一. 数据集
1. 在R语言中,进行数据分析的第一步是创建一个包含待研究数据并且符合要求的数据集。
· 选择装数据的数据结构
· 把数据装入数据结构中
2. 理解数据集
(1)数据集通常是矩形的数据列表,有行和列。
对于数据集中行列两个量,有许多不同的叫法:
· 统计学家:observations & variables
· 数据库分析师:records & fields
· 数据挖掘/机器学习领域:examples & attributes
(2)R拥有广泛的装数据的结构:标量/向量/数据帧/表。
(3)R可以处理的数据类型:数值型/字符型/布尔型(真,假)/复合型/字节型。
二. 数据结构
3. 理解数据结构
(1)不同的数据结构的区别在于:怎么创建(how they're created);
能装什么类型的数据(the kind of data they can hold);
结构的复杂性(structural complexity);
用于识别的符号(the notation used to identify);
访问单个元素(access to individual elements)。
(2)下图02-01是R的各种数据结构:

图02-01 R Data Structures
4. 对象(object):可以分配给变量的任何东西,如常量,函数,数据结构,甚至是图。
对象(object)=模式(mode)+类(class)
·模式(mode):描述一个对象怎么创建;
·类(class):告诉一个类函数怎么处理。
5. 向量(vector)
(1)向量是一维数组,可以装数字型数据(numeric data),字符型数据(character data),逻辑型数据(logical data)。
注意:一个向量有且仅有一种类型的数据(numerical,character,logical)或模式。
(2)联合函数(combine function) c():是用来组织向量的。
例02-01:给向量赋值

(3)标量(scalar)是仅有一个元素的向量(one-element vector),并且c是一个逻辑向量。
例02-02:给向量赋单值

注意:"h<-"这个符号后面可以有空格也可以没有空格去接“-3”这个值。
(4)使用代表位置的数值组成的向量来表示向量的一个或几个元素。
例02-03:取向量中的元素

注意:向量的第一个元素的位置值是1。
6. 矩阵(Matrices)
(1)矩阵是一个二维的阵列,并且每一个元素都是相同的类型(数值,字符或者是逻辑值)。
(2)用matrix函数来创建矩阵。
myymatrix<-matrix(vector,nrow=number_of_rows,ncol=number_of_columns,byrow=logical_value,dimnames=list(char_vector_rownames,char_vector_colnames))
·vector:包含矩阵的元素;
·nrow,ncol:指定矩阵的行列维数;
·dimnames(可选项):行,列名字的特征矩阵;
·byrow(可选项):指示这个矩阵是按行(byrow=TRUE)或按列(byrow=FALSE)填入。
缺省值是FALSE,表示按列填入。
例02-04:创建矩阵

·byrow的值缺省为FALSE,即按列赋值;
·dimnames的值缺省,则无行列标签。
例02-05:创建矩阵

·创建了一个2×2的矩阵,先给矩阵按行赋值,再给矩阵按列赋值。
·矩阵的行名称为:R1,R2;列名称为C1,C2。
例02-06:创建矩阵


·二维矩阵,在确定矩阵的总元素个数后,可以仅仅确定的给出行数或列数。
例02-07:使用矩阵下标

·X[i,]:表示矩阵X第i行的元素;
·X[,j]:表示矩阵X第j列的元素;
·X[i,j]:表示矩阵X第i行第j列的元素。
·下标i,j可以是表示行/列的数值或数值向量。
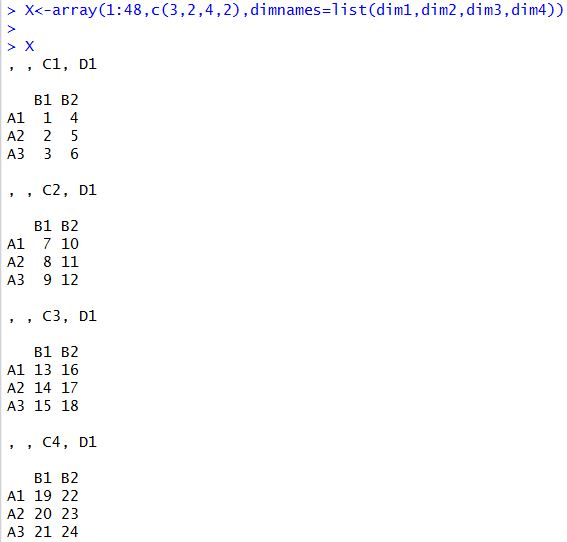
7. 数组(Arrays)
(1)数组与矩阵类似,但是可以有二维或多维。
(2)用array这个函数来创建数组。
myarray<-array(vector,dimensions,dimnames)
·vector:包含数组的所有元素;
·dimensions:是一个数值向量,给定每一维的最大下标,即每一位能包含的最多元素个数;
·dimnames(可选项):每一维的名字的列表。
注意:
1)在大于二维时,dimnames的第一二个变量表示行列的名称。
2)array函数中,没有byrow这个变量,即在一个数组的分量矩阵中,不存在是按行还是按列赋值。

图02-02
3)数组中的每一个元素都是相同的类型。
4)从下面的例子来看,在array函数的分量矩阵中,是按列赋值的。
例02-08:创建数组

例02-09:创建数组

8. 数据帧(Data frames)
(1)每一列有且仅有一种类型的数据,不同的列可以是不同类型的数据。
(2)使用data.frame函数创建数据帧:
mydata<-data.frame(col1,col2,col3,...)
·col1,col2,col3,...可以是任何类型的列向量。
(3)names函数:表示每一列的名字。
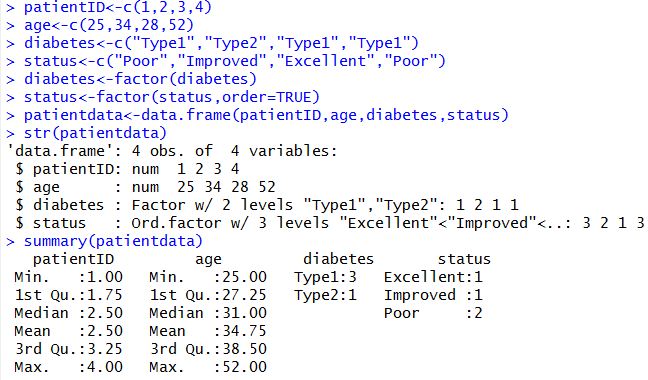
例02-10:创建数据帧


例02-11:指定数据帧中的元素

·$:数据帧$变量,如:patientdata$age:指代在数据帧patientdata中的变量age指代的所有元素。

· 以数据帧patientdata中的diabetes的内容作为行名称,status的内容作为列名称,创建一个二维矩阵;
以各类型元素在各种状态下的个数作为该矩阵的值。
(4)attach()函数:添加数据帧到R语言的某个搜索路径;当遇到一个变量时,则检查这个搜索路径中的数据帧,以便能定位这个变量。
detach()函数:把一个数据帧从搜索路径中移除。
注意:detach()函数对于数据帧本身而言,什么都没有做;并且是可选的,但是对于好的编程风格是有必要加上的。
例02-12:attach()函数与detach()函数



等价于:



注意:attach()和detach()函数最好是适用于分析一个数据帧,并且同一个名字仅有对象。
(5)with()函数:避免对象被掩盖的警告。
例02-13:with()函数的使用

·{ }里面声明的内容如:summary(mpg,disp,wt),plot(mpg,disp),plot(mpg,wt),都认为使用了mtcars这种数据帧。
·如果只有一个声明(statement),则{ }可用可不用。
A)with()函数的赋值仅仅在函数内部有效:

B)想要创建在with()函数外面仍然有效的变量,使用赋值符号"<<-",而非赋值符号"<-"。

(6)case identifiers
仍以前面的例子patientdata为例子,patientID用于在数据集中标识每个个体。
在R语言中case identifiers可以由数据帧函数中的一个rowname的可选项标识。
例02-14:case identifiers

9. 因子(Factors)
(1)变量的类型
·名义变量(nominal variables):绝对的,没有隐含次序的(categorical,without an implied order);
·次序变量(ordinal variables):有隐含次序,但数值不隐藏(implied order,but not amount);
·连续变量(continuous variables):次序和数值都隐藏(both order and amount are implied)。
·因子(factors):名义变量+次序变量。{nominal(categorical) &ordinal(ordered) variables}
·因子在R语言中非常重要,因为其决定数据被如何分析,怎样呈现。
(2)factor()函数:把名义变量对应的绝对数值存储在一个内部向量中。
例02-15:使用factor()函数

·缺省order这个量,则status中的元素的等级按照字母顺序而递增排列;
·存在order这个量,.............................................................;
·要使status中元素等级不按照字母顺序排列,则令order=TRUE,并用可选项levels()函数,实例化期待的排列顺序。
例02-16:使用factor()函数
10. 表(Lists)
(1)表是R语言中,最复杂的数据结构。
· 最基本的,表是objects的有序结合。
· 一个表允许你在一个名字下聚集一系列的(不相关的)objects。
(2)List是R语言中很重要的数据类型,有以下两个原因:
·用简单的方法处理完全相异的信息;
·使得R的很多函数都可以返回list类型的数据。
(3)使用list()函数来创建一个list:
mylist<-list(object1,object2,...)
或 mylist<-list(name1=object1,name2=object2,...)
·object 可以是任意的结构类型
例02-17:创建一个表

·该例子中,一个list有4种成分:一个字符串,一个数值型向量,一个矩阵,以及一个字符型向量。
总结:
· 变量的值不是被声明的,而是来自于第一次被赋值;
· R语言中没有标量值,通常用一个元素的向量来表示标量;
· A$x:表示数据帧A中的变量x;
· R语言中没有多行注释或者是块注释,只能在每行的开头用#符号表示该行为注释;
· 在测试时,可以用if(FALSE){...}使得一段某段代码不被执行;用if(TRUE){...}使得一段代码被执行。
· 给一个向量,数组,矩阵或表中不存在的元素赋值,将会扩大其结构,以容纳新的值。
例02-18:给向量赋其本来不存在的值,使其扩展

例02-19:使扩展后的向量收缩

· R语言从1开始计数,而非0.
例02-20:

·本小结:
介绍两个主要概念:对象(object)和因子(factor);
介绍五种数据类型:向量(vector),数组(array),矩阵(matrix),数据集(data.frame),表(list);
在数据集中,顺便引进了三个函数 attach()和detach(),以及with()函数;
在引入因子(factor)的变量时,定义了三个概念:名义变量(nominal variables),次序变量(ordinal variables),连续变量(continuous variables)。
向量,数组,矩阵中的每一个对象都必须是相同的类型的数据;
数据集的每一列的对象必须是相同的类型的数据,不同列可以是不同类型的数据;
表的每一个对象都可以是不同类型的数据。