一、前提介绍
1.1 操作系统发展史
点击这里查看详细信息:操作系统发展史
1.2 多道技术
空间上的复用:多个程序共用一套设备,是多道技术实现时间上的复用的基础
时间上的复用:单个CPU的电脑上,起多个应用程序,CPU通过快速切换,给人的感觉是同时运行的
CPU切换的情况:
1.一个任务占用时间过长或被操作系统强行剥夺走CPU的执行权限(比起串行效率反而降低)
2.一个任务执行过程中遇到io操作,也会被操作系统强行剥夺走CPU的执行权限(比起串行效率提高)
并发:看上去像是同时进行的,但是实际上是CPU快速切换实现的
并行:同时运行二、进程
2.1 进程介绍
程序:一堆代码
进程:正在运行的程序
进程是一个实体,每一个进程都有它自己独立的内存空间2.2 进程调度
1.先来先服务(FCFS):对短作业不利
2.短作业优先服务(SJ/PF):对长作业不利
3.时间片轮转
4.多级反馈队列2.3 进程状态转换
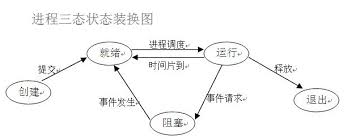
2.4 同步与异步,阻塞与非阻塞
同步和异步:针对任务的提交方式
同步:提交任务之后原地等待任务的返回结果,期间不做任何事!
异步:提交任务之后,不等待任务的返回结果,直接向下运行代码!
阻塞和非阻塞:针对程序运行的状态
阻塞:遇到io操作 --> 阻塞态
非阻塞:就绪或者运行态 --> 就绪态、运行态2.5 创建进程的两种方式
# -----------调用函数-----------------------
from multiprocessing import Process
import time
def task(name): # 这个是要创建的进程
print('%s is running' % name)
time.sleep(3)
print('%s is over' % name)
# 注意:在windows系统中,创建进程会将代码以模块的方式从头到尾加载一遍
# 一定要写在if __name__ == '__main__': 代码块里面
# 强调:函数名一旦加括号,执行优先级最高,立刻执行
if __name__ == '__main__':
p1 = Process(target=task, args=('zhangsan', )) # 实例化了一个Process对象
p1.start()
print("this is main processing!")
# -------------实例化对象-------------------------
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name):
super().__init__()
self.name = name
# 必须写run方法(规定好的)
def run(self):
print('%s is running' % self.name)
time.sleep(2)
print('%s is end' % self.name)
if __name__ == '__main__':
obj = MyProcess('egon')
obj.start()
print("this is main processing")2.6 join方法
from multiprocessing import Process
import time
def task(name,n):
print('%s is running' % name)
time.sleep(2)
print('%s is over' % name)
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(3):
p = Process(target=task, args=('子进程%s' % i, i))
p.start()
p_list.append(p)
for i in p_list:
i.join()
print('this is main processing ', time.time()-start_time)
# join的作用仅仅只是让主进程等待子进程的结束,不会影响子进程的运行
# 下方为程序的运行结果,(结果不是固定的,但是每三行的顺序是固定的,肯定是先running再over)
"""
打印结果:
子进程2 is running
子进程0 is running
子进程1 is running
子进程2 is over
子进程0 is over
子进程1 is over
this is main processing 3.1227028369903564
"""2.7 进程间的数据隔离与通信
# --------------进程间的数据隔离---------------------------
# 要验证进程间的内存隔离,只需要在父进程中调用子进程
# 看子进程是否改变父进程的变量就行了
from multiprocessing import Process
x = 100
def task():
global x
x = 1
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print('this is main processing', x)
# 打印结果:this is main processing 100
# --------进程间的通信-------------------------------------
from multiprocessing import Queue, Process
# 基于队列实现进程间的通信
def producer(q):
q.put('this is producer!')
def consumer(q):
print(q.get())
if __name__ == '__main__':
q = Queue() # 实例化队列对象
p1 = Process(target=producer, args=(q,))
c1 = Process(target=consumer, args=(q,))
p1.start()
c1.start()
2.8 进程对象的其他相关方法
from multiprocessing import Process, current_process
import time
import os
def task():
print('%s is running' % os.getpid()) # 获取这个进程的id
time.sleep(3)
print('%s is over' % os.getppid()) # 获取父进程的进程id
if __name__ == '__main__':
p1 = Process(target=task)
p1.start() # 运行子进程
p1.terminate() # 杀死子进程
print(p1.is_alive()) # 判断进程是否存活
print('this is main processing')
"""
程序运行结果:
为什么在杀死子进程之后,任然显示子进程存活?
是因为,将杀死子进程的命令发送给操作系统之后,在操作系统还没杀死进程之前,
已经执行了进程是否存活这个命令,此时,系统还没杀死进程,那么肯定返回True,
在此处,只需要在杀死进程的下一行,让程序睡(暂停)一会儿,哪怕0.1秒,
都是可以正常显示False
True
this is main processing
"""2.9 僵尸进程与孤儿继承
僵尸进程:
子进程结束之后,不会立即释放pid等资源信息。
主进程释放子进程资源的两种情况:
主进程正常死亡
join方法
任何进程都会步入僵尸进程,当主进程不停的创建子进程的时候,会有害
孤儿进程:主进程意外死亡,在Linux中有一个init帮助回收孤儿进程资源2.10 守护进程
from multiprocessing import Process
import time
def task(name):
print('%s 活着' % name)
time.sleep(3)
print("%s 正常死亡" % name)
if __name__ == '__main__':
p = Process(target=task, args=('李四总管',))
p.daemon = True # 必须在p.start开启进程命令之前声明
p.start()
print('somebody is going to die!')
2.11 互斥锁
from multiprocessing import Process, Lock
import json
import time
import random
def search(i):
with open('info', 'r', encoding='utf-8') as f:
data = json.load(f)
print(('用户查询余票数:%s' % data.get('ticket')))
def buy(i):
# 买票之前还得先查有没有票
with open('info', 'r', encoding='utf-8') as f:
data = json.load(f)
time.sleep(random.randint(1, 3)) # 模拟网络延迟
if data.get('ticket') > 0:
data['ticket'] -= 1 # 买票
with open('info', 'w', encoding='utf-8') as f:
json.dump(data, f)
print('用户%s抢票成功' % i)
else:
print('用户%s查询余票为0' % i)
def run(i, mutex):
search(i)
mutex.acquire() # 抢锁 一把锁不能同时被多个人使用,没有抢到的人,就一直等下去
buy(i)
mutex.release() # 释放锁
if __name__ == '__main__':
mutex = Lock()
for i in range(10):
p = Process(target=run, args=(i, mutex))
p.start()