Deep Learning for Time Series Classification (InceptionTime)
2020-02-03 17:02:30
Index
- Motivation
- Machine Learning for Time Series Classification
- Best Deep Learning practices for Time Series Classification: InceptionTime
- Understanding InceptionTime
- Conclusion
1. Motivation
Time series data have always been of major interest to financial services, and now with the rise of real-time applications, other areas such as retail and programmatic advertising are turning their attention to time-series data driven applications. In the last couple of years, several key players in cloud services, such as Apache Kafka and Apache Spark, have released new products for processing time series data. It is therefore of great interest to understand the role and potentials of Machine Learning (ML) in this rising field.
In this article, I discuss the (very) recent discoveries on Time Series Classification (TSC) with Deep Learning, by following a series of publications from the authors of [2].
2. Machine Learning for Time Series Classification
Defining the problem:
TSC is the area of ML interested in learning how to assign labels to time series. To be more concrete, we are interested in training an ML model which when fed with a series of data points indexed in time order (e.g. the historical data of a financial asset), it outputs labels (e.g. the industry sector of the asset).
More formally, let (X, y) be a training instance with T observations (X¹, … ,Xᵀ)≡ X (the time series) and a discrete class variable y which takes k possible values (the labels). A dataset S is a set of n such training instances: S= { (X₍₁₎, y₍₁₎), … , (X₍ n₎, y₍ n₎)) }. The task of classifying time series data consists of learning a classifier on S in order to map from the space of possible inputs {X} to a probability distribution over the labels {y¹, … , yᵏ}.
Do we really need DL?
It is always important to remind ourselves that DL is nothing but a set of tools for solving problems, and although DL can be very powerful, that doesn’t mean that we should blindly apply DL techniques to every single problem out there. After all, training and tuning a neural network can be very time-consuming so it is always a good practice to test the performance of other ML models and then seek for any potential shortcomings.
Oftentimes the nature of a problem is determined by the data itself; in our case, the way one chooses to process and classify a time series depends highly on the length and statistics of the data. That being said, let us run a quick dimensional analysis to estimate the complexity of our problem.
Suppose that we wish to learn a one-nearest neighbor classifier for our TSC problem (which is pretty common in the literature). Now given a dataset of n time series of length T, we must compute some sort of a distance measure for ⁿC₂=n(n-1)/2 unique pairs. Moreover, in order to find the “optimal distance” between two time series X₍₁₎ and X₍₂₎, we must compute the T×T point-wise distance matrix Mʲᵏ=(X₍₁₎ ʲ -X₍₂₎ᵏ)² for every unique pair of training instances and then seek for the path which optimizes our objective function. As explained in [3], there are several optimization algorithms in the literature for this setup, and they all have complexity O(n²⋅ Tᶜ) with c=3 or 4. Evidently, the length of the time series can really hurt the computational speed. However for certain types of data, this problem can be alleviated without digging into sophisticated machine learning models such as deep neural networks.
In signal processing, a complex signal is analyzed by decomposing the signal into a series of “elementary” signals, called Fourier modes. For instance, the square wave below can be approximated by three sinusoidal signals of distinct frequencies (f₁, f₂, f₃)=(ω, 3ω, 5ω), for some constant angular frequency ω.
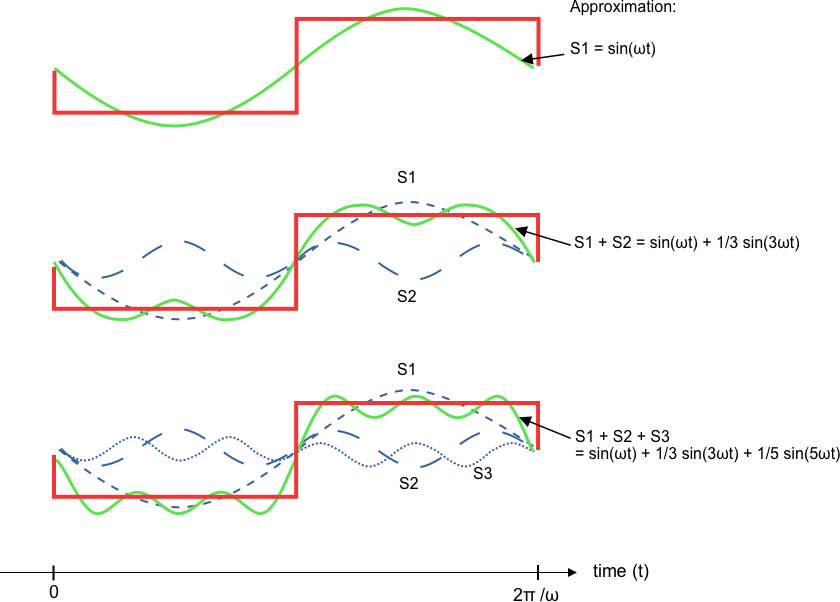
By taking the linear sum of these signals, we can reconstruct our original signal:
Square Wave(t) = W¹ ⋅ sin(f₁ t) + W² ⋅ sin(f₂ t) + W³ ⋅ sin(f₃ t)+ …
where the coefficients (W¹, W², W³) = (1, 1/3, 1/5) specify the weight that each mode contributes to the square wave.
Now consider a dataset within which any time series, originally represented by a series of T time-ordered data points, can also be represented by a weight vector in the space spanned by the three elementary frequency modes:
X=(X¹, … , Xᵀ ) → W=(W¹, W², W³, …) .
Going from the “time” representation to the “frequency” representation of our time series data is called Fourier transformation, and though the Fourier space, in theory, is infinite-dimensional (rather than 3-dimensional), we can apply various approximation techniques to truncate the Fourier series down to finite dimensions. Most importantly, we can reduce the T-dimensional representation of our time series data, to a number of dimensions (in Fourier space) that makes our classification problem computationally trackable. Overall, we can apply Fourier transformation during the data pre-processing phase to convert the input time series into weight vectors, and thereafter proceed by building our classification model (e.g. a 1-nearest neighbors classifier). Working with such “well-behaved” time series we can achieve high performance without the use of DL.
Now the aforementioned processing method assumed that any input signal can be approximated by a Fourier series of elementary (harmonic) functions. However, a lot of real-world time-series data are so noisy (e.g. financial data) that do not admit such an elegant decomposition (or any sort of mathematical pre-processing). It is precisely for this type of data that DL comes to the rescue: letting the model learn how to process time series data on its own is a more promising solution when dealing with unstructured noisy data.
3. Best DL practices for TSC: InceptionTime
As of today, there are two state-of-the-art DL models for TSC. The oldest model, called HIVE-COTE [4], is based on the nearest neighbor algorithm coupled with the Dynamic Time Warping similarity measure. Although this algorithm has achieved an outstanding performance on the benchmark datasets [5], it suffers from O(n ²⋅ T ⁴)time complexity. Recently the authors of [6], introduced a deep Convolutional Neural Network (CNN), called InceptionTime, which not only outperforms the accuracy of HIVE-COTE but it is also substantially faster. InceptionTime’s high accuracy together with its scalability renders it the perfect candidate for product development!
To this end, let us present the most important components of InceptionTime and how these are implemented in Keras.
3.1 The Input Layer
In general, each data observation Xʲ (j=1, … ,T) of a time series X can be a list of one or more data measurements, i.e. Xʲ = ( X₁ʲ, … ,X_m ʲ ) for m data measurements, all taken at the jth time instance. For example, the velocity of a particle moving in 3D space consists of three spatial components: V=(V₁, V₂, V₃). Keeping track of the velocity of the particle for T seconds, with one observation per second, amounts to collecting the series of data: (V¹, … , Vᵀ ).
Definition 1: An m-dimensional Multivariate Time Series (MTS) X= (X¹, … , Xᵀ) consists of T ordered elements Xʲ ∈ ℝᵐ.
Definition 2: A Univariate time series X of length T is simply an MTS with m=1, i.e. Xʲ → Xʲ ∈ ℝ and X= (X¹, … , Xᵀ ).
Like in image classification problems, we can think of the input MTS as an array of shape (1, T, m), with m denoting the number of channels (the depth). In fact, it is convenient to suppress the width of the inputs and work directly with an input_shape = (T, m).
3.2 The Inception Module
The major building block of InceptionTime is the inception module, shown in the figure below:

This consists of the following layers:
- A bottleneck layer to reduce the dimensionality (i.e. the depth) of the inputs. This cuts the computational cost and the number of parameters, speeding up training and improving generalization.
- The output of the bottleneck is fed to three one-dimensional convolutional layers of kernel size 10, 20 and 40.
- The input of the inception module is also passed through a Max Pooling layer of size 3 and in turn, through a bottleneck layer.
- The last layer is a depth concatenation layer where the outputs of the four convolutional layers at step 2 are concatenated along the depth dimension.
All layers (excluding the concatenation layer) have stride 1 and “same” padding. In addition, all convolutional layers come with 32 filters.
Keras Implementation

3.3 The Inception Network
The network architecture of InceptionTime highly resembles to that of GoogleNet’s [7]. In particular, the network consists of a series of Inception modules followed by a Global Average Pooling layer and a Dense layer with a softmax activation function.

However, InceptionTime introduces an additional element within its network’s layers: residual connections at every third inception module.
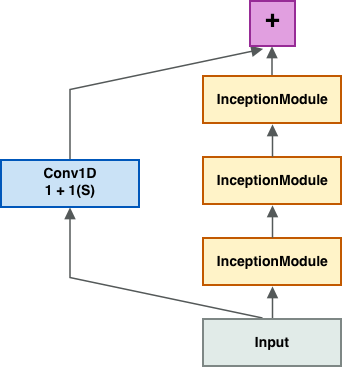
Keras Implementation

3.4 InceptionTime: a neural network ensemble for TSC
As explained in [6], it turns out that a single Inception network exhibits high variance in accuracy. This is probably because of the variability associated to the random weight initialization together with the stochastic optimization process itself. In order to overcome this instability, the proposed state-of-the-art InceptionTime model is actually an ensemble of 5 Inception networks, with each prediction given an even weight (see [8] for more on deep neural network ensembles for TSC). The full implementation of the model can be found on Github.
4. Understanding InceptionTime
As it was mentioned earlier, InceptionTime was primarily inspired by CNNs for computer vision problems, and we, therefore, expect our model to learn features in a similar fashion. For example, in image classification, the neurons in the bottom layers learn to identify low-level (local) features such as lines, while the neurons in higher layers learn to detect high-level (global) features such as shapes (e.g. eyes). Similarly, we expect the bottom-layer neurons of InceptionTime to capture the local structure of a time series such as lines and curves, and the top-layer neurons to identify various shape patterns such as “valleys” and “hills”.
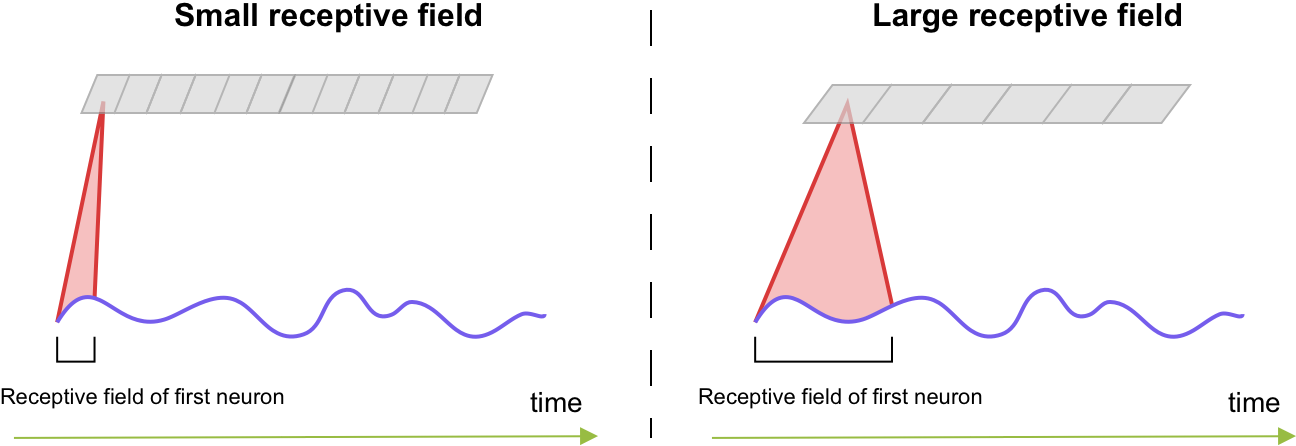
The region of the input signal that a neuron depends on is called the receptive field of that particular neuron. In object recognition, larger receptive fields are used to capture more context. It is therefore natural to pick larger receptive fields when working with very long time series data so that our InceptionTime will learn to detect larger patterns.
5. Conclusion
An important aspect in TSC is the length of the time series as this can slow down training. Although there are various mathematical processing schemes that one can follow to tackle such a problem, InceptionTime is the leading algorithm for TSC, especially for long noisy time series data.
InceptionTime is an ensemble of CNNs which learns to identify local and global shape patterns within a time series dataset (i.e. low- and high-level features). Different experiments [6] have shown that InceptionTime’s time complexity grows linearly with both the training set size and the time series length, i.e. O(n ⋅ T)! Overall, InceptionTime has put TSC problems on the same footing with image classification problems, and it is therefore exciting to explore its different applications in the industry sector.
In an upcoming post, I will discuss how I used InceptionTime to classify and cluster financial assets based on different attributes, such as industry sector/class, location and performance.
References
[1] Learning Internal Representations by Error Propagation
[2] Deep learning for time series classification: a review
[3] The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms. Extended Version
[4] HIVE-COTE: The Hierarchical Vote Collective of Transformation-based Ensembles for Time Series Classification
[5] UCR Time Series Classification Archive
[6] InceptionTime: Finding AlexNet for Time Series Classification
[7] Going deeper with convolutions (GoogleNet)
[8] Deep Neural Network Ensembles for Time Series Classification