Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking
2021-04-08 17:37:55
Paper: https://arxiv.org/pdf/2103.11681.pdf
Code: https://github.com/594422814/TransformerTrack
1. 概览:
本文考虑将 Transformer 引入到 Tracking framework 中,主要是考虑借助 Transformer 模块学习视频中的时序信息以辅助跟踪。并在 Siamese tracker 和 DCF tracker 上进行了结合,在多个数据集上都得到了不错的结果。
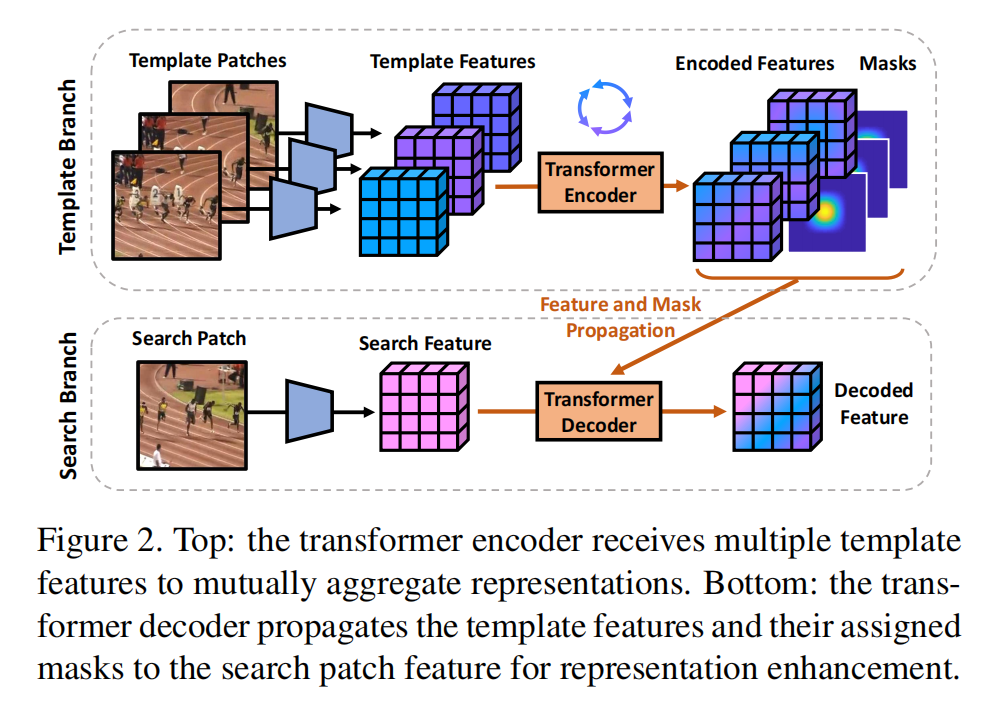
如上图所示,作者这里考虑两种 Transformer 的用法,即: frame-wise relationship modeling 以及 temporal context propagation。具体的 Transformer 架构,如下所示:
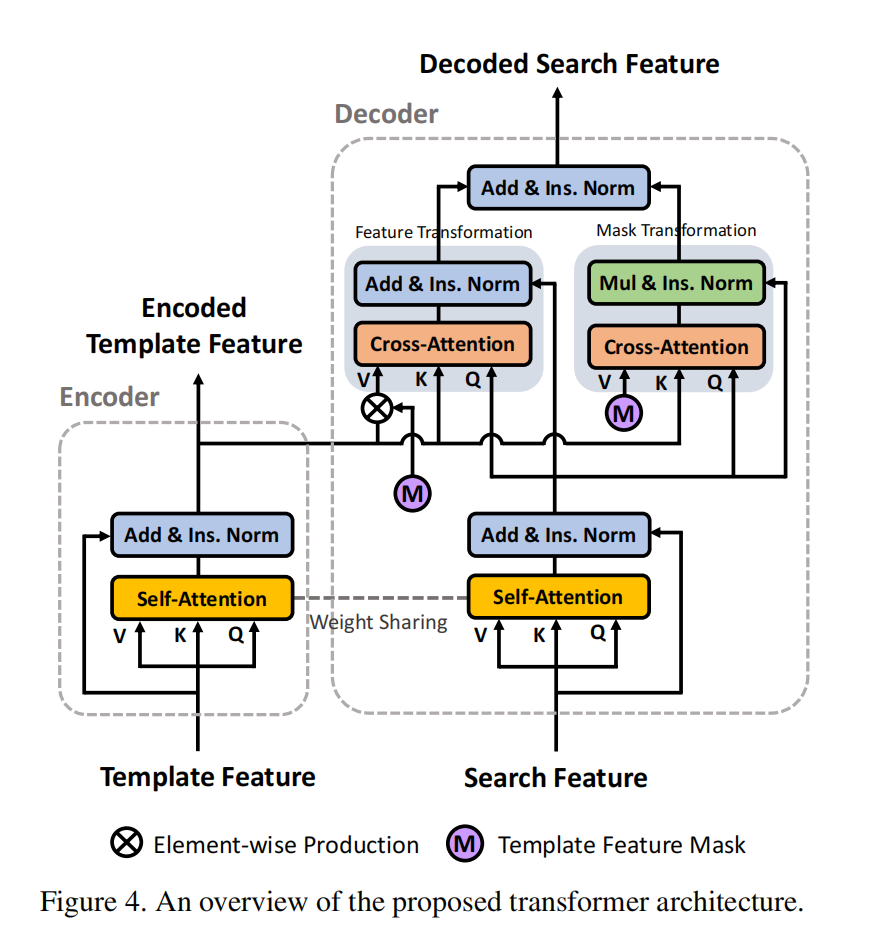
作者提到,为了使得该 Transformer 结构更加适合 Tracking 的任务,作者这里进行了如下几点改变:
1). Encoder-decoder separation:作者将 Transformer 结构分离为两个分支,以更加适合 Siamese-tracking 的框架;
2). Block Weight-sharing: 编码器和解码器模块中的 self-attention blocks 是共享的,将 template 和 search embeddings 在同一个特征空间进行转换,以进一步的促进 cross-attention 计算;
3). Instance Normalization:在 NLP 任务中,word embeddings 是单独的进行归一化的。因为本文中的 Transformer 结构接收到的是 image feature embedding,所以这里作者联合对这些 embedding 在 instance level (image patch)进行归一化。
4). Slimming Design:为了保持跟踪的效率,作者去掉了 FF layers,保持轻量级的单头注意力。
2. 网络结构:
2.1 Transformer Encoder:
Transformer 最重要的部分是 attention 机制,一般而然,输入是三个分支,即:query Q,key K, 以及 value V。一般的,首先用Q 和 K 进行点乘操作,得到一个 attention matrix (i.e., similarity matrix A):
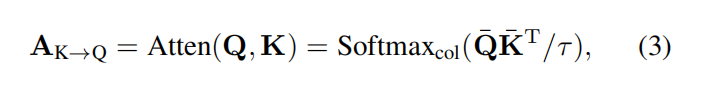
然后,利用该相似性矩阵 A,进行下一步的 attend 操作,从而实现 key 到 query 的传递。在这个框架中,Transformer encoder 接收到一组 template features T,进一步组成 template feature ensemble。为了促进 attention 的计算,作者将 T shape 为 T'。如图 4 所示,该 encoder 模块中的主要成分是 self-attention,因此,可以用于多个 template 之间实现特征增强。为了实现该目标,作者首先计算 self-attention map ![]() ,其中也用到了 1*1 linear transformation 进行降维处理。
,其中也用到了 1*1 linear transformation 进行降维处理。
基于该 self-similarity matrix A,作者将 template feature 进行转换,然后将输出和输入进行残差相加:
![]()
其中,该归一化的结果是编码后的 template feature。
2.2 Transformer Decoder:
解码器部分将 search patch feature S 作为其输入。首先将其 reshape 为 S',然后再利用 self-attention 机制进行特征增强:
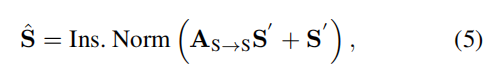
Mask Transformation:基于 search feature 和 编码后的 template feature,作者计算了这两者之间的 cross-attention matrix:
![]()
这种 cross-attention map 建立了 pixel-to-pixel 的一致性。 在视觉跟踪中,为了传递时序运动信息,作者构建了 Gaussian-shaped masks。作者将这些帧对应的 mask 进行组合,然后进行时序上的传递。这些转换后的 mask 被量化后作为 attention weight 进行特征加权:

其中,括号内的操作符表示 the broadcasting element-wise multiplication。
Feature Transformation:
3. Experimental Results:
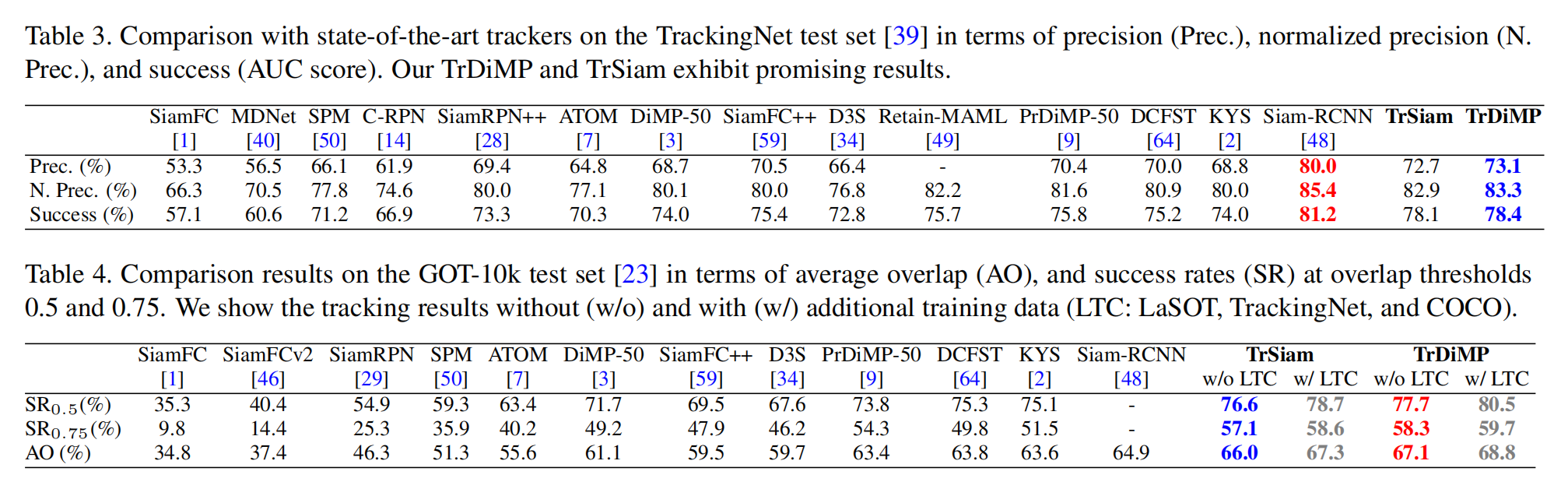


==