Learning When and Where to Zoom with Deep Reinforcement Learning
2020-03-03 14:47:08
Paper: https://arxiv.org/pdf/2003.00425.pdf
Related work: "Efficient object detection in large images using deep reinforcement learning." Uzkent, Burak, Christopher Yeh, and Stefano Ermon. In The IEEE Winter Conference on Applications of Computer Vision, pp. 1824-1833. 2020.
1. Background and Motivation:
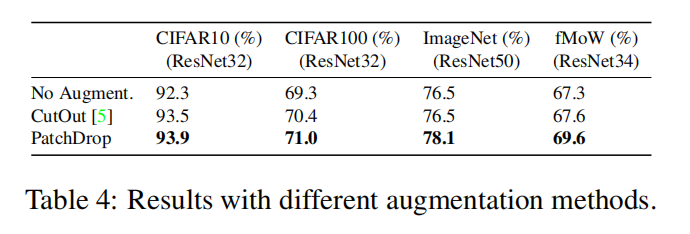
本文提出一种基于强化学习的方法来自动放大图像,从局部来处理超大型的图像,例如遥感数据。本文主要是从节省计算资源的角度来看的,即:尽可能少的使用高分辨率的信息,并且达到和使用高分辨率图像类似的效果。主要是提出了一种称为 PatchDrop 的方法,这是一种自适应采样的机制,仅仅从 HR image 上采样出一些图像块,如图 1b 所示。
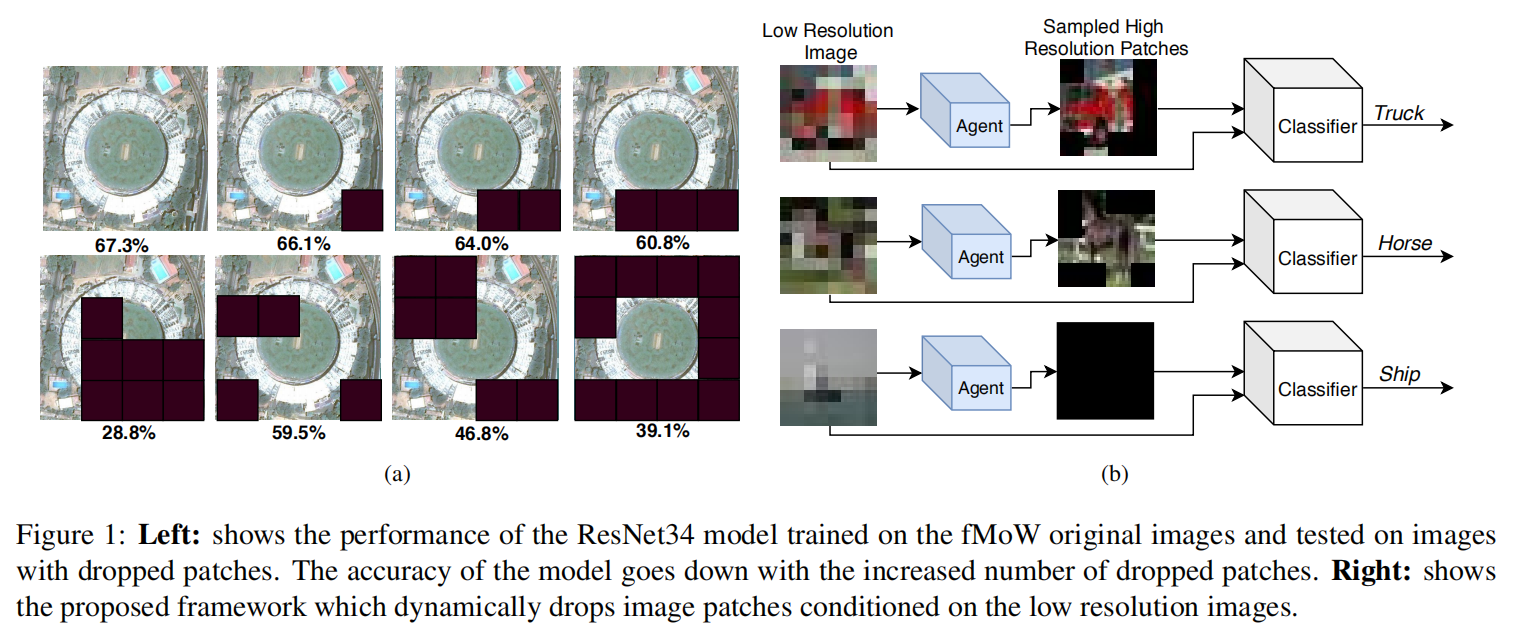
PatchDrop 利用输入图像的低分辨率版本来训练一个 agent,并且在需要的时候才去采样 HR patches。这样的话,agent 要学习 when and where 来放大局部图像来采样出 HR patches。
2. Problem Statement:
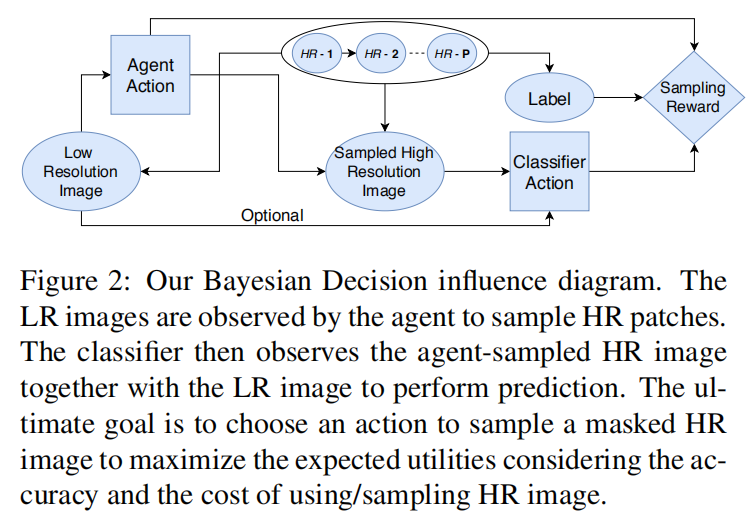
本文将 PatchDrop framework 建模成 two step episodic Markov Decision Process (MDP),如图 2 所示,作者用圆表示随机变量,用方块代表动作,用菱形代表示例。作者将高分辨率的图像划分为多个不重叠的子区域 $x_h$。与传统 cv 的设定不同,这里的 $x_h$ 是隐藏的,即:not observed by the agent。y 代表与 $x_h$ 相关的种类随机变量。$x_l$ 是 $x_h$ 的分辨率的版本。$x_l$ 刚开始被 agent 观测到来选择 binary action array $a_1$,其中 $a^p_1 = 1$ 代表 agent 将会采样 HR 图像的 第 p 个 patch。作者定义图像块采样策略模型参数化为 $ heta_p$:
![]()
其中,π 是一个将 LR image 映射到 patch sampling action a1 的概率分布。接下来,用 $a^p_1, x^p_h$ 来构成 random variable masked HR image, 掩码操作是:
![]()
第一步的 MDP 可以建模成随机变量 $x_h, y, x_h^m, x_l$ 以及 动作 $a_l$ 的联合概率分布:
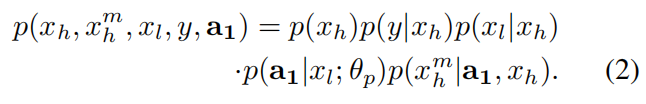
第二步的 MDP,agent 观测到随机变量 $x_l^m$ 和 $x_l$,然后选择一个动作 a2。然后定义一个分类预测策略:
![]()
其中 π2 代表分类器网络,并且参数化为 $ heta_{cl}$。总的学习目标,J 定义为:最大化期望 R:
![]()
其中,utility 依赖于 a1, a2, 以及 y。如果 agent 选择大量的 HR patches,就会得到惩罚; and includes a classification loss evaluating the accuracy of a2 given the true label y。
3. Proposed Solution:
3.1. Modeling the Policy Network and Classifier
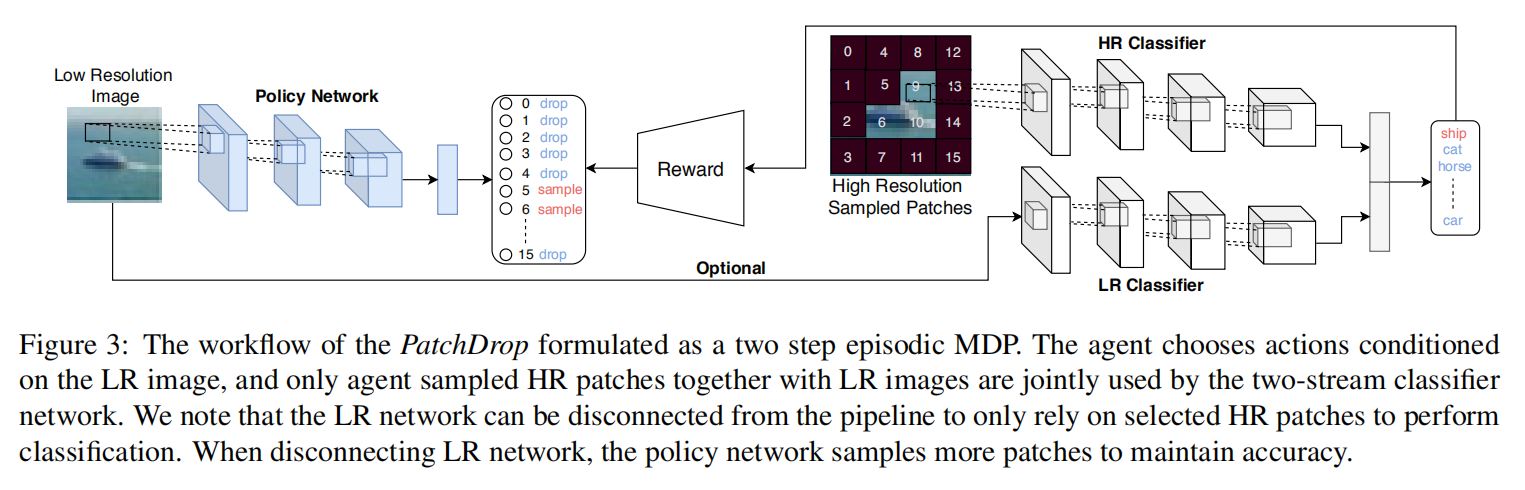
在第一个 MDP 中,the policy network fp,在观测到 xl 之后,输出所有 action 的概率。在本文中,作者建模策略网络的动作似然函数 fp,通过将单独的 HR patch 选择的概率,表示为 patch-specific Bernoulli distributions 如下:
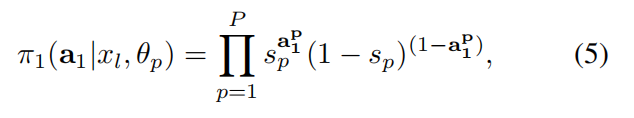
其中,sp 代表预测向量,表示为:
![]()
为了得到概率值, sp,作者在最后一层后面加上一个 sigmoid function。
另外一个动作的集合 a2,是根据分类器选择的,$f_{cl}$,利用采样到的 HR image 和 LR input $x_l$。分类器的上一个分支利用采样到的 HR images;另一个分支利用 LR image,如图 3 所示。每一个分支输出一个概率分布。然后,作者利用预测的加权平均得到融合之后的值:
![]()
其中,S 代表采样到的 patches 的个数。
3.2. Training the PatchDrop Network:
在定义了 two step MDP,并且建模了 policy network 和 classifier networks,作者对 PatchDrop 进行了更加细节的描述。训练的目标是学习最优的 $ heta_p$ and $ heta_{cl}$。由于 actions 是离散,无法使用 重采样的技巧来优化目标。为了优化 fp 的 $ heta_p$,作者需要利用 model-free RL 算法,例如 Q-learning, Policy gradient。作者将 REINFORCE 方法用于网络的训练:
![]()
蒙特卡洛采样产生了期望值的无偏估计来进行平均化,但是方差较大。作者将公式 8 中 $R_{a1, a2, y}$ 替换为 advantage function 来降低方差:
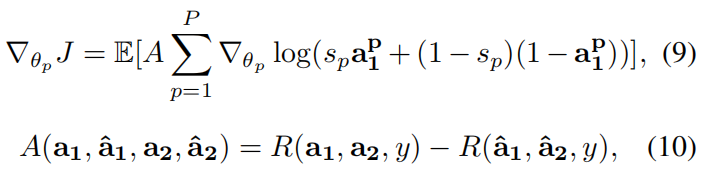

Pre-training the Classifier:
Pre-training the Policy Network:
Finetuning the Agent and HR Classifier:
Finetuning the Agent and HR Classifier:


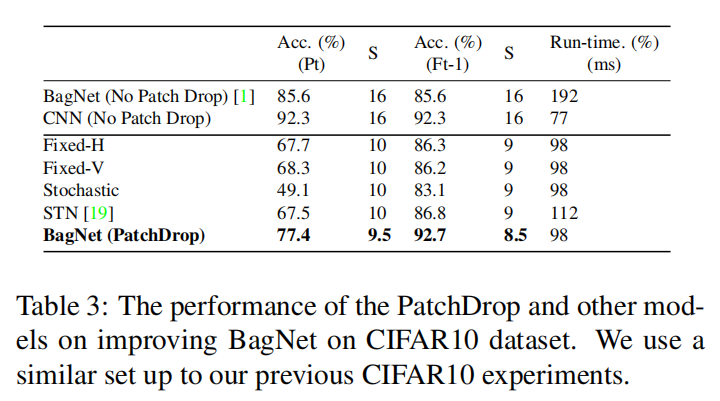
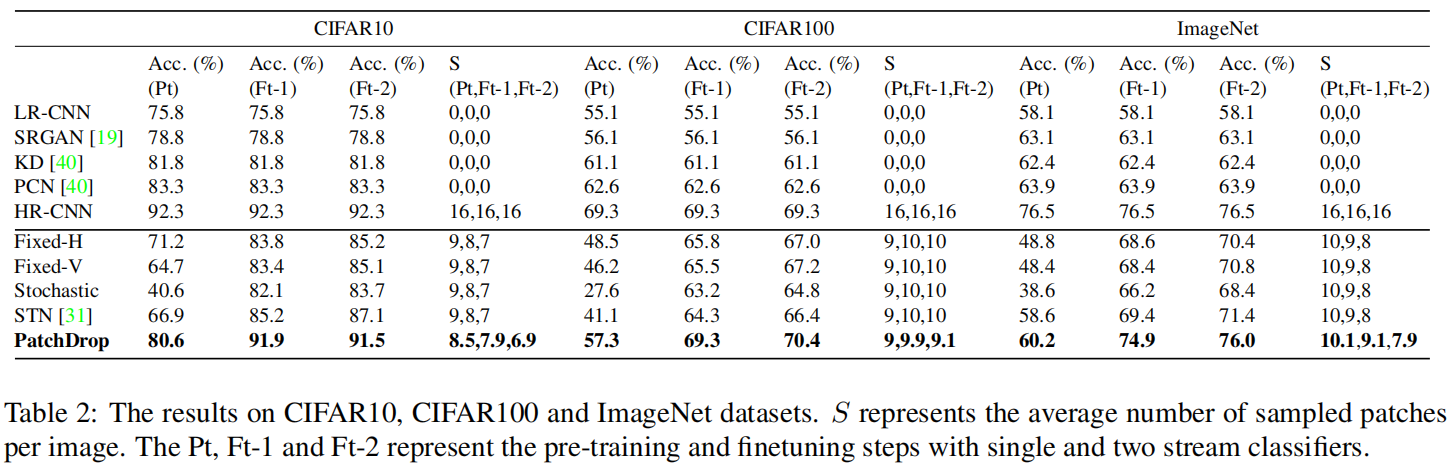
4. Experiments: