1. 切换方式
从用户态到内核态切换可以通过三种方式,或者说会导致从用户态切换到内核态的操作:
- 系统调用,这个上面已经讲解过了,在我公众号之前的文章也有讲解过。其实系统调用本身就是中断,但是软件中断,跟硬中断不同。系统调用机制是使用了操作系统为用户特别开放的一个中断来实现,如 Linux 的 int 80h 中断。
- 异常:如果当前进程运行在用户态,如果这个时候发生了异常事件,会触发由当前运行进程切换到处理此异常的内核相关进程中
- 外围设备中断:外围设备完成用户请求的操作之后,会向CPU发出中断信号,这时CPU会转去处理对应的中断处理程序。
2. 代价何在
当发生用户态到内核态的切换时,会发生如下过程(本质上是从“用户程序”切换到“内核程序”)
- 设置处理器至内核态。
- 保存当前寄存器(栈指针、程序计数器、通用寄存器)。
- 将栈指针设置指向内核栈地址。
- 将程序计数器设置为一个事先约定的地址上,该地址上存放的是系统调用处理程序的起始地址。
而之后从内核态返回用户态时,又会进行类似的工作。
3. 如何避免频繁切换
用户态和内核态之间的切换有一定的开销,如果频繁发生切换势必会带来很大的开销,所以要想尽一切办法来减少切换。这也是面试常考的问题。
3.1 减少线程切换
因为线程的切换会导致用户态和内核态之间的切换,所以减少线程切换也会减少用户态和内核态之间的切换。那么如何减少线程切换呢?
- 无锁并发编程。多线程竞争锁时,加锁、释放锁会导致比较多的上下文切换。(为什么加锁和释放锁会导致上下文切换,看文末的补充解释)
- CAS算法。使用CAS避免加锁,避免阻塞线程
- 使用最少的线程。避免创建不需要的线程
- 协程。在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
3.2 一个面试问题
I/O 频繁发生内核态和用户态切换,怎么解决。
首先要同意这个说法,即I/O会导致系统调用,从而导致内核态和用户态之间的切换。因为对I/O设备的操作是发生在内核态。那如何减少因为I/O导致的系统调用呢?答案是:使用户进程缓冲区。下面解释一下原因
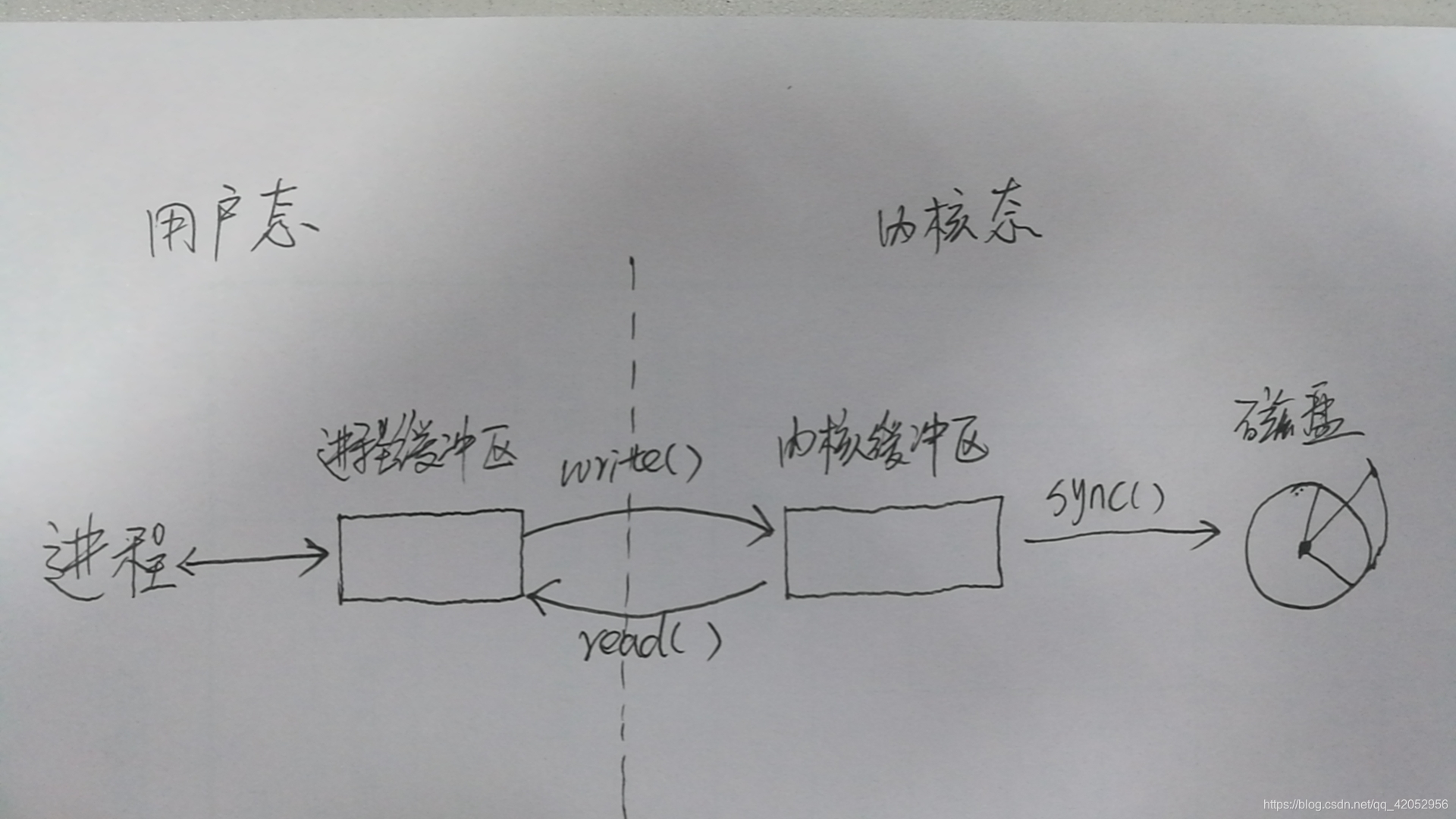
用户进程缓冲区
你看一些程序在读取文件时,会先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。所以说:用户缓冲区的目的就是是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。除了在进程中设计缓冲区,内核也有自己的缓冲区。
内核缓存区
当一个用户进程要从磁盘读取数据时,内核一般不直接读磁盘,而是将内核缓冲区中的数据复制到进程缓冲区中。但若是内核缓冲区中没有数据,内核会把对数据块的请求,加入到请求队列,然后把进程挂起,为其它进程提供服务。等到数据已经读取到内核缓冲区时,把内核缓冲区中的数据读取到用户进程中,才会通知进程,当然不同的IO模型,在调度和使用内核缓冲区的方式上有所不同。
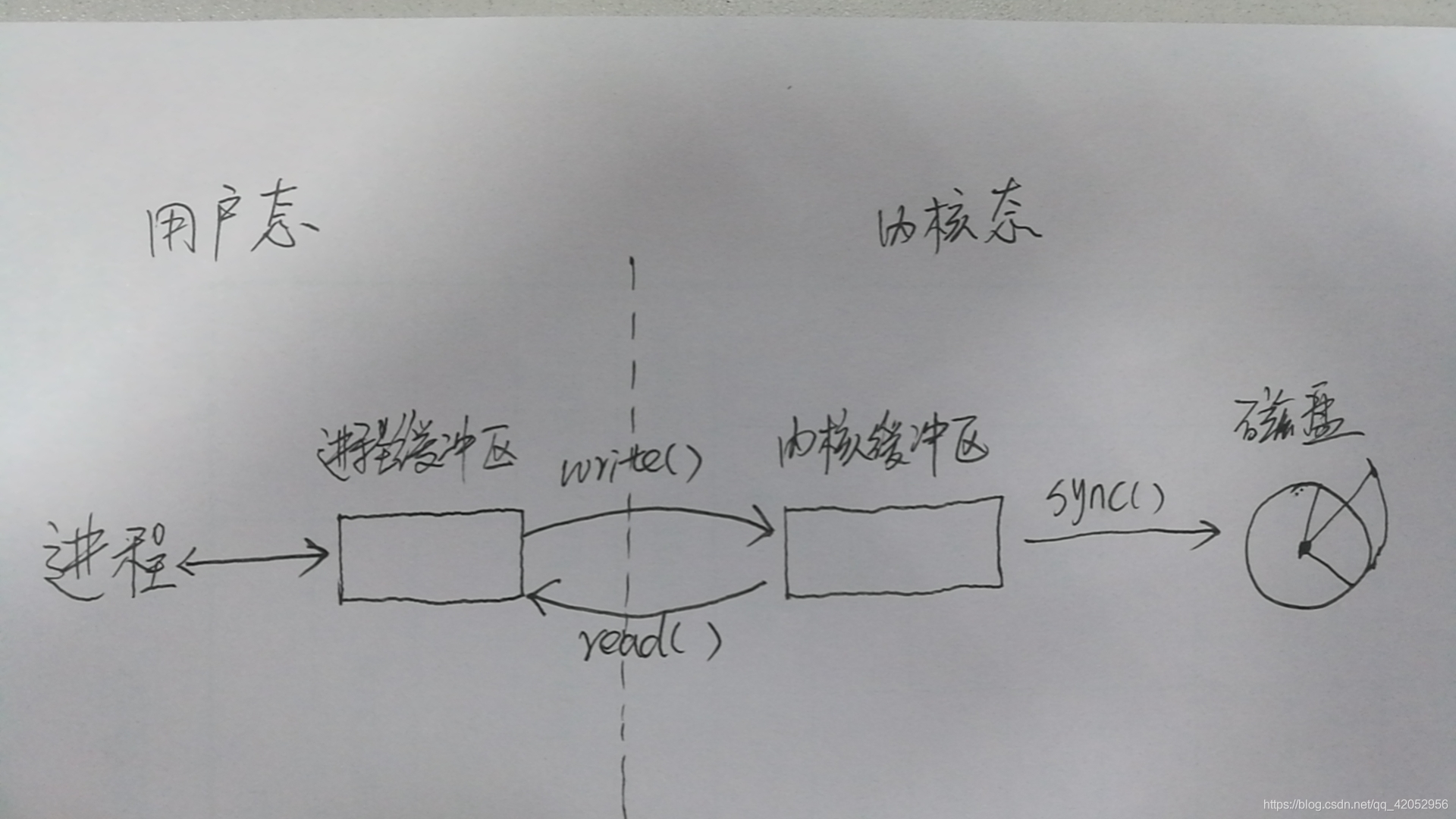
小结
图中的read,write和sync都是系统调用。read是把数据从内核缓冲区复制到进程缓冲区。write是把进程缓冲区复制到内核缓冲区。当然,write并不一定导致内核的缓存同步动作sync,比如OS可能会把内核缓冲区的数据积累到一定量后,再一次性同步到磁盘中。这也就是为什么断电有时会导致数据丢失。所以说内核缓冲区,可以在OS级别,提高磁盘IO效率,优化磁盘写操作。
4. 补充解释
为什么加锁和释放锁会导致上下文切换
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的。但是监视器锁本质又是依赖于底层的操作系统的Mutex Lock来实现的。但是由于使用Mutex Lock需要将当前线程挂起并从用户态切换到内核态来执行,这种切换的代价是非常昂贵的因此,这种依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”。
(上述说法不是很准确,应该不是每种锁都是切换到内核态,这点我不太确认)
mutex和spin lock的区别
mutex和spin lock的区别和应用(sleep-waiting和busy-waiting的区别)2011-10-19 11:43
而自旋锁spin lock是busy-waiting。就是说当没有可用的锁时,就一直忙等待并不停的进行锁请求,直到得到这个锁为止。这个过程中cpu始终处于忙状态,不能做别的任务。
例如在一个双核的机器上有两个线程(线程A和线程B),它们分别运行在Core0 和Core1上。 用spin-lock,coer0上的线程就会始终占用CPU。
另外一个值得注意的细节是spin lock耗费了更多的user time。这就是因为两个线程分别运行在两个核上,大部分时间只有一个线程能拿到锁,所以另一个线程就一直在它运行的core上进行忙等待,CPU占用率一直是100%;而mutex则不同,当对锁的请求失败后上下文切换就会发生,这样就能空出一个核来进行别的运算任务了。(其实这种上下文切换对已经拿着锁的那个线程性能也是有影响的,因为当该线程释放该锁时它需要通知操作系统去唤醒那些被阻塞的线程,这也是额外的开销)
总结
(1)Mutex适合对锁操作非常频繁的场景,并且具有更好的适应性。尽管相比spin lock它会花费更多的开销(主要是上下文切换),但是它能适合实际开发中复杂的应用场景,在保证一定性能的前提下提供更大的灵活度。