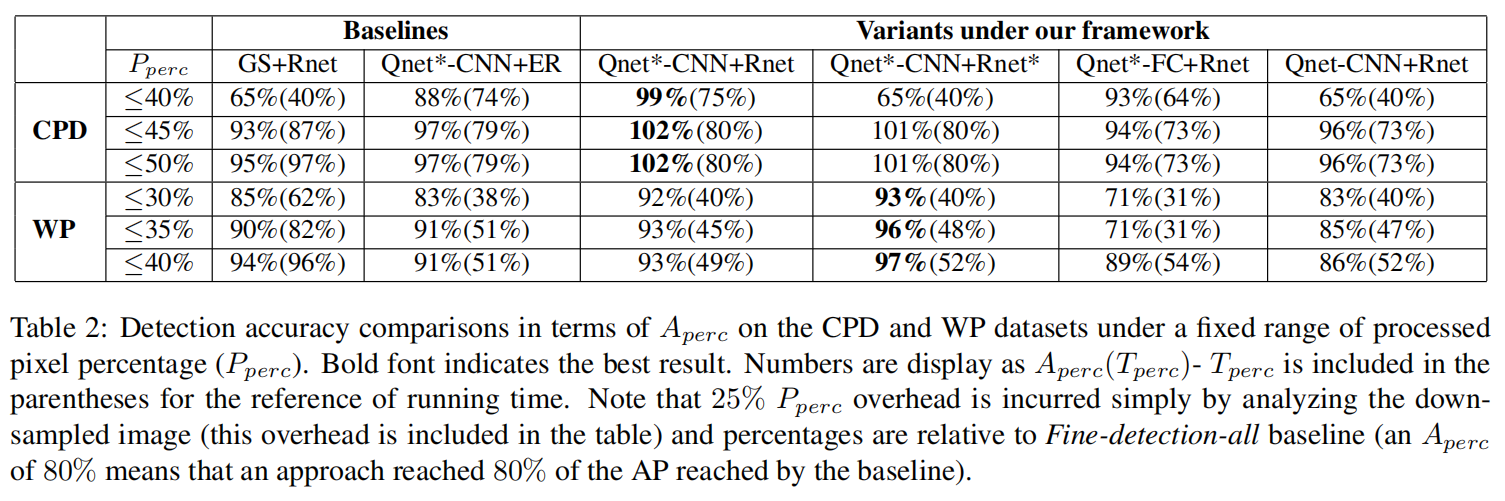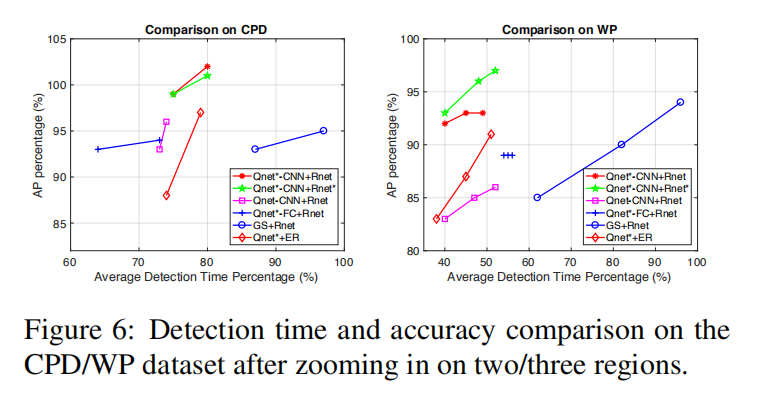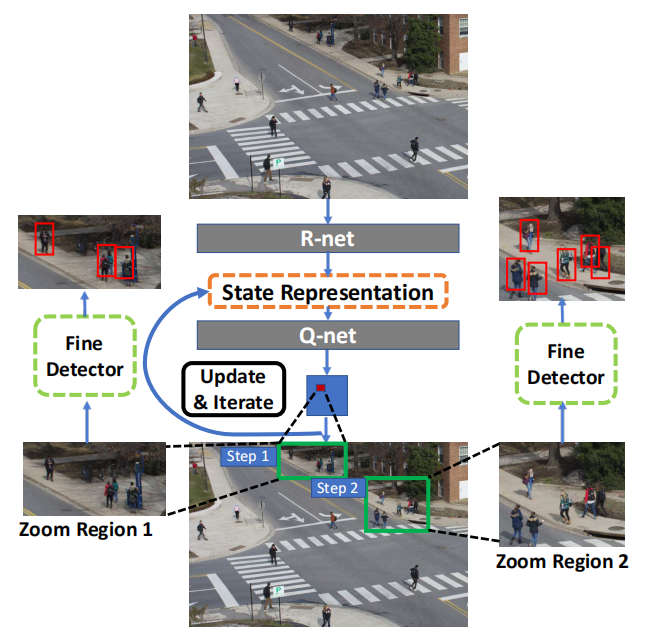
如图 1 所示, 本文提出一种 coarse-to-fine 的物体检测方法,即:先用低分辨率的图像推断出需要细粒度检测的位置,然后再对这些区域进行放大,进行细粒度的检测。这样做的好处是,仅仅需要少量的计算量就可以得到高分辨率图像的检测结果。本文的网络主要包含两个部分:一个机制是学习粗略和细粒度检测器之间的统计关系,这样就可以预测哪些区域需要进行放大处理;第二个机制是选择一系列的图像区域进行细粒度分析。
2. Dynamic Zoom-in Network:
2.1. Problem Formulation:
本文将该任务建模为马尔科夫过程,每一个时刻,该系统观察到当前状态,预测潜在的奖励,选择能够得到长期奖励的动作来执行:
Action:一个动作就对应了一个区域,(x, y, w, h),其中,x y 代表 location,w h 代表区域的高。在每一个时刻,算法都会对潜在的动作进行打分,即奖励。
State:作者将两种信息编码进来:1). 尚且没有被分析区域的预测精度;2). 已经分析过的区域历史。作者设计了一个 zoom-in accuracy gain regression network (R-net) 来学习一个 informative accuracy gain map (AG map) 作为状态的表达。该 AG map 和输入图像有相同的宽高,其每一个像素值代表了如果对应图像被选择,那么精度会提升多少。所以,AG map 提供了选择不同区域得到的检测精度。在执行一个 action 之后,在 AG map 上选择区域的值会对应的降低,所以 AG map 可以动态的记录 action history。
Reward:作者将 cost increment 和 accuracy improvement 都带到奖励函数的计算上:
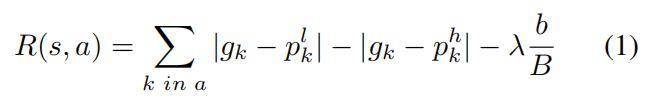
其中,第一项衡量了精度,第二项衡量了选择区域的多少。
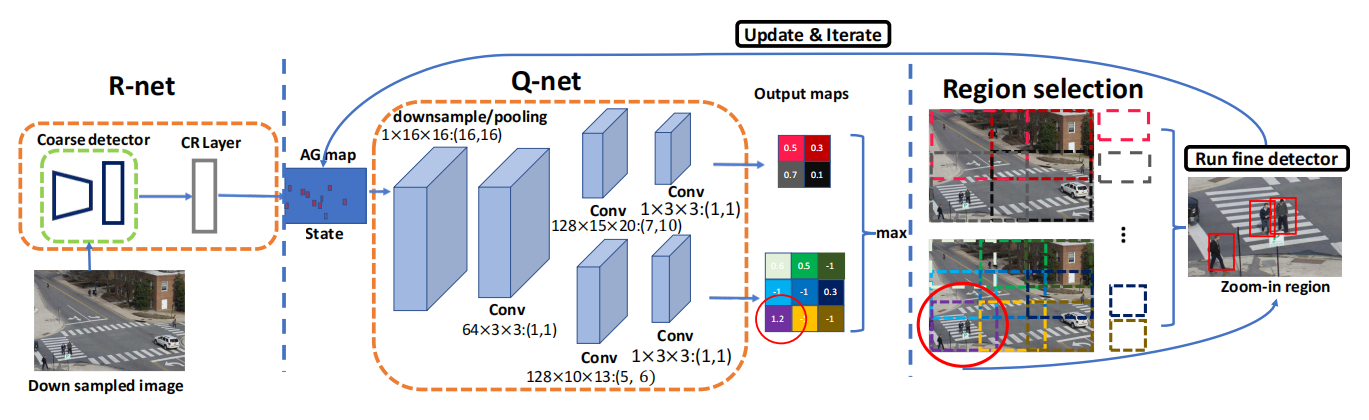
如上图所示,给定低分辨率的图像,R-Net 会将进行粗检测,然后该结果会反应到 AG Map 上,这个 map 其实类似 attention,反应出哪里应该重点照顾,然后该图输入到 Q-Net 中,该网络会对输出对应区域是否进行放大处理的得分。根据选择出来的区域,再进行扣 patch 块。再进行细粒度的检测。
3. Experiment: