三. 导入数据
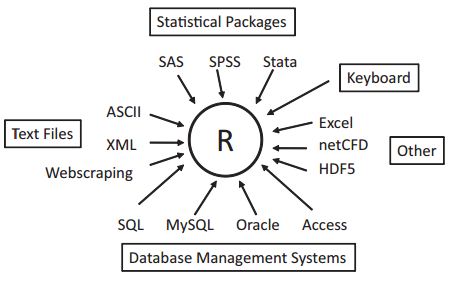
图02-03:Source of data that can be imported into a dataset
11. 从键盘导入数据
(1)可能是最简单的数据导入方式。
(2)使用edit()函数,R将会打开一个文本编辑器,然后再手动的输入数据。具体步骤如下:
· 创建一个新的数据帧(data.frame),并填入变量名和类型(variable names&modes);
· 调用文本编辑器,键入数据,并保存结果到数据对象上(data object).
例02-21:从键盘导入数据


· gender=character(0):创建一个变量gender,并指定其类型为character,但并没有实际赋值;
·编辑后,其值直接赋给对象自身(object itself),此处为mydata;
·调用edit函数后,有一个数据编辑器的窗口打开,我们可以向里面键入需要的数据,即相当于数据的导入;
完成数据的输入后,直接关闭该数据编辑器的窗口,数据已经保存了;
然后再在RStudio中调用edit()函数,又调出该数据编辑器窗口,此时,前面输入的数据都存在,点击第一行的变量,可以改变其变量名和变量类型。
问题:不明白什么是因子水准,为什么会这样?

12. 从分隔符号文档(limited text file)中导入数据
使用read.table()函数:以表格形式(table format)读取一个文件,并保存为数据帧(data.frame)格式。
mydataframe<-read.table(file,header=logical_value,sep="delimiter",row.names="name")
·file:必须是ASCII格式的;
·header:只能是逻辑值,即TRUE或FALSE,意味着第一行是否包含一个变量名;
·sep:指定划分数据的值(delimiter separating data value);
·row.names(可选项):指定一个或多个变量来表示行标识符。
注意:
(1)要导入的文件应该先存在与用户的计算机上。
(2)R语言提供了很多机制通过关联得到数据。例如:
·函数file(),gzfile(),bzfile(),xzfile(),unz(),url()可以用来代替文件名;
·file():通过文件夹,剪切板,C级标准输入(C-level standard input)获得文件;
·gzfile(),bzfile(),xzfile(),unz():让用户读压缩文件;
·url():得到互联网文件(internet files),通过包含http://或ftp://或file://的完全URL路径;
可以指定HTTP或HTP代理服务器;
通常,完全URL路径(包含“”)能直接代替文件名。
问题:怎么导入一个文件呢?比如.csv格式,.txt格式,.xls格式?? 这一部分并没有在RStudio中运行出有效代码,感觉比较空;主要问题是不能正确的导入文件。
13. 从Excel表格中导入数据
(1)Windows系统下,使用RODBC包来导入Excel文件
·导入RODBC包:install.packages("RODBC")
·导入数据:library(RODBC)
channel<-odbcConnectExcel("myfile.xls")
mydataframe<-sqlFetch(channel,"mysheet")
odbcClose(channel)
·myfile.xls:是一个Excel文件;
·mysheet:是该Excel文件的名字;
(2)Excel2007是一个XLSX格式的文件,其本质是XML的压缩文件,故应先安装xlsx包:library(xlsx) ;
read.xlsx():把工作表(worksheet)从Excel文件中导入,变成一个数据帧(data.frame);
read.xlsx(file,n):file表示要导入的Excel2007工作表的路径,n表示要导入的工作表的数量。
14. 从XML导入数据
http://www.omegahat.org/RSXML/MemoryManagement.html
15.从webscraping导入数据
webscaping:用户直接从网页提取信息,并且保存为R数据结构,以便进一步分析;
readLines():下载网页;
grep(),gsub():操作网页.
16.从SPSS导入数据
(1)read.spss()函数:在包foreign中;
(2)spss.get()函数:在包Hmisc中,是一个包装函数(wrapper function),为read.spss()设置值。
安装包: install.packages("Hmisc")
导入数据:library(Hmisc)
mydataframe<-spss.get("mydata.sav",use.value.lables=TRUE)
· mydata.sav:是待导入的spss数据文件;
· use.value.lables=TRUE:把有标签值的变量(variables with value lables)转换为具有相同标签值的R因子(factor),并把结果放在mydataframe中。
17.从SAS导入数据
read.ssd()函数:在包foreign中;
sas.get() 函数:在包Hmisc中。
18.从Stata中导入数据
在R中,可以直接从Stata中导入数据;其需要的代码如下:
library(foreign)
mydataframe<-read.dta("mydata.dta")
·mydata.dta是Stata数据集,mnydataframe是R的数据帧(data frame).
19.从netCDF中导入数据
(1)Unidata's netCDF(network Common Data Form)开源软件包含ma-chine-independent 数据格式,用于创建,分布数组导向的科学数据;
(2)ncdf包和ncdf4包提供了高级接口,能连接到netCDF的数据文件;但是ncdf包适用于windows系统,而ncdf4包不适用于windows系统;
(3)library(ncdf)
nc<-nc_open("mynetCDFfile")
myarray<-get.var.ncdf(nc,myvar)
·netCDF文件夹中的文件mynetCDFfile的变量myvar变量包含了所有的数据,导入R中并保存为myarray .
20. 从HDF5导入数据
(1)HDF5(Hierarchical Data Format)是适用于管理超大数据集的软件技术。
(2)hdf5包:用于把R对象(R object)写入一个文件,该文件能被理解HDF5格式的软件读入。
(3)在R中,对HDF5的支持仍然很有限。
21. 获得DBMSs(database management systems)
(1)R与许多DBMSs都有接口,如Micorsoft SQL Server,Microsoft Access,MySQL,Oracle...有些包获得路径通过本地本地数据驱动,另一些则是通过ODBC或JDBC。
(2)ODBC接口
(3)DBI-RELATED包
22.通过Stat/Transfer导入数据
Stat/Transfer是一个独立操作的应用,可以在34种数据格式中,进行数据转换,包括R这种数据。
四. 对数据集进行注释
23.变量标签(variable labels)
(1)R处理变量标记的能力是有限的;
(2)一种方式是用变量标签作为变量的名字,然后通过其位置索引值来指代变量;
如:names(patientdata)[2]<-"Age at hospitalization(in years)"
·对变量age重命名,但是Age at hospitalization(in years)这个名字太长了,使用起来不方便;故可用patientdata[2]来指代。
24.值标签(value lables)
factor()函数能用来为绝对变量(categorical variables)创建一个值标签。
如:patientdata$gender<-factor(patientdata$gender,levels=c(1,2),levels=c("male","female"))
小结:数据格式了解了一大堆,但是没有实际的数据可以让我来导入,就没能实际操作,就当了解一下概念吧,但是这样的学习很浅;
后面学了后,还需要返回来再看一下,最好能找到相关的数据集,实际操作一下。