AST: Audio Spectrogram Transformer
2021-07-21 19:38:36
Paper: https://arxiv.org/pdf/2104.01778.pdf
Code: https://github.com/YuanGongND/ast
1. Background and Motivation:
最近 CNN+Transformer 的混合框架开始盛行,作者提出一个疑问:如果 Transformer 已经可以获得较好的结果了,那么是否还要使用 CNN 呢?作者提出了一个完全是 self-attention 的网络来处理音频信息,所提出的方法称为 Audio Spectrogram Transformer (AST)。作者总结了如下几点优势:
1). 性能好:在三个库上均获得了 SOTA 的结果;
2). 自然的支持变长的输入,可以用于多种任务;
3). 与 CNN-Transformer 的框架相比,作者提出的方法可以收敛的更快,结构更加简单。
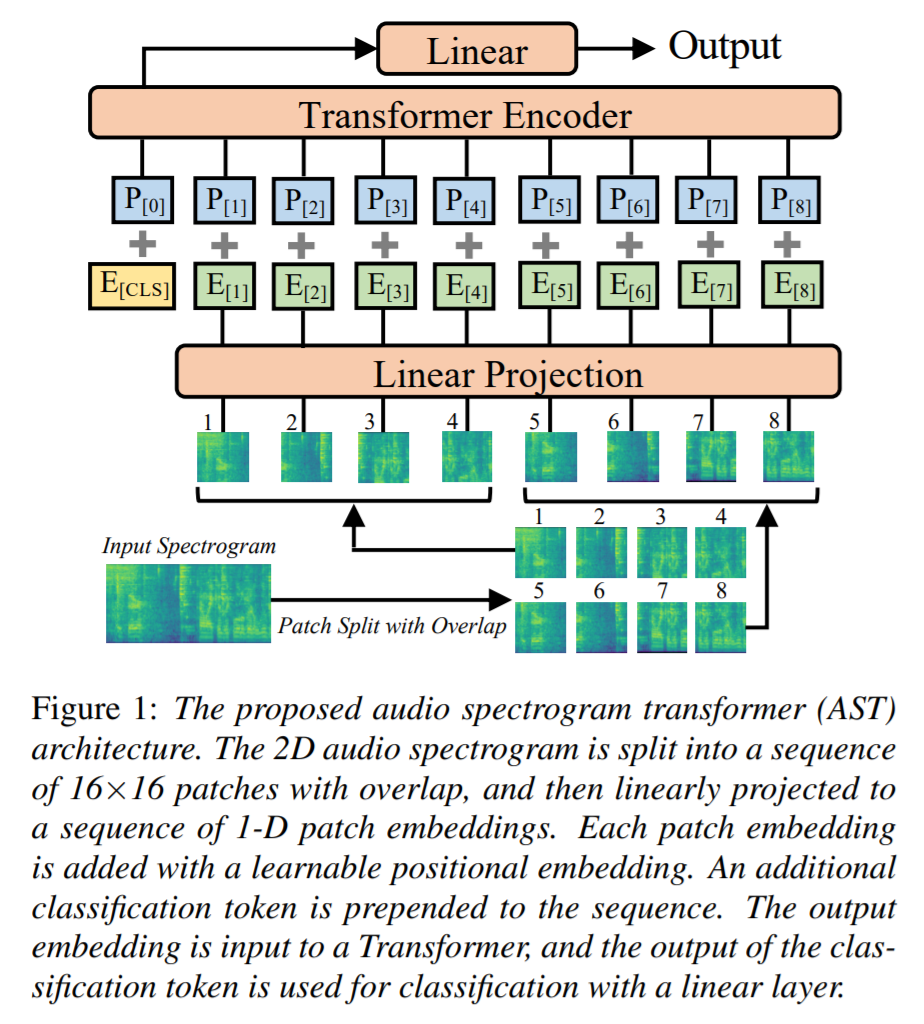
2. AST Model:
如上图所示,作者首先将 t 秒钟的 audio 信息转换为 一个 128-D 的 logMel filterbank (fbank) features,通过每10 ms 进行一次 25 ms 的Hamming window 进行处理。这样可以得到一个 128*100t spectrogram 作为 AST 模型的输入。然后对这个输入进行 patch 的划分,然后每一个 patch 的维度被映射为 768-D。然后用可学习的 位置编码映射,对每一个 patch 进行位置学习。得到的向量,与 feature embedding 进行相加。作者也添加了一个可学习的 [CLS] 符号。
由于语音数据并不多,作者想用 ImageNet 预训练的模型进行迁移。因此,作者提出了一种 cut and bi-linear interpolate method 进行位置映射的适应。
3. Experimental results:
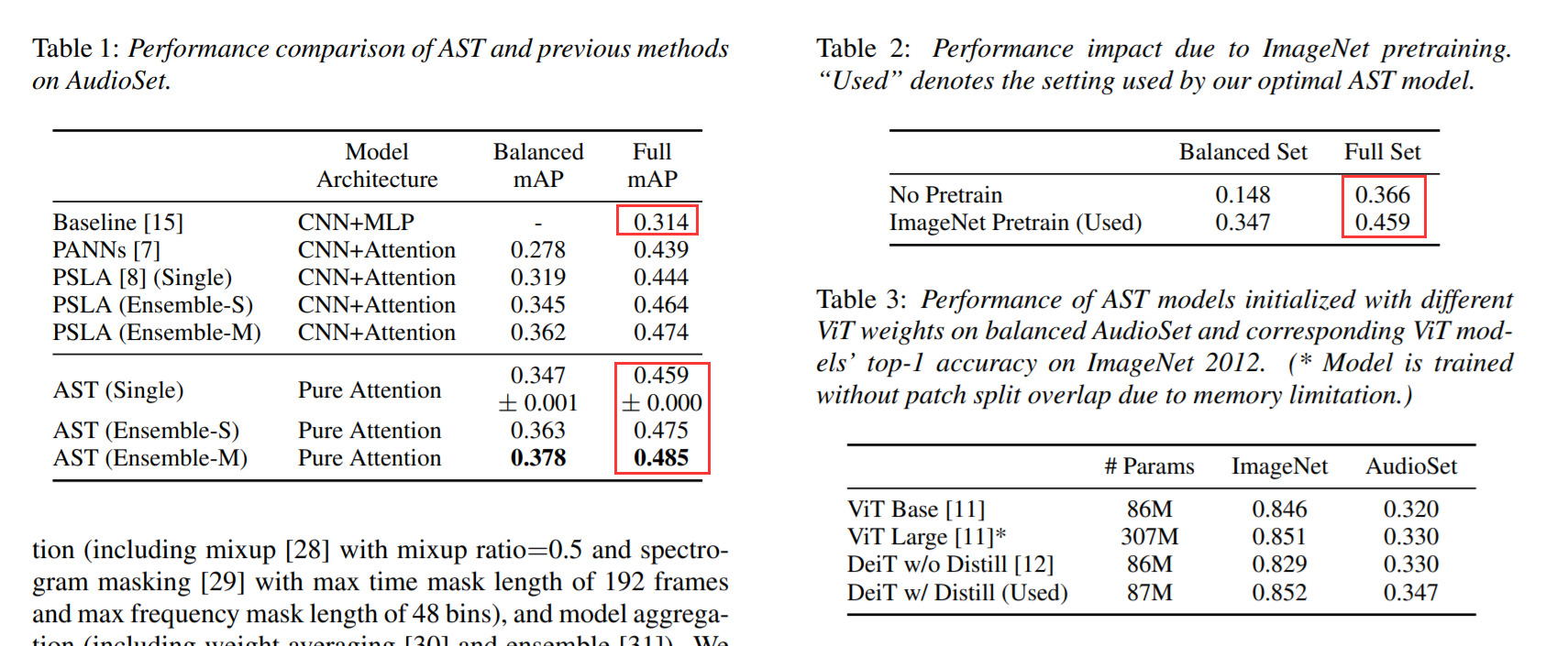

==