一、hadoop 2.x产生背景
1、hadoop 1.x中hdfs和mr在高可用和扩展性等方面存在问题。
2、hdfs存在的问题:NN单点故障,难以应用于在线场景;NN压力过大,内存受限,影响系统扩展性。
3、mr存在的问题:1.x难以支持除mr之外的计算框架,如spark和storm(mr一般得到结果时间较长,storm和spark可以很快得到结果).
二、hadoop 1.x与hadoop2.x区别
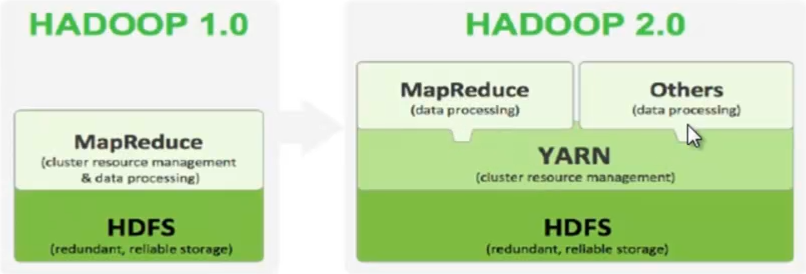
1、2.x由hdfs、mr和yarn三个分支构成,yarn是分布式的资源管理器(资源包括内存,cpu等),比如mr框架要运行一些计算任务(Map任务和Reduce任务)的时,这些任务都要在各个节点上执行,执行的时候首先要去yarn申请,然后yarn分配到哪个节点上去执行,可以充分的利用资源;yarn同时还有类似接口的作用,可以接入其它的计算框架。
2、2.x解决单点故障:hdfs HA,通过主备NN解决,如果主发生故障,则切换到备上。
3、2.x解决内存受限:hdfs Federation,水平扩展,支持多个NN,每个NN分管一部分目录,所有NN共享DN.
4、2.x相对于1.x仅是架构上发生了变化,使用方式不变,对hdfs使用者透明,hdfs 1.x中的命令和api任然可以使用。
三、hadoop2.x HA
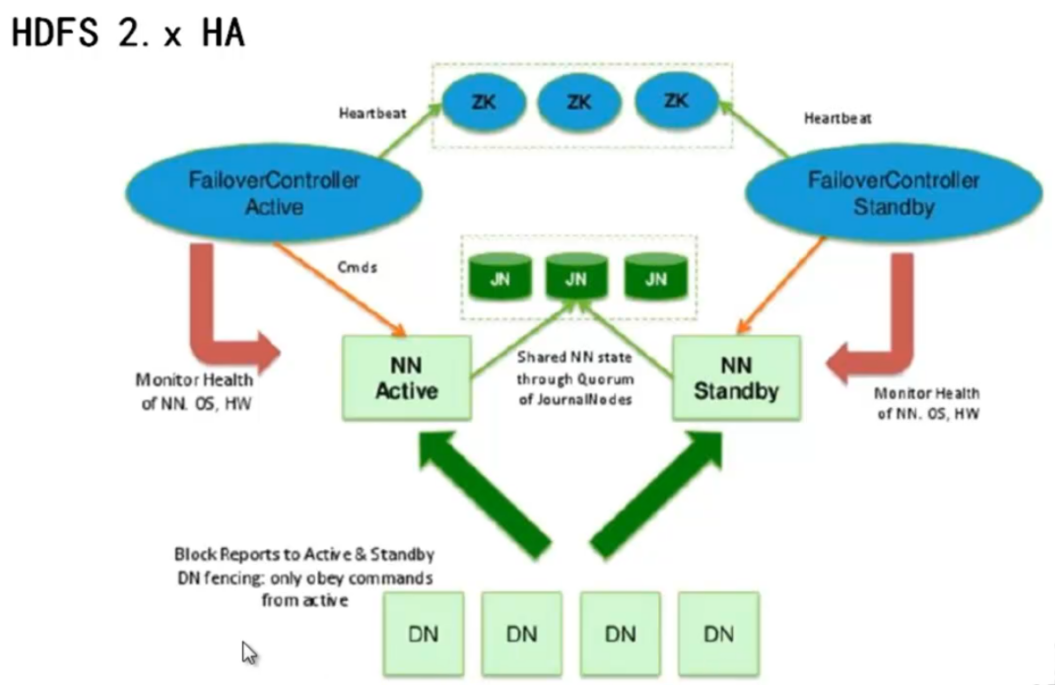
1、DN向所有的NN汇报,备同步主的元数据
2、NN可以有一主多备,主挂了备要接管,这里要保证主和备中元数据一致,那么这些元数据就不能存储在主或备中了,要存在另外一个叫JN的集群中,JN要多个,否则又成为新的单点。JN的目的就是存储元数据。所有的NN不管主还是备,只要读写就要到JN上进行读写。
3、hdfs高可用的解决方法是zk,不是keepalived,zk比较火,其实就是做高可用的,因为他对用户提供了二次开发接口,任何服务的高可用都可以用zk做。Keepalived 高可用的原理是ip地址漂移,对客户端来说就是一个ip地址,客户端访问这个ip就可,但是zk不是,主备都有各自的ip地址,那客户端无法确定,所以就去访问ZK。也就是说Hdfs读写流程中客户端首先访问zk,zk告诉客户端哪个NN是active的,然后客户端再去访问该NN。
4、zk通过FailoverControllerActive 对NN进行心跳检查,监控NN健康状况,控制NN的切换。任何NN都对应一个FailoverControllerActive,主挂掉以后 FailoverControllerActive去ZK上竞争锁,拿到锁的NN变为active,ZK必须是奇数个,ZK内部是个投票机制,也就是竞争锁的算法。
5、另外ZK可以通过FailoverControllerActive手动切换工作NN,比如现在相对主NN进行升级,想先停掉,升级后在切换。
四、hadoop2.x Federation
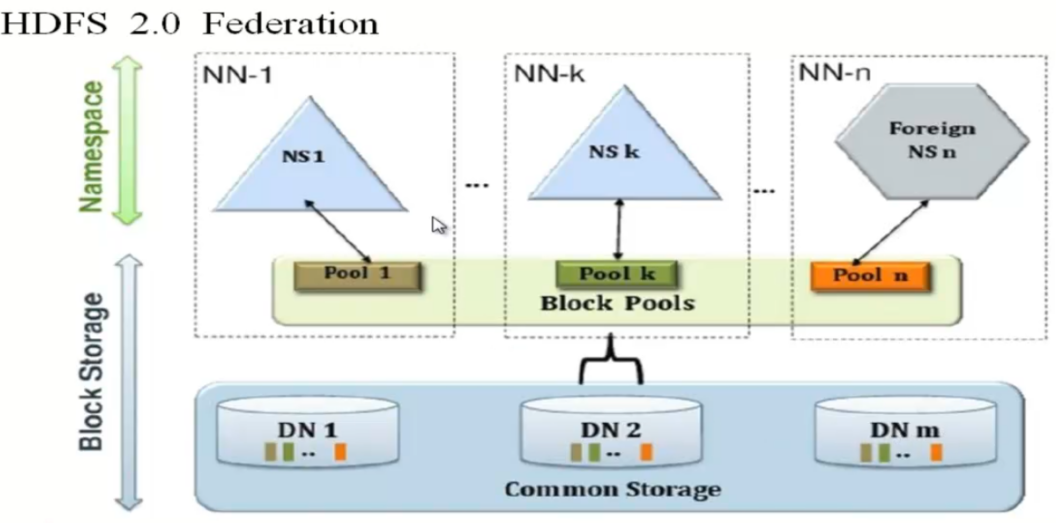
1、Federation中DN为所有的NN服务,是共享的(如果搭建三个独立的集群,那么DN是独立的)。这里工作时NN是各自独立的,假如NN1挂掉了不影响NN2.客户端访问必须指明要访问哪个NN,如果要与HA结合的话,要分别为每个NN搭建HA。
2、Federation通过多个NN(水平扩展)把元数据的存储和管理分散到多个节点中,可以通过多个NN来隔离不同类型的应用。只有超大企业才用到,HA更重要些,内存受限的问题可以通过加大内存来处理。
五、YARN
1、yarn核心思想将1.x中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现.
2、yarn的引入使得多个计算框架可以运行在一个集群中(实现了计算框架的接口化).
3、mr运行在yarn上:将MapReduce作业直接运行在yarn上,而不是由JobTracker和TaskTracker构建的mr系统中,yarn负责资源管理和调度,ApplicationMaster负责任务调度、任务监控和容错等。MapTask和ReduceTask任务驱动引擎,与mr1一致。每个MapReduce作业对应一个ApplicationMaster,yarn将资源分配给ApplicationMaster,ApplicationMaster进一步将资源分配给内部的任务。
yarn架构及原理:http://www.cnblogs.com/codeOfLife/p/5492740.html
六、linux上hadoop2.5.2 HA安装部署
按照理论部分,需要搭建如下节点:
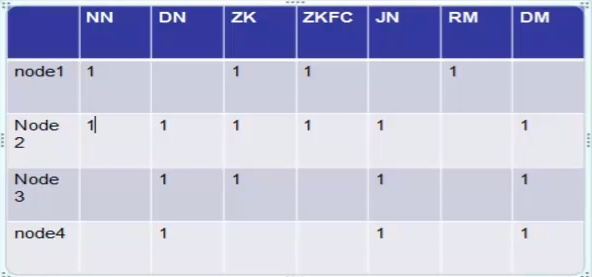
1、准备4台Linux机器,node1配置hosts,之后scp到node2,node3,node4:
[root@node1 ~]# vim /etc/hosts 192.168.13.129 node1 192.168.13.130 node2 192.168.13.131 node3 192.168.13.132 node4
2、各节点安装jdk并且配置环境变量:
[root@node1 ~]# vim /etc/profile //增加以下内容: ---- JAVA_HOME=/usr/local/jdk1.7.0_03/ PATH=$PATH:$JAVA_HOME/bin export PATH JAVA_HOME ---- [root@node1 ~]# source /etc/profile [root@node1 ~]# jps 1432 Jps
3、node1免密码登录node2、node3和node4配置
-------------各节点先安装openssh [root@node1 ~]#yum -y install openssh-clients -------------各节点生成公私钥,放入本地认证,完成各自本地登录 [root@node1 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa [root@node1 ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys [root@node1 ~]# ssh node1 //登录本地成功 Last login: Thu Aug 25 20:03:18 2016 from 192.168.13.1 [root@node1 ~]# --------------复制node1公钥到其它节点 [root@node1 ~]# scp ~/.ssh/id_dsa.pub root@node2:~ [root@node1 ~]# scp ~/.ssh/id_dsa.pub root@node3:~ [root@node1 ~]# scp ~/.ssh/id_dsa.pub root@node4:~ --------------node1公钥加入各节点认证 [root@node2 ~]# cat ~/id_dsa.pub >> ~/.ssh/authorized_keys [root@node3 ~]# cat ~/id_dsa.pub >> ~/.ssh/authorized_keys [root@node4 ~]# cat ~/id_dsa.pub >> ~/.ssh/authorized_keys [root@node1 ~]# ssh node2 //直接登录node2成功 Last login: Thu Aug 25 20:08:04 2016 from 192.168.13.1 [root@node1 ~]# ssh node3 //直接登录node3成功 Last login: Thu Aug 25 20:08:08 2016 from 192.168.13.1 [root@node1 ~]# ssh node4 //直接登录node4成功 Last login: Thu Aug 25 20:08:10 2016 from 192.168.13.1
4、各节点安装hadoop-2.7.3和zookeeper-3.4.8
[root@node1 ~]# tar zxvf hadoop-2.7.3.tar.gz [root@node1 ~]# ln -sf /root/hadoop-2.7.3 /home/hadoop [root@node1 ~]# tar zxvf zookeeper-3.4.8.tar.gz [root@node1 ~]# ln -sf /root/zookeeper-3.4.8 /home/zookeeper
5、在node1上根据官方文档配置hdfs-site.xml,其它一些默认配置参考官方hdfs-default.xml
<configuration> <!--指定hdfs的nameservice为ns,zk需要这个标示(因为zk可以同时做不同应用的高可用) --> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!-- ns下面有两个NN,分别是NN1,NN2 --> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!-- NN1,NN2的RPC通信地址(hadoop各个节点之间以及客户端和NN传递数据都使用rpc协议) --> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>node2:8020</value> </property> <!-- NN1,NN2的http通信地址(http协议是看管理界面用的) --> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>node1:50070</value> </property> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>node2:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node2:8485;node3:8485;node4:8485/ns</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/workspace/journal</value> </property> <!-- 开启NameNode故障时自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property> </configuration>
6、在node1上根据官方文档配置core-site.xml,其它一些默认配置参考官方core-default.xml
<configuration> <!-- 指定hdfs的nameservice为ns(hdfs入口) --> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <!--指定hadoop数据临时存放目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/workspace/hdfs/temp</value> </property> <!--指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> </configuration>
7、在node1上配置DN,无需配置SNN了,因为JN已经取代了SNN.
[root@node1 hadoop]# vim slaves
node2
node3
node4
至此完成hadoop配置,将node1 conf目录下所有配置复制到其它节点。
8、zookeeper配置并启动
[root@node1 ~]# cp /home/zookeeper/conf/zoo_sample.cfg /home/zookeeper/conf/zoo.cfg [root@node1 conf]# vim zoo.cfg dataDir=/home/zookeeper/data server.1=node1:2888:3888 //1 2 3 是zk集群的编号 server.2=node2:2888:3888 server.3=node3:2888:3888
-----scp到其它节点-------
-----配置各节点myid,和zoo.cfg中集群编号一致----
[root@node1 ~]# vim /home/zookeeper/data/myid
1
[root@node2 ~]# vim /home/zookeeper/data/myid
2
[root@node3 ~]# vim /home/zookeeper/data/myid
3
-----启动各节点zk---------
[root@node1 ~]# /home/zookeeper/bin/zkServer.sh start
[root@node2 ~]# /home/zookeeper/bin/zkServer.sh start
[root@node3 ~]# /home/zookeeper/bin/zkServer.sh start
[root@node1 ~]# jps
1866 QuorumPeerMain //zk进程名
1884 Jps
9、node2、node3和node4下启动JN,然后启动node1 NN,并执行格式化,然后再node1 NN元数据拷贝到node2.
[root@node2 sbin]# ./hadoop-daemon.sh start journalnode starting journalnode, logging to /root/hadoop-2.7.1/logs/hadoop-root-journalnode-node2.out [root@node2 sbin]# jps 1957 JournalNode 2006 Jps 1866 QuorumPeerMain
[root@node1 bin]# ./hdfs namenode -format //格式化
[root@node1 sbin]# /home/hadoop/sbin/hadoop-daemon.sh start namenode //启动NN,不然拷贝不成功
[root@node2 bin]# ./hdfs namenode -bootstrapStandby //元数据拷贝到node2,在hadoop临时目录中可以看到fsimage
10、关掉所有hadoop进程,从新启动hdfs.