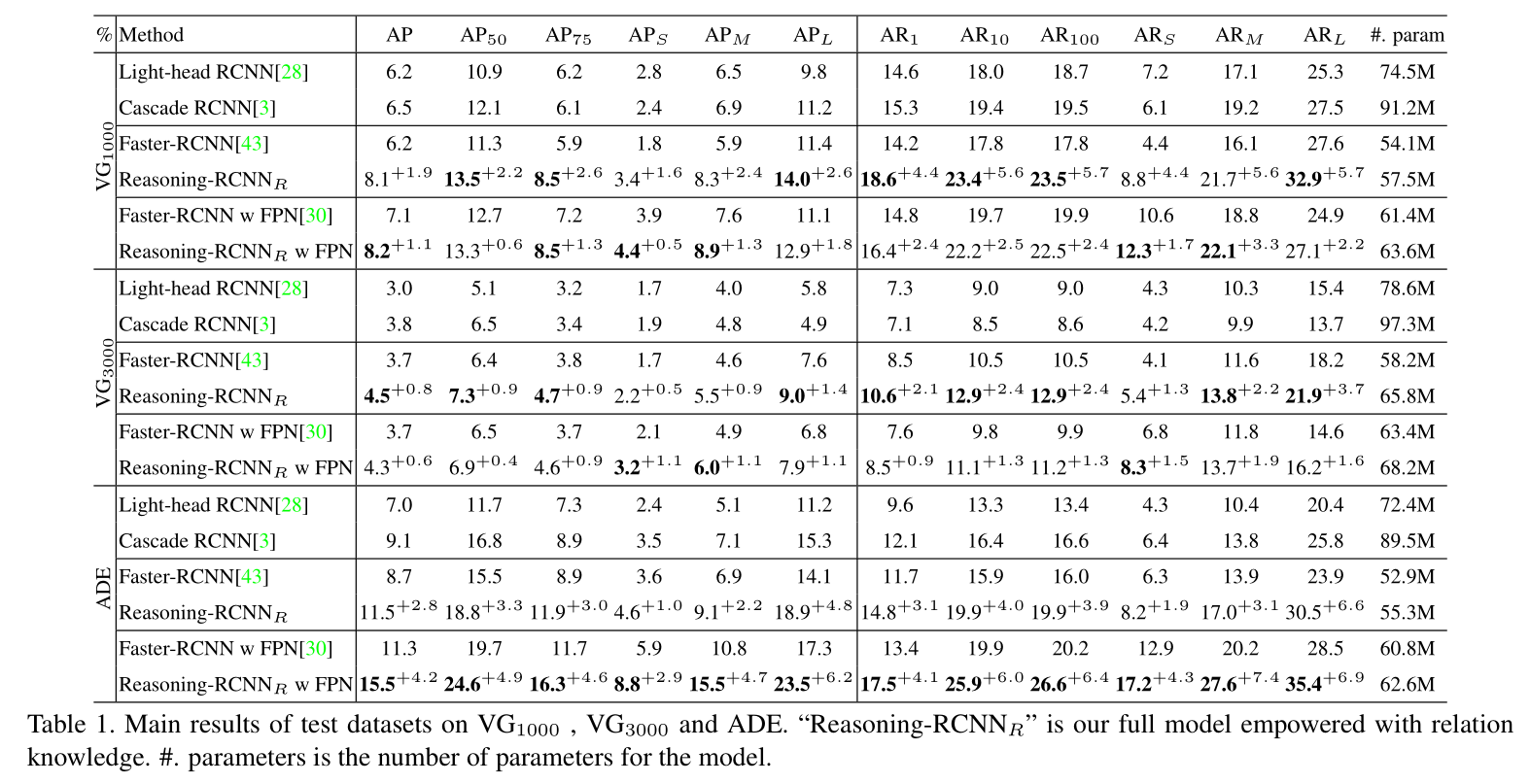
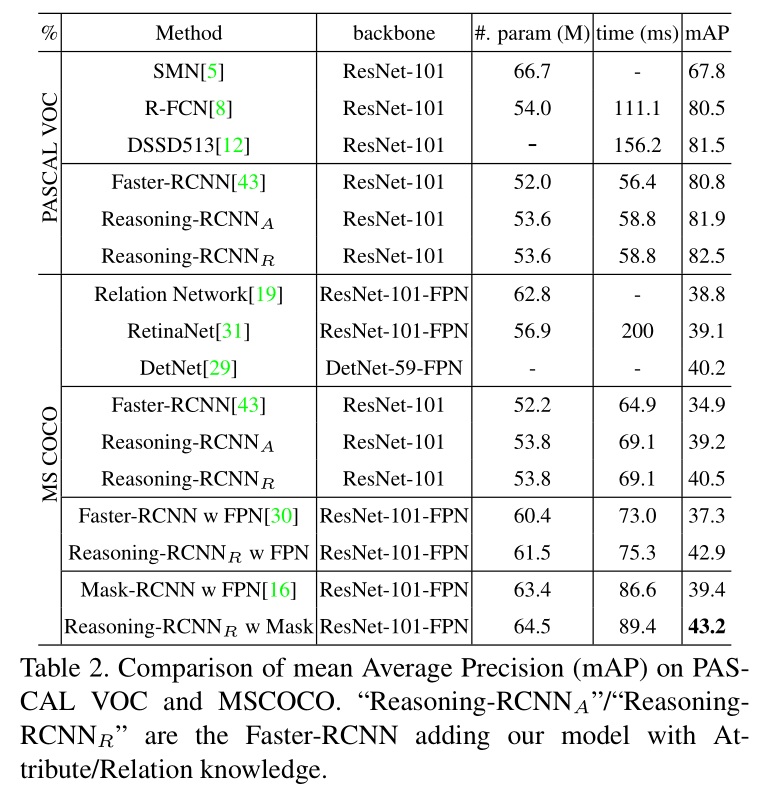
Reasoning-RCNN: Unifying Adaptive Global Reasoning into Large-scale Object Detection
2020-01-06 09:26:35
Paper:CVPR2019
Blog:link
Code: https://github.com/chanyn/Reasoning-RCNN
1. Background and Motivation:
本文要解决的问题是 large-scale detection,这个任务的一个特点就是有很多类别需要检测,并且类别之间有非常严重的类别不平衡。而本文则尝试从模型推理的角度,尝试让物体检测系统拥有人类的推理能力。

当识别场景中的一个物体时,通过人类常识来推理可以协助得到更加准确的结果。如图 1 所示,想要识别出上图中红色区域的 “CCTV”。人类会首先在脑海中搜索其记忆中相似的外观种类(这也是激发了本文 Global Semantic Pool),然后将会考虑全局语义的一致性来给出推理:this small electronic mental object is installed on the building and is watching the car running on the road and thus it is more likely to be a CCTV。这种丰富的人类常识可以在知识图谱中进行表达,并且可以在物体检测流程中结合到 visual reasoning 模块中。
视觉推理相关的工作可以按照如下的标准进行分类:是否依赖于人类先验知识。例如,一些工作直接将图像中隐式的空间关系进行建模。但是这些工作尝试隐式的和不受控制的学习 inter-region relationships, 所以他们的模型性能提升有限。其他的方法,尝试将人类语义先验知识通过在网络中定义 knowledge graphs 的方式。但是他们的方法有很多的缺陷,本文的方法尝试构建一种 in-place and simple global reasoning network,不但可以显示的将多种常识结合进来,而且可以从所有种类的角度全局的进行视觉信息的传播,从而改善分类和包围盒的回归。具体来说,本文的方法首先通过分类前面分类层的权重,产生一个 global semantic pool。然后一个 category-wise knowledge graph 被设计用于编码特定领域的知识(例如,属性,co-occurence,以及 relationships)。不同种类的高层语义内容在 global semantic pool 中进化,并且根据知识图谱链接的节点进行传播。本文不是从所有语义信息进行信息传递,这样会引入噪声,本文的自适应全局推理通过一个注意力机制进一步编码了当前图像,来自动挖掘最相关的类别来进行特征进化。接下来,增强后的类别内容通过一个 soft-mapping mechanism 映射到 regions,这确保了前一个阶段不准确的分类结果得到优化。最终,每一个区域新增强的 feature 和 原始的 feature 进行组合,以端到端的方式,来改善分类和定位的精度。本文的实验用两种先验知识的方式:relation knowledge,例如 co-occurence 和 object-verb-subject relationship,以及 attribute knowledge(例如,颜色,情况)。
2. The Proposed Approach:
2.1. Overview:
如图 2 所示,本文所提出的 Reasoning-RCNN 可以在物体检测器中进行堆叠。更具体的说,本文首先创造了一个全局语义池(Global semantic pool)通过收集原始分类层的权重,来将高层语义表达结合到每一类中。然后,定义一个 category-to-category undirected graph G:G=<N, E>,在训练和测试阶段是共享的,其中 N 是种类的节点,每一个 edge $e_{i,j}$ 编码了两个节点之间的一种知识。区域特征可以通过全局语义池上语义内容的传播得到增强。最终,增强后的特征和原始的特征进行组合,输入到分类和回归层,得到更好的检测结果。
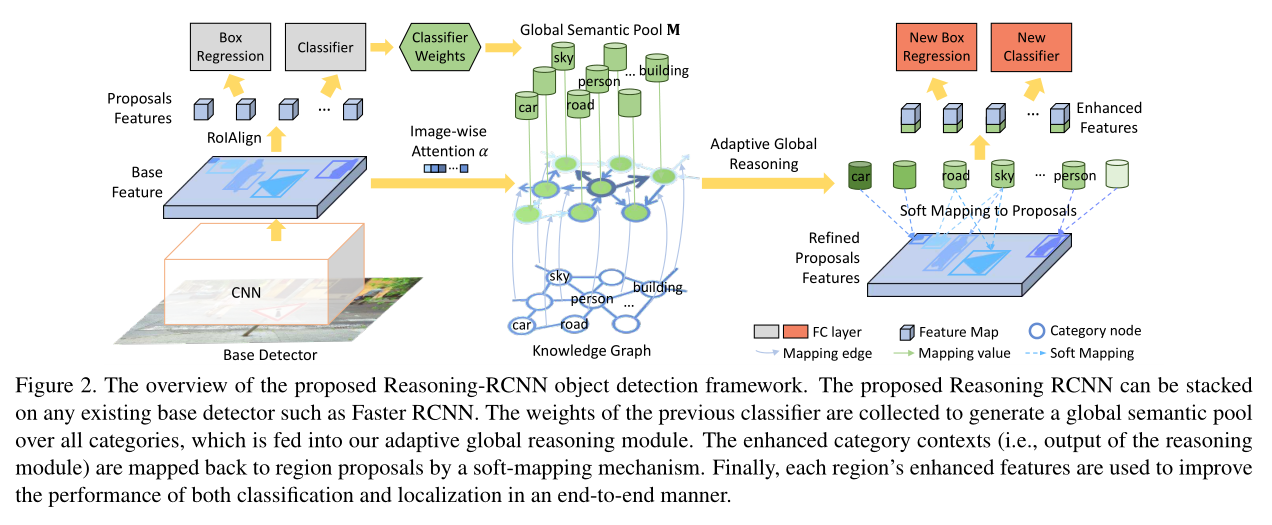
2.2. Adaptive Global Graph Reasoning Module:
自适应全局图推理模块如图 3 所示,对于所有的 region proposal,先抽取其特征,记为 f。本文方法的目标是增强原始 region features f,通过探索特地你该的常识,例如 pairwise relationship knowledge 或者一些 attribute knowledge。具体的,本文的全局推理阶段根据category-to-category knowledge graph G,在全局语义池中对 visual object reference 进行升级进化。此外,也引入注意力机制来自动的挖掘更具有信息性和相关性的种类来确保自适应全局推理。这样就可以增强 f 的特征,以改善最终检测的性能。
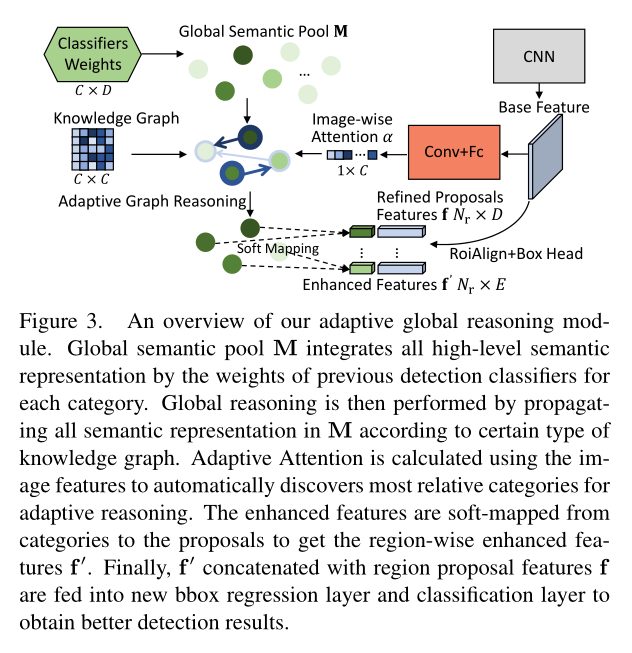
2.2.1. Global Semantic Pool M:
现有的方法通常在 regions 之间进行视觉特征的传递。然而,这种方式将会导致图推理的失败。相反,本文的方法尝试在所有的种类中进行全局信息传递(不仅仅出现在图像中出现的那些类别)。为了达到这些目标,本文尝试构建一个 global semantic pool 来存储高层语义表达。这就类比于当人类开始回顾特定种类物体的外观时人脑中的记忆。
为了产生这种 global semantic pool,现有的工作通常借助 feature 的优势,或者利用聚类的方法来找到 reference features 的中心。然而,这些方法在整个数据中,记忆和收集所有的信息,这就带来很大的计算代价。此外,这些模型无法以端到端的方式进行训练。受到 zero/few-shot problem 一些工作的启发,他们尝试训练一个模型来拟合未见或者不熟悉种类分类器的权重,而本文则提出一种新的方式来产生全局语义池。每一种分类器的权重实际上包含了高层语义信息,因为他们记录了从所有图像的特征激活(feature activation)。正式的来说,M 代表所有 C 种类之前分类器的权重。本文的全局语义池可以通过从之前分类层的参数 M 来得到。在训练阶段,分类器在每一次迭代中进行更新,这样就可以使得 M 越来越准确。此外,本文模型可以用端到端的方式进行训练。
2.2.2. Feature Enhanced via Graph Reasoning:
在对所有的 C 类物体,创建 global semantic pool M 之后,很自然的就可以在先验知识图谱 G 的 edge E 来传递链接的中种类。所以,所有 C 类物体的信息都是共享和全局传递的。为了增强这些区域的特征,本文仍然需要找到 Nr region proposal 和 C 类之间的映射。这个映射可以从前一个阶段得到分类结果。本文没有采用从 region proposal 到 categories 的 hard-mapping,而是采用了一种 soft-mapping 的方式,即:所有 C 类物体的分类概率分布 P。这个概率分布 P 可以用 soft-max 对前面的分类器得到的 C 类得分而得到。然后,这个过程可以通过矩阵相乘的方式来求解:$PEMW_G$,其中 $W_G$ 是所有 graphs 中共享的 转移权重矩阵,E 是推理模块的输出维度。需要注意的是,这种全局推理是基于所有种类的,可能包含噪声。一个自适应的推理机制需要结合每一个特定图像的视觉模式。这也是为什么需要进一步引入 attentional adaptive reasoning。
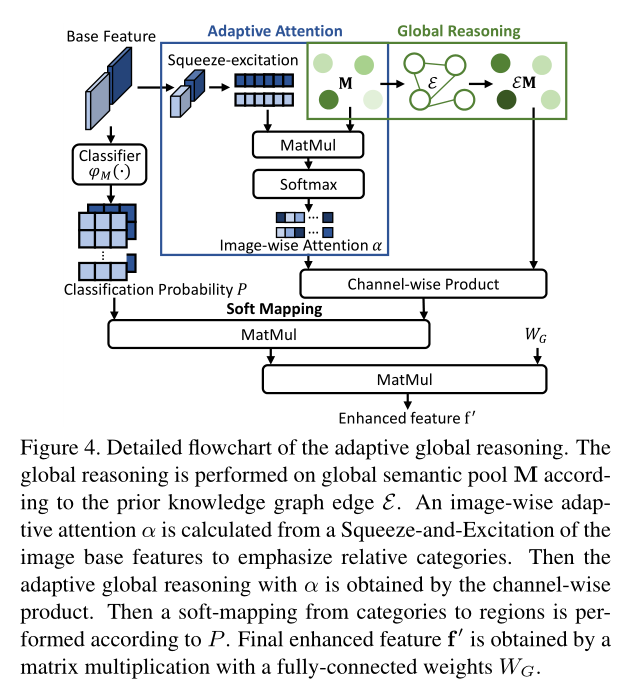
2.2.3. Adaptive Attention:
给定进化之后的全局特征 EM,接下来需要强调 informative and relative categories,并且抑制无用的那些信息,所以,就可以确保每一个图像都可以进行自适应推理。需要注意的是,并非所有种类的信息都对特定图像的识别有用。当识别一个场景中的东西时,人类也只会考虑某些特定的类别。在本文中,作者利用了 Squeeze-and-Excitation 的想法来进一步 re-scale 考虑到的种类。特别的,在 squeeze 阶段,作者将整幅图的特征 F 作为输入,然后用 CNN 和 global pooling operation 将其 squeeze 为一半的大小。excitation 阶段是一个 全连接层,输入为 $z_s$。然后一个 soft-max function 被用于得到每一个种类的 attention:$alpha = softmax(z_s W_s M^T)$,其中 $W_s$ 是全连接层的权重。然后,用自适应推理得到的增强特征 f',可以通过如下的方式进行求解:
![]()
其中, f' 就是增强特征,该自适应全局推理的过程参考图 4。最终,增强后的特征 f' 将会和原始的特征 f 进行组合,然后输入到BBox 回归和分类层得到最终的检测结果。需要注意的是,f' 是带有 edge 的种类提取出来的信息,例如 similar attributes 或者 relations。所以,few training samples 的问题可以通过共享相似种类之间的共享特征来得到解决。这些带有严重遮挡,类别模糊,小物体等的 Proposal regions 可以通过从由额外知识引导的全局语义池添加和发现自适应的内容得到纠正。
2.3. Model Specification with Relation Knowledge:
Reasoning-RCNN 可以结合到任意类型的知识。此处,作者将 relationship knowledge 当做一个案例来展示如何将不同的常识 G 来得到 distinct graph reasoning behaviors。本文也探索了另外一种知识,即:the attribute knowledge。
Relationship knowledge $G^R$ 作为一种 G,表示物体之间的关系,例如:“subject-verb-object” relationship(如 drive,run),spatial relation(如,on,near)。全局语义池将会被高层语义关系得到增强。
首先,作者计算了一个 C*C 的频率统计矩阵 $R^c$,来自语义信息或者简单的从所有种类对的出现次数得到。
然后,作者添加转置 $(R^c)^T$ 到 $R^c$。
最终,执行列和行的归一化,得到 $G^R$:![]() 。
。
需要注意的是,作者已经将许多空间关系,例如 “along”,“on” 和 “near”包含进来,这样是为什么不单独考虑空间关系。
3. Experiments: