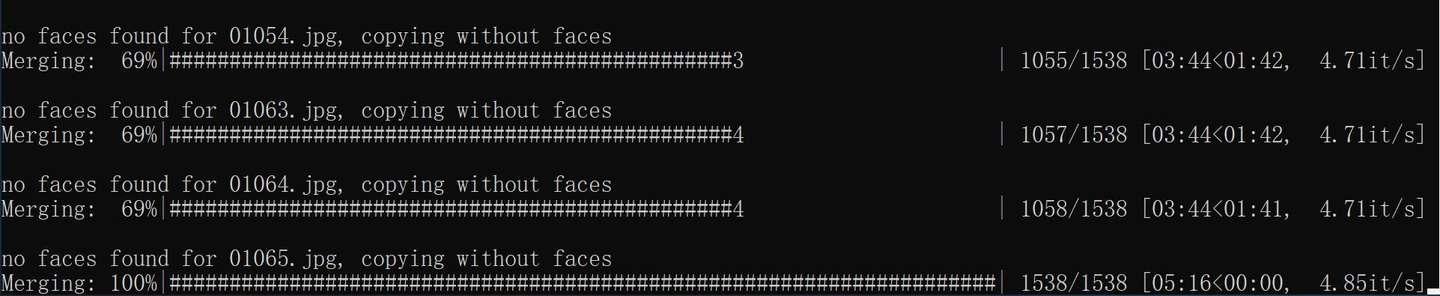
使用时间5分16秒,每秒处理4.85张图片。
下面以训练环节,做一个简单的横向对比。
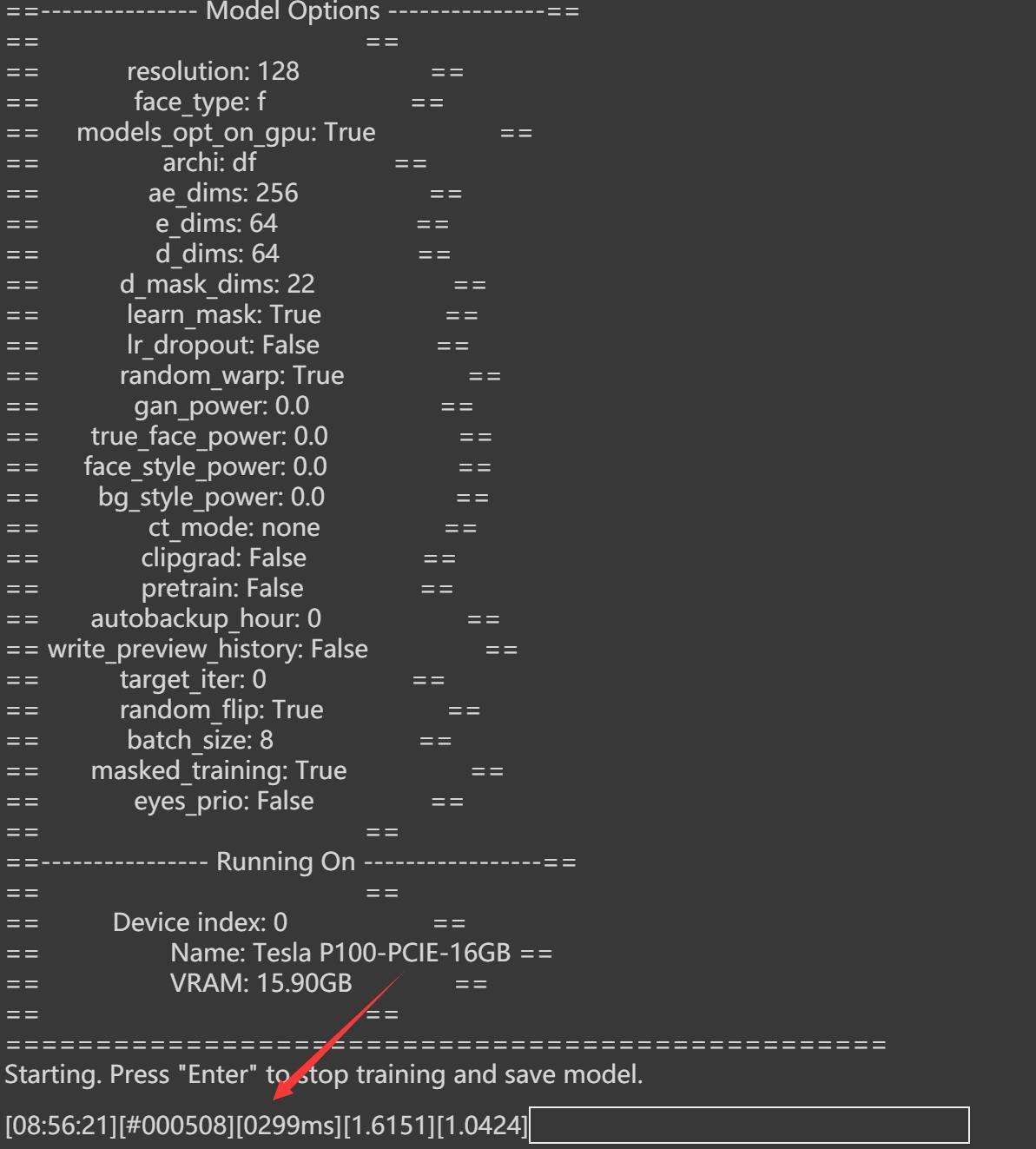
Colab上P100默认参数时的数据,单次迭代299ms。
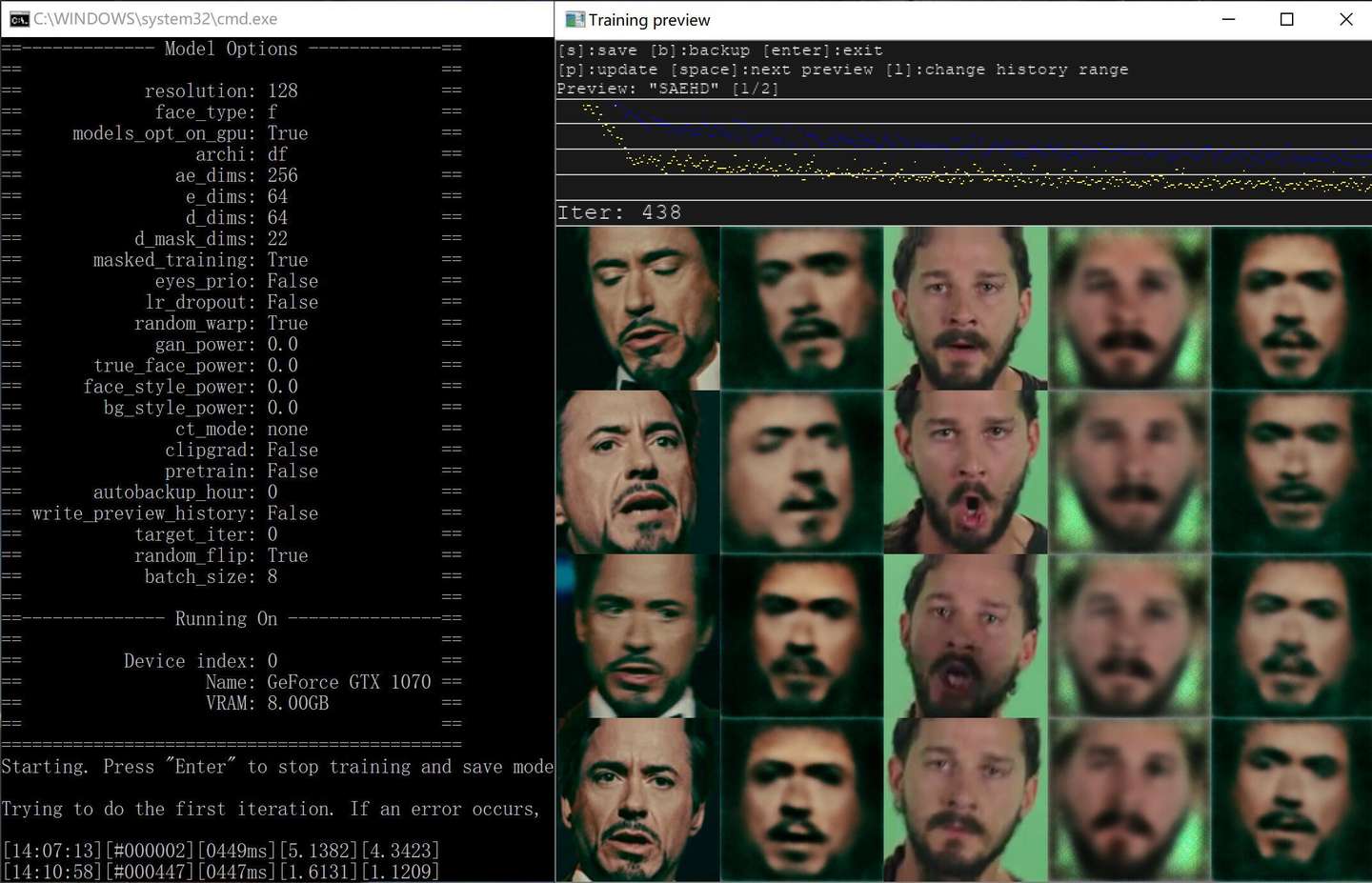
1070默认参数下的数据,单次迭代时间449ms。
2080ti 上面已经给出了,单次迭代时间为249ms的样子。
2080ti吊打1070这是必然,快得不是一丁半点。同时2080ti 还略强于P100。K80,P4,P40,T4这些也只能是弟弟了。虽然是游戏卡,但是干起来还是挺猛。
所以不管是云端还是本地,只要钱管够,买2080ti跑换脸还是非常不错的选择。做其他深度学习的研究也不错。如果不想本地烧显卡,占用游戏时间,或者想做一些云端服务搞APP之类,那么搞个云端的最爽了。只需要通过远程桌面连接,操作和本地没啥差别,无论何时何都可以轻松接入。