Relation Structure-Aware Heterogeneous Information Network Embedding(RHINE) (AAAI 2019)
本文结构
- (1) 解决问题
- (2) 主要贡献
- (3) 算法原理
- (4) 实验结果
- (5) 参考文献
在文献阅读的基础上加入了自己的理解,为文献阅读笔记,如有错误望不吝指出。
(1) 解决问题
现存的HIN表征算法通常一个模型用到底,没有对不同关系进行区分,这不可避免地会影响网络表征的能力。
(2) 主要贡献
Contribution 1. 是第一个来探索HIN中关系区别的工作,并且提出了两种标准将HIN关系归类为两种,ARs (one centered by another) 和 IRs (peer to peer)。
Contribution 2. 提出了RHINE算法,为两类不同的关系都各自建立了模型,并且可以很容易联合在一起优化。
(3) 算法原理
HIN中的两类关系:
<1> ARs (Affiliation Relations,one-centered-by-another)
这类关系描述一个节点以另外一个节点为中心,一般指隶属关系,如PC关系,paper属于某个会议,这类关系的特征是一类节点度大一类节点度小,即多对一的关系。
<2> IRs (Interaction Relations,peer-to-peer)
这类关系一般指两个节点是对等关系,两个节点之间存在互动关系,如AP关系,作者写了一篇论文,这类关系的特征是两类节点的度差不多,即一对一关系。
HIN中的关系分类(两个度量指标):
<1> 基于度的度量指标
给定节点关系元组(u, r, v),以下公式度量其关系类别。

其中,t_u 表示节点类型,d_tu为平均度,即网络中存在的关系r总数 / 节点类型为t_u 的节点总数。
D(r) 越大表示两类节点的平均度差异越大,即该关系r更可能是ARs,反之D(r) 越小则表示两类节点的平均度差不多,即该关系r更可能是IRs。
<2> 基于网络稀疏度的度量指标
给定节点关系元组(u, r, v),以下公式度量其关系类别。

其中,N_r表示网络中关系r的数目,N_tu为网络中节点类型为t_u 的节点总数。
S(r) 越大表示两类节点间的联系(边)更紧密,即该关系更可能是多对一的ARs,反之S(r) 越小则表示两类节点间的联系(边)没那么紧密,即该关系r更可能是一对一的IRs。
RHINE的基本思想:为两类关系分别建立模型,最后联合优化。
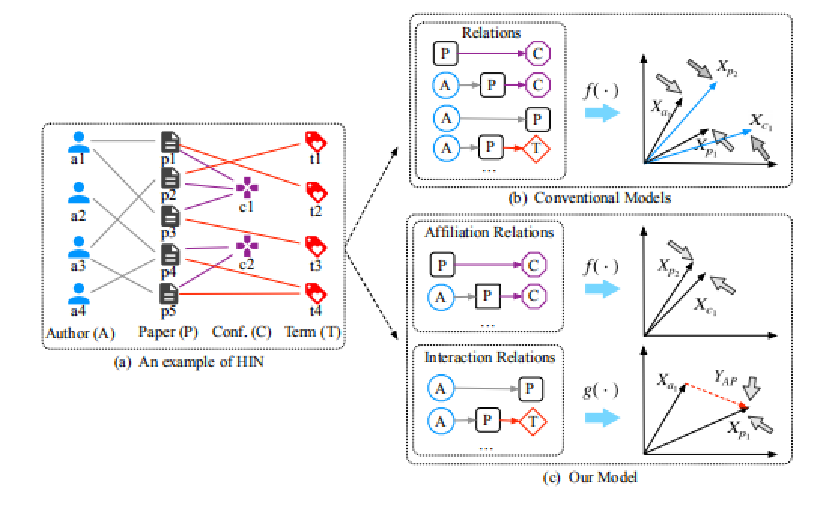
如上图(b)所示,传统HIN算法将一个模型用于捕获网络中的所有关系以此来做网络嵌入。而RHINE不同,如上图(c)所示,RHINE算法分别为两类关系建立模型。
<1> 为ARs关系建立模型:
对于ARs关系s,(p, s, q),最小化p、q在向量空间中的欧式距离,计算如下:

理由: 对于ARs关系,一个节点隶属于另一个节点则它们俩共享相类似的性质,自然应该在表示空间中的距离更加相近,而欧式距离可以直接反映向量空间中两个向量的直线距离。
使用 margin-based loss 作为损失函数,建立模型如下:
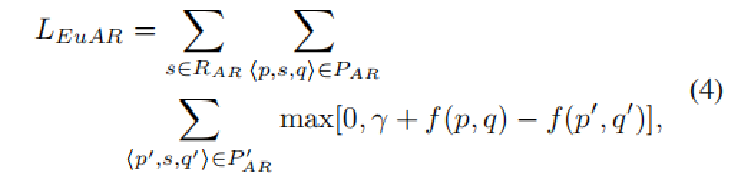
P_AR 是正样本关系三元组集合,P'_AR 是负样本关系三元组集合。
该函数的作用是使得正样本中节点对的向量尽可能相近,使得负样本中节点对的向量尽可能远离。
<2> 为IRs关系建立模型:
对于IRs关系r,(u, r, v),最小化u、v在向量空间中的平移距离(曼哈顿距离),计算如下:

理由: 对于IRs关系,两个节点是对等结构的关系,可能作者认为IRs关系没有ARs关系联系那么强,因此采用曼哈顿距离建模,并且是最小化X_u+Y_r 与 X_v 的差异。
使用 margin-based loss 作为损失函数,建立模型如下:

<3> 最终总的目标函数如下:
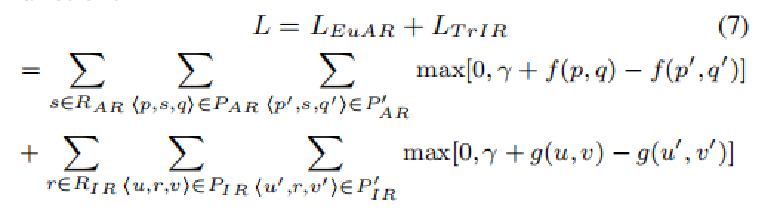
即两个目标函数简单相加在一起,联合优化,正样本为在图中依概率采样关系,负样本为将正样本中的某一端节点替换为随机节点得到。
(4) 实验结果
<1> 数据集:
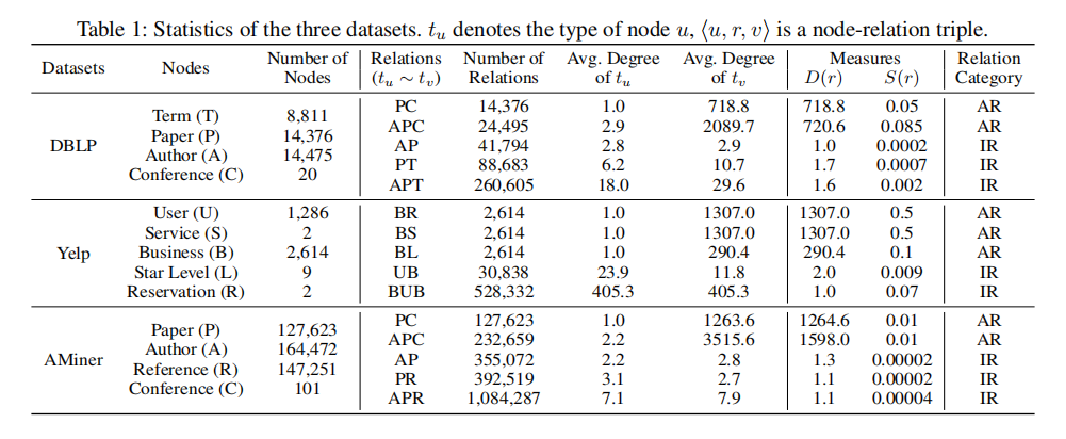
<2> 对比算法:
① DeepWalk
② LINE
③ PTE
④ ESim
⑤ HIN2Vec
⑥ Metapath2vec
<3> 节点聚类任务:
聚类算法: K-means
评测指标: NMI
实验结果:

在所有数据集上都优于对比算法。
<4> 链路预测任务:
评测指标: AUC,F1 score
实验结果:
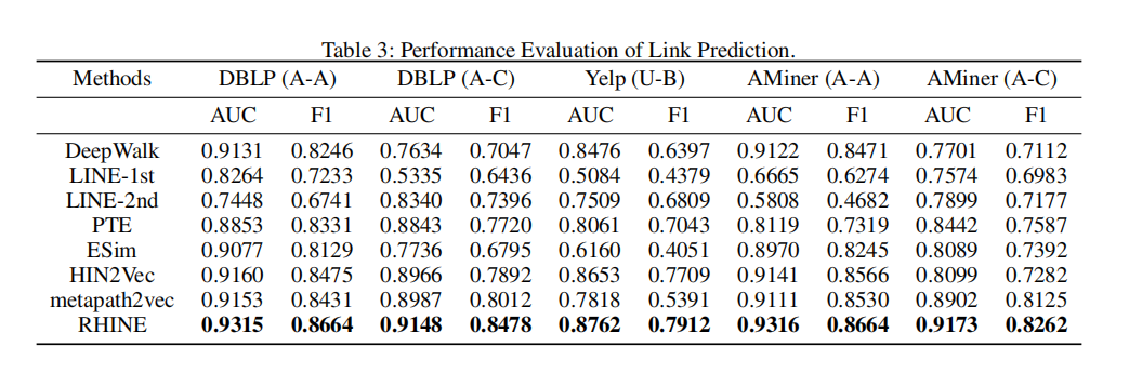
在所有数据集上都优于对比算法。
<5> 节点分类任务:
分类算法: Logistic classifier
评测指标: Micro-F1,Macro-F1
实验结果:

在大部分数据集上都优于对比算法,其中AMiner数据集上性能不如HIN2Vec,原因是对于过度捕获了PR、APR关系,因为作者写了一篇论文可能引用多篇不同领域的文献,因此引入了误差。
<6> 验证模型策略的有效性实验
实验算法:
RHINE_Eu: 只利用欧式距离来做嵌入,不区分关系类型。
RHINE_Tr: 只利用曼哈顿距离来做嵌入,不区分关系类型。
RHINE_RE: ARs关系采用曼哈顿距离,IRs关系采用欧式距离。
RHINE: 即论文所提算法,ARs关系采用欧式距离,IRs关系采用曼哈顿距离。
实验结果:
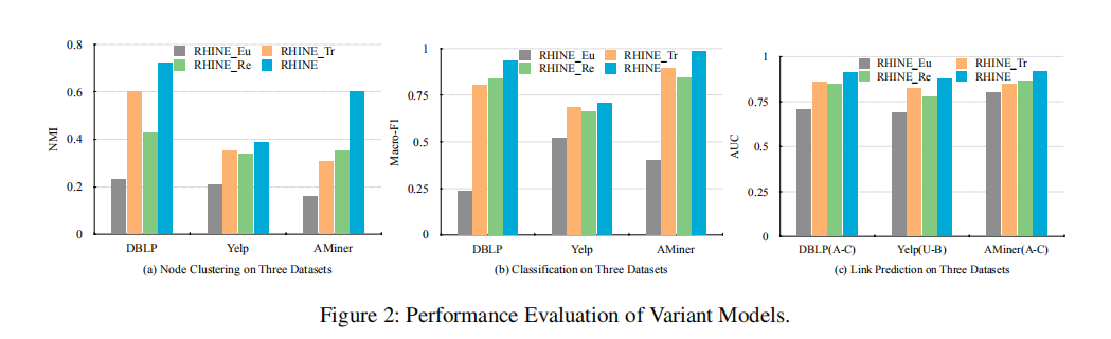
论文所提策略是有效的,图中效果最好的。
<7> 可视化实验(仅对论文节点)
实验结果:

RHINE算法不但能清晰看出四类节点,并且类簇之间的边界也是非常清晰的。
<8> 参数分析
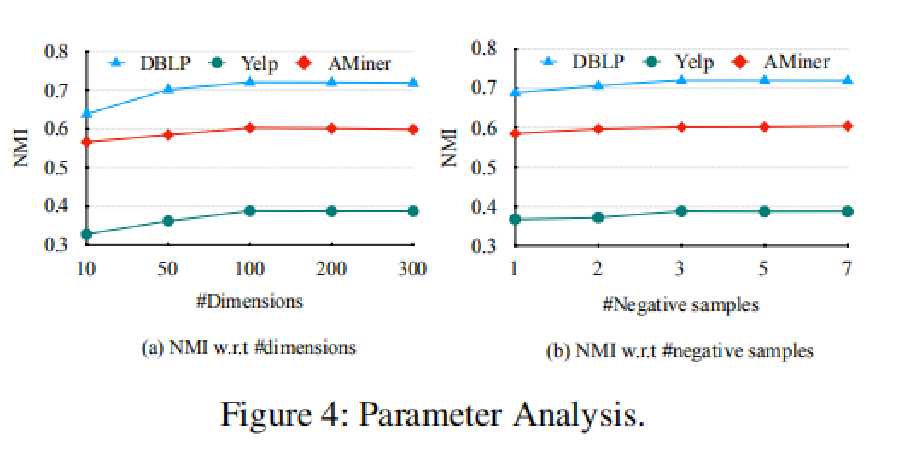
如图(a)所示,表征向量维度在100以后趋于稳定,论文中向量维度选择为100。
如图(b)所示,负样本数在3之后趋于稳定,论文中负样本数选择为3。
(5) 参考文献
1、Relation Structure-Aware Heterogeneous Information Network Embedding. Yuanfu Lu, Chuan Shi, Linmei Hu, Zhiyuan Liu. AAAI 2019.