Capsule-based Object Tracking with Natural Language Specification
2021-12-18 19:28:39
Paper: https://dl.acm.org/doi/abs/10.1145/3474085.3475349
1. Background and Motivation:
本文提出一种 tracking-by-language 的算法,其中,visual encoder 用的是 Capsule network;然后将 text 和 img 交互。
2. Framework:
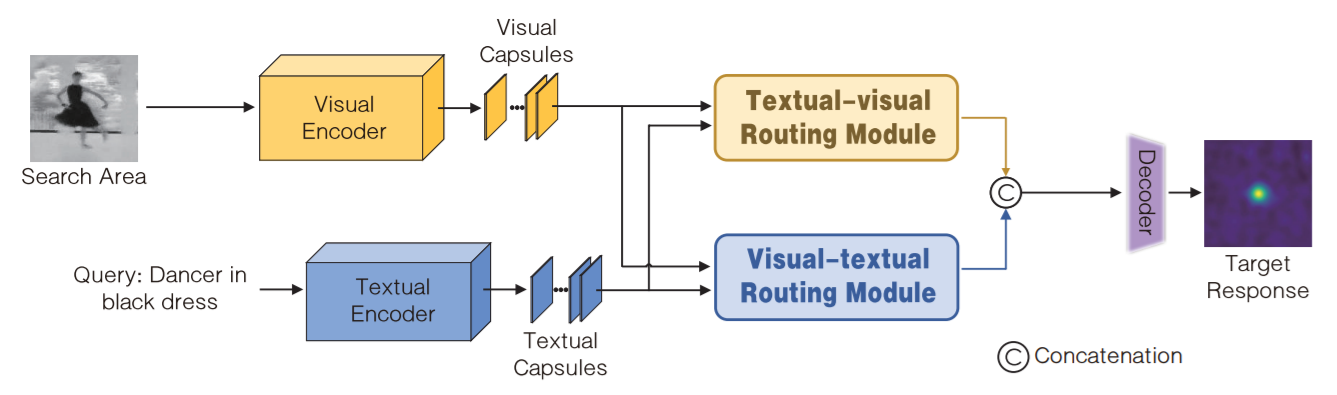
2.1. Visual and Textual Encoders
给定图像,作者利用 VGG 网络提取 conv4-3, conv5-3 的特征;给定文本,作者利用 word2vec model 将每一个单词映射为 300-D 的向量;然后将这些向量收集起来,并输入到 3个并行的卷积层中,卷积核的大小分别为 2, 3, 4。通过这种方式,尺寸为 300维的文本表示就可以通过 max-pooling layer 得到。给定视觉和文本特征,作者采用 matrix-capsule 的方法,进行 visual 和 texture capsule 的构建。 每一个 capsule 通过一个 pose matrix 和 activation value 进行构建。
2.2. Visual and Textual Capsules Construction
Pose matrix. 作者利用 1*1 卷积,将 36*36*128 的特征图映射为 36*36*64, 然后将得到的特征图进行 reshape,得到 36*36*8*8, 表示该矩阵由 8 个 8-D 的向量组成;
Activation Values. 利用 1*1 卷积将特征图映射为 36*36*8,以匹配胶囊类型的数目。通过增加一个维度,作者将其表达为 36*36*8*1.
Capsule Construction. 通过将这两个东西,组合到一起,得到一个 36*36*8*9 的特征。
由于文本特征是一个向量,作者直接用一个 FC 来产生 8 pose matrices 和 8 activations。
2.3. Visual-textural Routing Module
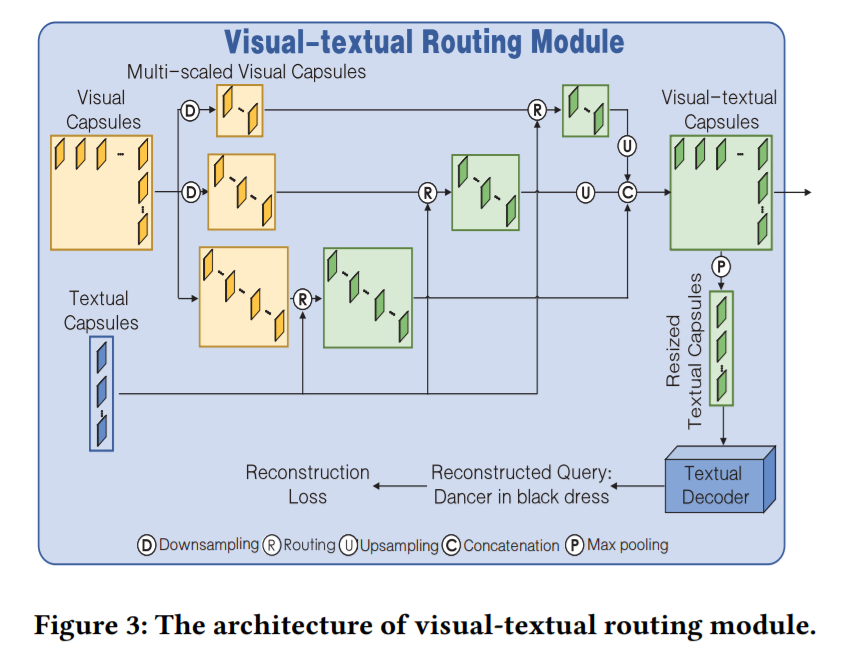
如上图所示,给定 visual capsule,作者考虑到多尺度的信息,将其分别与 textual capsule 进行路由交互,然后融合这三路特征,得到 visual-textual-capsules。然后对其进行 resize,输入到文本解码器中,进行文本的重构。
2.4. Textural-visual Routing Module
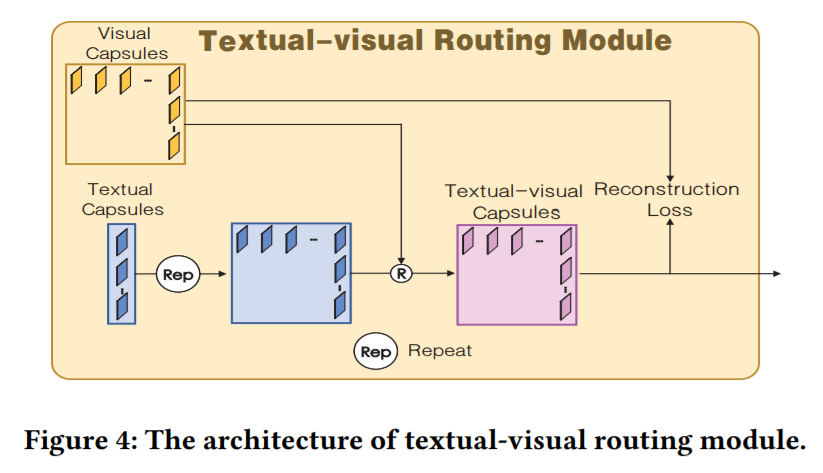
如上图所示,给定 visual 和 textual capsule,作者首先将文本的特征进行重复堆叠,得到和 visual capsule 相同维度的特征。然后进行路由交互,最终也进行重构。
2.5 Decoder
作者将上述两个分支的结果,进行拼接。然后将其进行 resize,然后利用反卷积网络得到 288*288*1 的响应图。这里,还用到了 parameterized skip connections 来得到更加精确的预测。
2.6 Optimization and Tracking
作者将上述两个重构损失和响应图损失一起进行优化。
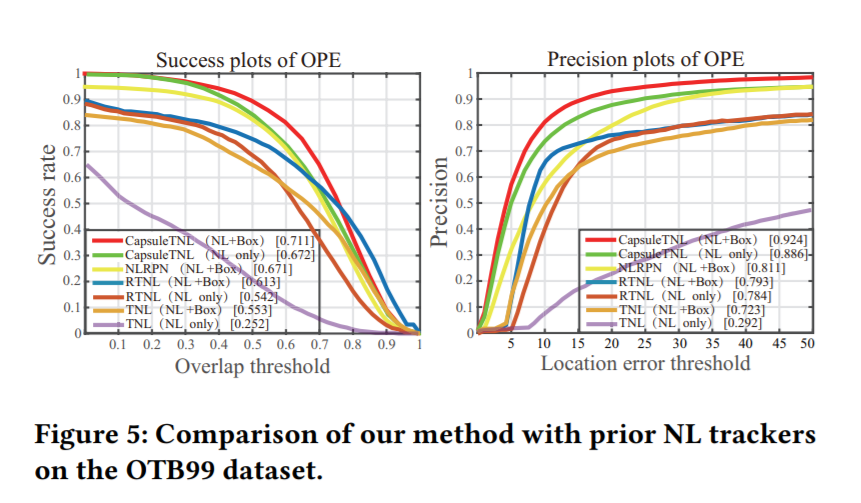
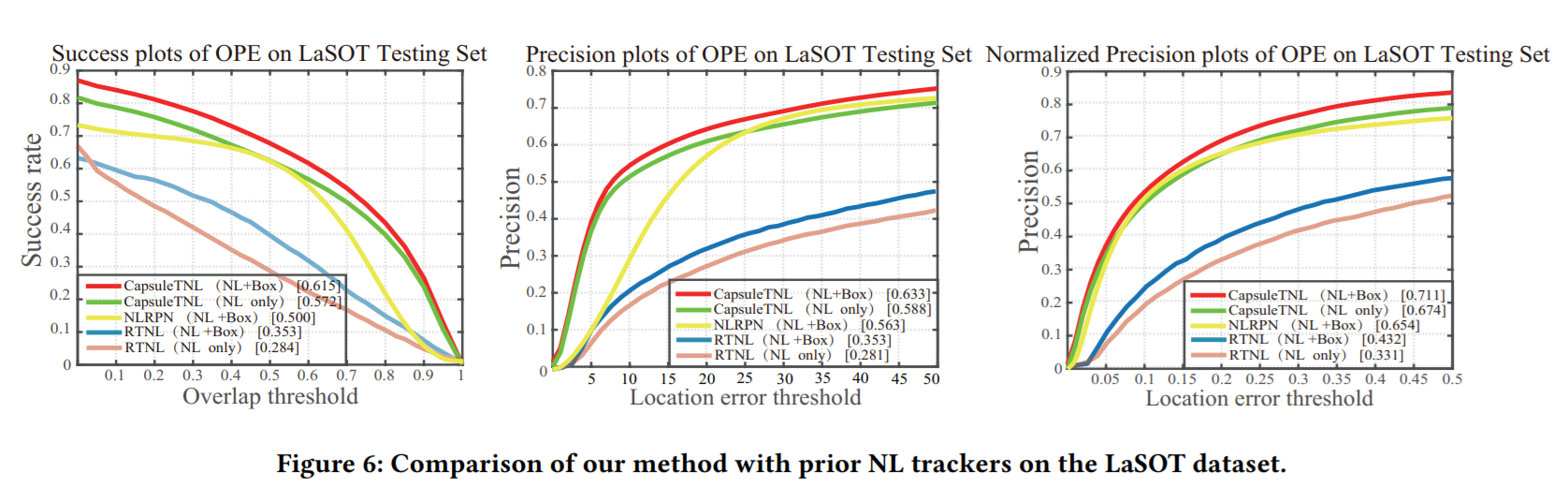
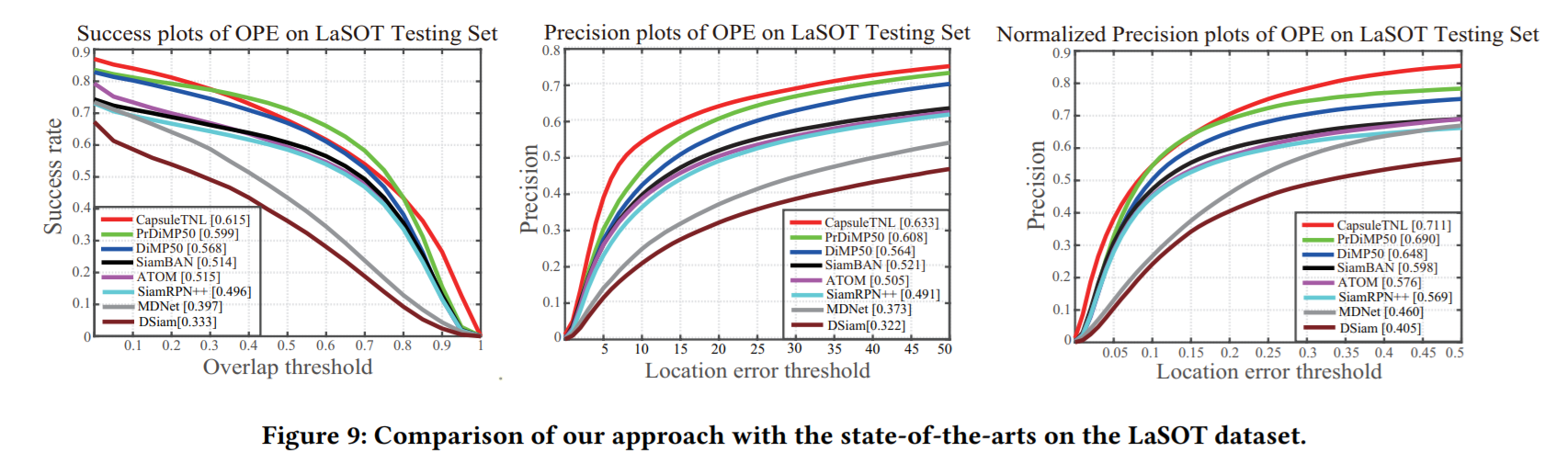
3. Experiments