Prediction-Tracking-Segmentation
2019-04-09 18:47:30
Paper:https://arxiv.org/pdf/1904.03280.pdf
之所以要讲这篇文章,是因为,我很喜欢这个文章的思路,即:基于 prediction 的跟踪。废话不多说,来看文章的核心思想:Prediction-Tracking-Segmentation。文章的提到,现有的跟踪和分割的方法都是基于 appearance 的,而很少有考虑 motion information;特别是基于 tracking-by-detection 的 framework,严重依赖于 Local search region;从而导致对某些挑战性的因素,特别敏感。这些因素有:occlusion,fast motion and camera motion。
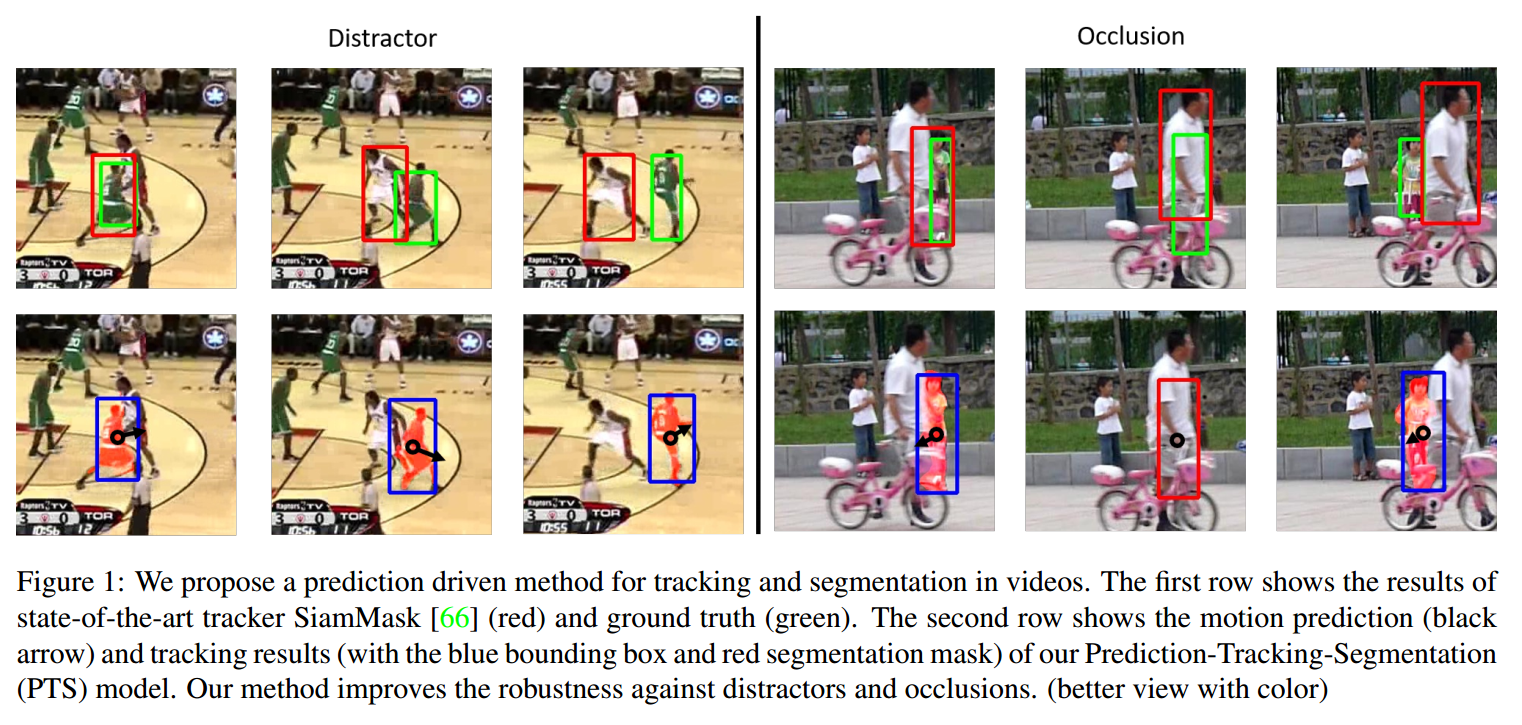
如上图所示,即便是目前 SOTA 的跟踪算法 SiamMask(CVPR-2019) 在处理遮挡问题上,也很是头疼。于是作者提出充分利用 motion information 来解决上述难度:
给定图像的目标运动是 camera motion 和 object motion 的叠加。前者是随机的,而后者是符合 Newton's First Law 。我们首先每间隔 n 帧,选择一个 reference frame,所以,将 long video 分解为多个 n-frame video 的短视频。第二,作者采用 ARIT("Action recognition with improved trajectories." ICCV 2013.)提出的方法来 camera motion 和 object motion 在每一个短视频内部进行分离。ARIT 假设 pending detection frame 及其 reference frame 是与 homography 相关的。这个假设在大部分的场景下都是成立的,因为一般两帧时间的运动是较小的。为了预测 homography,第一步是找到两帧之间的对应关系。在 ARIT 中,我们组合了 SURF features 和 从光流中得到的 motion vectors,来产生足够的和互补的候选匹配。此处,我们采用 PWCNet (Project,Code) 来进行 dense flow generation。
由于 homography matrix 包含 8 个 free variables,至少应该用 4 个 background points pairs。我们用 Eq 1 来计算 the least square solution,并且用 RANSAC 优化得到鲁棒的 solution。由于有如下的假设:the background occupies more than half of the images, 我们将视频帧之间的 matching points 分化为 4 个部分,然后每一个 point 在每一个选择的 piece 内部是随机选择的,用于改善 RANSAC algorithm 的效率:

简单起见,所有的后续操作都是在 reference coordinate,投影回当来的视频帧。图3 展示了分解步骤的工作原理:

这个视频是由手持摄像机拍摄的,并且有抖动的背景。行人的运动是高度不可预测的。但是,通过将 target frame 投影到 reference frame 上,行人的运动变的更加可预测和连续。为了找到最具有代表性的目标位置,我们计算了物体分割的 “center of mass” :

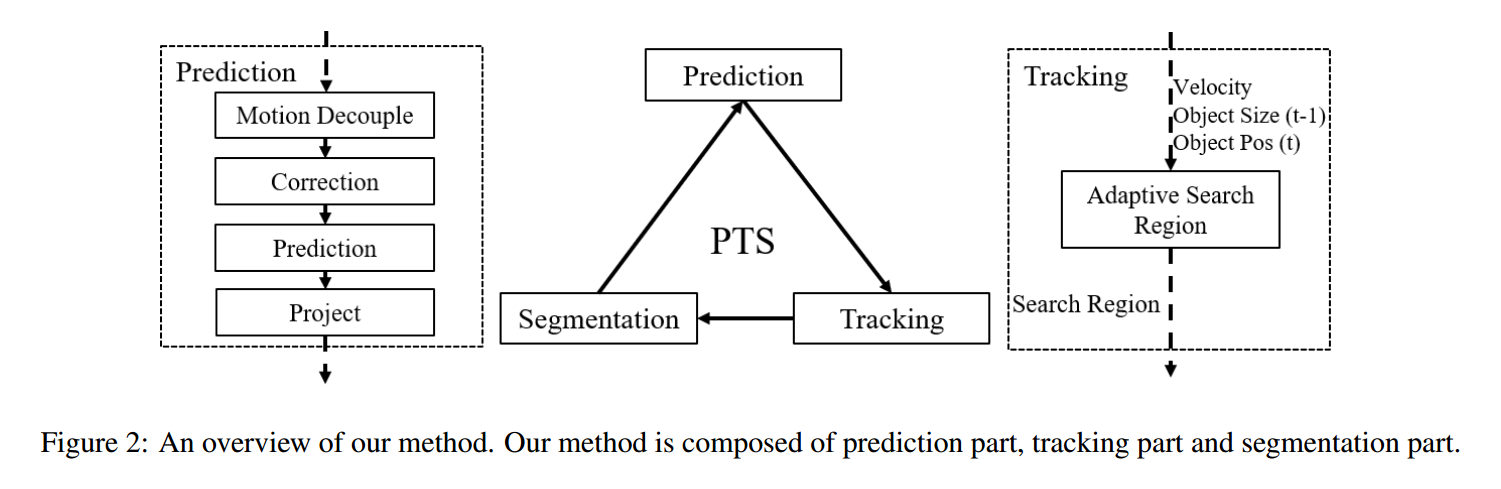
背景运动预测 和 掩膜分割 的噪声可以被引入到物体位置预测中,从而影响预测的精度。为了更好的预测物体状态,我们利用 Kalman Filter 通过当前和前一帧的度量(measurement),来提供准确的位置信息。作为经典的跟踪算法,the Kalman Filter 通过如下两步来预测物体的状态:prediction 和 correction。在 Prediction 步骤,基于 the dynamic model (Eq. 3) 来预测目标状态,产生用于 Siamese Tracker 的搜索区域,以进行物体分割。所以,下一帧物体位置的预测度量可以用 Eq. 2 来计算。然后,在 Correction 步骤,给定来自 Siamese Network 的位置度量,在当前的步骤中,可以更加确定位置度量的置信度。
用于物体位置更新的 dynamic model 可以表达为:
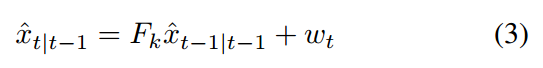
在上述公式中,等号左侧的 x 是 priori state estimation,是带有位置信息的 4 维的向量 [x, y, dx, dy]。需要注意的是,速度项 (dx, dy) 是从 time t-1 and t 之间的信息预测得到的。wt 是系统中的随机噪声。Ft 是从 time t-1 到 t 的转移矩阵。
在预测状态之后,the Kalman Filter 利用 measurements 来矫正其预测,用 Eq. 4。在公式中,$hat{y}_t$ 是 prediction 和 measurement 之间的 residuals。$K_t$ 是给定的最优 Kalman gain,从预测的噪声协方差,measure matrix and measurement matrxi covariance 中得到的,如公式 5 所示。
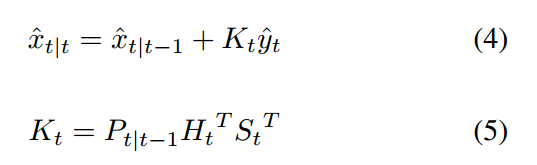
需要注意的是,由于 Kalman Filter 是一个 recursive algorithm,预测的 error covariance (P) 也应该根据预测结果,进行更新。
有了上述预测,我们就可以以上述预测的物体位置为中心点,确定一个搜索区域。我们将预测的物体中心位置投影回到 pending detection frame,用 Eq. 6:
![]()
给定预测的位置,我们从而可以设置搜索区域 S:
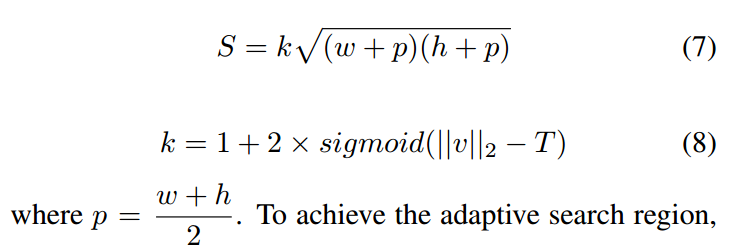
搜索区域大小 S 应该根据 Eq. 8 预测的速度,进行调整。v 是 Kalman Filter 预测的速度,T 是速度的阈值。搜索区域以中心点 $P_{r_k+t}$ 裁剪下来,然后 resize 到 255*255。
为了使得 one-shot segmentation framework 适合 tracking 任务,我们采用用于自动包围盒回归的优化策略,提供了较高的 IoU 和 mAP。
关于 Segmentation part,就和 SiamMask 很类似了,感兴趣的读者可以参考 SiamMask。

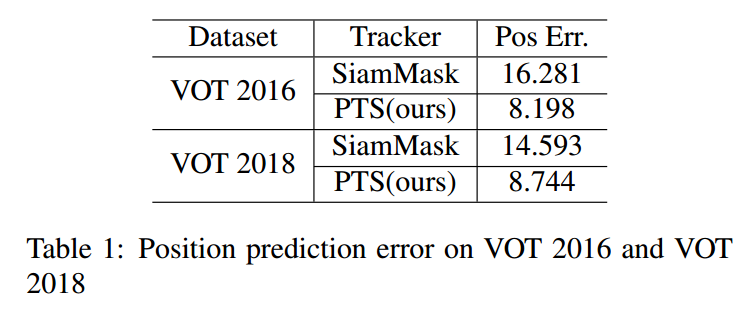
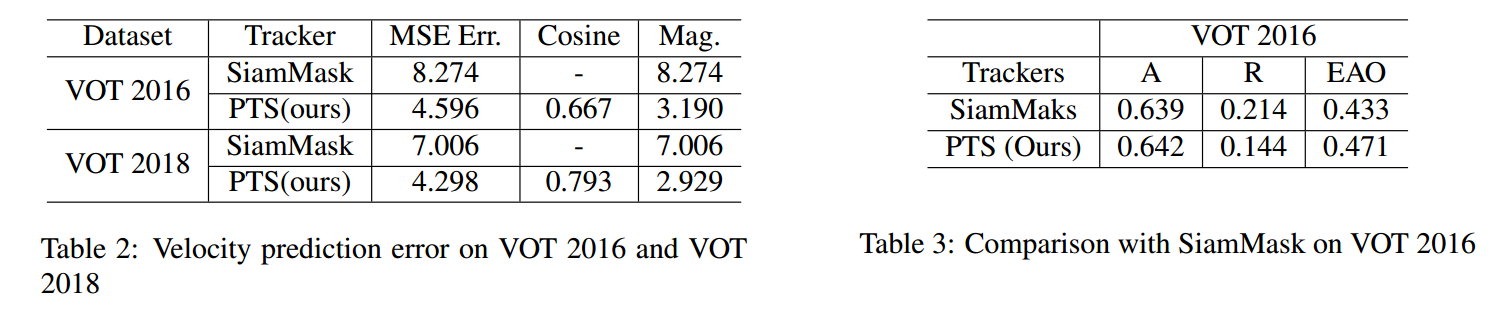


==