Summary on deep learning framework --- Torch7
2018-07-22 21:30:28
1. 尝试第一个 CNN 的 torch版本, 代码如下:


1 -- We now have 5 steps left to do in training our first torch neural network
2 -- 1. Load and normalize data
3 -- 2. Define Neural Network
4 -- 3. Define Loss function
5 -- 4. Train network on training data
6 -- 5. Test network on test data.
7
8
9
10
11 -- 1. Load and normalize data
12 require 'paths'
13 require 'image';
14 if (not paths.filep("cifar10torchsmall.zip")) then
15 os.execute('wget -c https://s3.amazonaws.com/torch7/data/cifar10torchsmall.zip')
16 os.execute('unzip cifar10torchsmall.zip')
17 end
18 trainset = torch.load('cifar10-train.t7')
19 testset = torch.load('cifar10-test.t7')
20 classes = {'airplane', 'automobile', 'bird', 'cat',
21 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'}
22
23 print(trainset)
24 print(#trainset.data)
25
26 itorch.image(trainset.data[100]) -- display the 100-th image in dataset
27 print(classes[trainset.label[100]])
28
29 -- ignore setmetatable for now, it is a feature beyond the scope of this tutorial.
30 -- It sets the index operator
31 setmetatable(trainset,
32 {__index = function(t, i)
33 return {t.data[i], t.label[i]}
34 end}
35 );
36 trainset.data = trainset.data:double() -- convert the data from a ByteTensor to a DoubleTensor.
37
38 function trainset:size()
39 return self.data:size(1)
40 end
41
42 print(trainset:size())
43 print(trainset[33])
44 itorch.image(trainset[33][11])
45
46 redChannel = trainset.data[{ {}, {1}, {}, {} }] -- this pick {all images, 1st channel, all vertical pixels, all horizontal pixels}
47 print(#redChannel)
48
49 -- TODO:fill
50 mean = {}
51 stdv = {}
52 for i = 1,3 do
53 mean[i] = trainset.data[{ {}, {i}, {}, {} }]:mean() -- mean estimation
54 print('Channel ' .. i .. ' , Mean: ' .. mean[i])
55 trainset.data[{ {}, {i}, {}, {} }]:add(-mean[i]) -- mean subtraction
56
57 stdv[i] = trainset.data[ { {}, {i}, {}, {} }]:std() -- std estimation
58 print('Channel ' .. i .. ' , Standard Deviation: ' .. stdv[i])
59 trainset.data[{ {}, {i}, {}, {} }]:div(stdv[i]) -- std scaling
60 end
61
62
63
64 -- 2. Define Neural Network
65 net = nn.Sequential()
66 net:add(nn.SpatialConvolution(3, 6, 5, 5)) -- 3 input image channels, 6 output channels, 5x5 convolution kernel
67 net:add(nn.ReLU()) -- non-linearity
68 net:add(nn.SpatialMaxPooling(2,2,2,2)) -- A max-pooling operation that looks at 2x2 windows and finds the max.
69 net:add(nn.SpatialConvolution(6, 16, 5, 5))
70 net:add(nn.ReLU()) -- non-linearity
71 net:add(nn.SpatialMaxPooling(2,2,2,2))
72 net:add(nn.View(16*5*5)) -- reshapes from a 3D tensor of 16x5x5 into 1D tensor of 16*5*5
73 net:add(nn.Linear(16*5*5, 120)) -- fully connected layer (matrix multiplication between input and weights)
74 net:add(nn.ReLU()) -- non-linearity
75 net:add(nn.Linear(120, 84))
76 net:add(nn.ReLU()) -- non-linearity
77 net:add(nn.Linear(84, 10)) -- 10 is the number of outputs of the network (in this case, 10 digits)
78 net:add(nn.LogSoftMax()) -- converts the output to a log-probability. Useful for classification problems
79
80
81 -- 3. Let us difine the Loss function
82 criterion = nn.ClassNLLCriterion()
83
84
85
86 -- 4. Train the neural network
87 trainer = nn.StochasticGradient(net, criterion)
88 trainer.learningRate = 0.001
89 trainer.maxIteration = 5 -- just do 5 epochs of training.
90 trainer:train(trainset)
91
92
93
94 -- 5. Test the network, print accuracy
95 print(classes[testset.label[100]])
96 itorch.image(testset.data[100])
97
98 testset.data = testset.data:double() -- convert from Byte tensor to Double tensor
99 for i=1,3 do -- over each image channel
100 testset.data[{ {}, {i}, {}, {} }]:add(-mean[i]) -- mean subtraction
101 testset.data[{ {}, {i}, {}, {} }]:div(stdv[i]) -- std scaling
102 end
103
104 -- for fun, print the mean and standard-deviation of example-100
105 horse = testset.data[100]
106 print(horse:mean(), horse:std())
107
108 print(classes[testset.label[100]])
109 itorch.image(testset.data[100])
110 predicted = net:forward(testset.data[100])
111
112 -- the output of the network is Log-Probabilities. To convert them to probabilities, you have to take e^x
113 print(predicted:exp())
114
115
116 for i=1,predicted:size(1) do
117 print(classes[i], predicted[i])
118 end
119
120
121 -- test the accuracy
122 correct = 0
123 for i=1,10000 do
124 local groundtruth = testset.label[i]
125 local prediction = net:forward(testset.data[i])
126 local confidences, indices = torch.sort(prediction, true) -- true means sort in descending order
127 if groundtruth == indices[1] then
128 correct = correct + 1
129 end
130 end
131
132
133 print(correct, 100*correct/10000 .. ' % ')
134
135 class_performance = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0}
136 for i=1,10000 do
137 local groundtruth = testset.label[i]
138 local prediction = net:forward(testset.data[i])
139 local confidences, indices = torch.sort(prediction, true) -- true means sort in descending order
140 if groundtruth == indices[1] then
141 class_performance[groundtruth] = class_performance[groundtruth] + 1
142 end
143 end
144
145
146 for i=1,#classes do
147 print(classes[i], 100*class_performance[i]/1000 .. ' %')
148 end
149
150 require 'cunn';
151 net = net:cuda()
152 criterion = criterion:cuda()
153 trainset.data = trainset.data:cuda()
154 trainset.label = trainset.label:cuda()
155
156 trainer = nn.StochasticGradient(net, criterion)
157 trainer.learningRate = 0.001
158 trainer.maxIteration = 5 -- just do 5 epochs of training.
159
160
161 trainer:train(trainset)
那么,运行起来 却出现如下的问题:
(1).
/home/wangxiao/torch/install/bin/luajit: ./train_network.lua:26: attempt to index global 'itorch' (a nil value)
stack traceback:
./train_network.lua:26: in main chunk
[C]: in function 'dofile'
...xiao/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:145: in main chunk
[C]: at 0x00406670
wangxiao@AHU:~/Documents/Lua test examples$
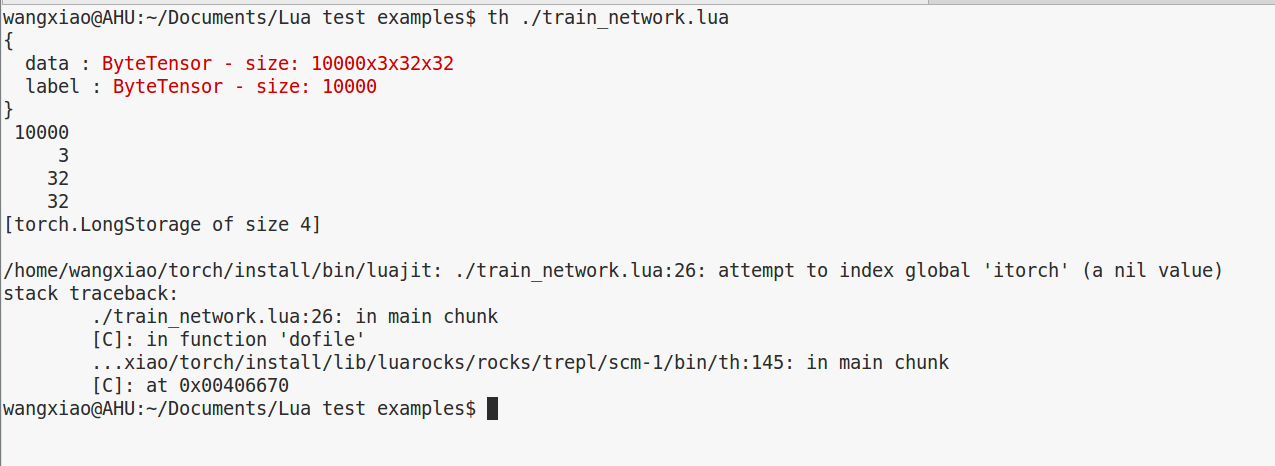
主要是 itorch 的问题, 另外就是 要引用 require 'nn' 来解决 无法辨别 nn 的问题.
我是把 带有 itorch 的那些行都暂时注释了.
2. 'libcudnn (R5) not found in library path.
wangxiao@AHU:~/Downloads/wide-residual-networks-master$ th ./train_Single_Multilabel_Image_Classification.lua
nil
/home/wangxiao/torch/install/bin/luajit: /home/wangxiao/torch/install/share/lua/5.1/trepl/init.lua:384: /home/wangxiao/torch/install/share/lua/5.1/trepl/init.lua:384: /home/wangxiao/torch/install/share/lua/5.1/cudnn/ffi.lua:1600: 'libcudnn (R5) not found in library path.
Please install CuDNN from https://developer.nvidia.com/cuDNN
Then make sure files named as libcudnn.so.5 or libcudnn.5.dylib are placed in your library load path (for example /usr/local/lib , or manually add a path to LD_LIBRARY_PATH)
stack traceback:
[C]: in function 'error'
/home/wangxiao/torch/install/share/lua/5.1/trepl/init.lua:384: in function 'require'
./train_Single_Multilabel_Image_Classification.lua:8: in main chunk
[C]: in function 'dofile'
...xiao/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:145: in main chunk
[C]: at 0x00406670
wangxiao@AHU:~/Downloads/wide-residual-networks-master$
================================================================>>
答案是:
重新下载了 cudnn-7.5-linux-x64-v5.0-ga.tgz
并且重新配置了,但是依然提醒这个问题,那么,问题何在呢?查看了博客:http://blog.csdn.net/hungryof/article/details/51557666 中的内容:
坑4 可能出现’libcudnn not found in library path’的情况
截取其中一段错误信息:
Please install CuDNN from https://developer.nvidia.com/cuDNN
Then make sure files named as libcudnn.so.5 or libcudnn.5.dylib are placed in your library load path (for example /usr/local/lib , or manually add a path to LD_LIBRARY_PATH)- 1
- 2
LD_LIBRARY_PATH是该环境变量,主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径。由于刚才已经将
“libcudnn*”复制到了/usr/local/cuda-7.5/lib64/下面,因此需要
- sudo gedit /etc/ld.so.conf.d/cudnn.conf 就是新建一个conf文件。名字随便
- 加入刚才的路径/usr/local/cuda-7.5/lib64/
- 反正我还添加了/usr/local/cuda-7.5/include/,这个估计不要也行。
- 保存后,再sudo ldconfig来更新缓存。(可能会出现libcudnn.so.5不是符号连接的问题,不过无所谓了!!)
此时运行
th neural_style.lua -gpu 0 -backend cudnn- 1
成功了!!!!
============================================================>>>>
评价: 按照这种做法试了,确实成功了! 赞一个 !!!
3. 利用 gm 加载图像时,提示错误,但是装上那个包仍然提示错误:

Load library:
gm = require 'graphicsmagick'
First, we provide two high-level functions to load/save directly into/form tensors:
img = gm.load('/path/to/image.png' [, type]) -- type = 'float' (default) | 'double' | 'byte'
gm.save('/path/to/image.jpg' [,quality]) -- quality = 0 to 100 (for jpegs only)
The following provide a more controlled flow for loading/saving jpegs.
Create an image, from a file:
image = gm.Image('/path/to/image.png')
-- or
image = gm.Image()
image:load('/path/to/image.png')
但是悲剧的仍然有错, 只好换了用 image.load() 的方式加载图像:
--To load as byte tensor for rgb imagefile
local img = image.load(imagefile,3,'byte')
4. Torch 保存 txt 文件:
-- save opt
file = torch.DiskFile(paths.concat(opt.checkpoints_dir, opt.name, 'opt.txt'), 'w')
file:writeObject(opt)
file:close()
5. Torch 创建新的文件夹
opts.modelPath = opt.modelDir .. opt.modelName
if not paths.dirp(opt.modelPath) then
paths.mkdir(opts.modelPath)
end
6. Torch Lua 保存 图像到文件夹
借助 image package,首先安装: luarocks install image
然后 require 'image'
就可以使用了: local img = image.save('./saved_pos_neg_image/candidate_' .. tostring(i) .. tostring(j) .. '.png', pos_patch, 1, 32, 32)
7. module 'bit' not found:No LuaRocks module found for bit
wangxiao@AHU:/media/wangxiao/724eaeef-e688-4b09-9cc9-dfaca44079b2/fast-neural-style-master$ th ./train.lua
/home/wangxiao/torch/install/bin/lua: /home/wangxiao/torch/install/share/lua/5.2/trepl/init.lua:389: /home/wangxiao/torch/install/share/lua/5.2/trepl/init.lua:389: /home/wangxiao/torch/install/share/lua/5.2/trepl/init.lua:389: module 'bit' not found:No LuaRocks module found for bit
no field package.preload['bit']
no file '/home/wangxiao/.luarocks/share/lua/5.2/bit.lua'
no file '/home/wangxiao/.luarocks/share/lua/5.2/bit/init.lua'
no file '/home/wangxiao/torch/install/share/lua/5.2/bit.lua'
no file '/home/wangxiao/torch/install/share/lua/5.2/bit/init.lua'
no file '/home/wangxiao/.luarocks/share/lua/5.1/bit.lua'
no file '/home/wangxiao/.luarocks/share/lua/5.1/bit/init.lua'
no file '/home/wangxiao/torch/install/share/lua/5.1/bit.lua'
no file '/home/wangxiao/torch/install/share/lua/5.1/bit/init.lua'
no file './bit.lua'
no file '/home/wangxiao/torch/install/share/luajit-2.1.0-beta1/bit.lua'
no file '/usr/local/share/lua/5.1/bit.lua'
no file '/usr/local/share/lua/5.1/bit/init.lua'
no file '/home/wangxiao/.luarocks/lib/lua/5.2/bit.so'
no file '/home/wangxiao/torch/install/lib/lua/5.2/bit.so'
no file '/home/wangxiao/torch/install/lib/bit.so'
no file '/home/wangxiao/.luarocks/lib/lua/5.1/bit.so'
no file '/home/wangxiao/torch/install/lib/lua/5.1/bit.so'
no file './bit.so'
no file '/usr/local/lib/lua/5.1/bit.so'
no file '/usr/local/lib/lua/5.1/loadall.so'
stack traceback:
[C]: in function 'error'
/home/wangxiao/torch/install/share/lua/5.2/trepl/init.lua:389: in function 'require'
./train.lua:5: in main chunk
[C]: in function 'dofile'
...xiao/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:145: in main chunk
[C]: in ?
wangxiao@AHU:/media/wangxiao/724eaeef-e688-4b09-9cc9-dfaca44079b2/fast-neural-style-master$
在终端中执行:luarocks install luabitop
就可以了。
8. HDF5Group:read() - no such child 'media' for [HDF5Group 33554432 /]
/home/wangxiao/torch/install/bin/lua: /home/wangxiao/torch/install/share/lua/5.2/hdf5/group.lua:312: HDF5Group:read() - no such child 'media' for [HDF5Group 33554432 /]
stack traceback:
[C]: in function 'error'
/home/wangxiao/torch/install/share/lua/5.2/hdf5/group.lua:312: in function </home/wangxiao/torch/install/share/lua/5.2/hdf5/group.lua:302>
(...tail calls...)
./fast_neural_style/DataLoader.lua:44: in function '__init'
/home/wangxiao/torch/install/share/lua/5.2/torch/init.lua:91: in function </home/wangxiao/torch/install/share/lua/5.2/torch/init.lua:87>
[C]: in function 'DataLoader'
./train.lua:138: in function 'main'
./train.lua:327: in main chunk
[C]: in function 'dofile'
...xiao/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:145: in main chunk
[C]: in ?
最近在训练 类型迁移的代码,发现这个蛋疼的问题。哎。。纠结好几天了。。这个 hdf5 到底怎么回事 ? 求解释 !!!
------------------------------------------------------------------------------------------------
后来发现, 是我自己的数据集路径设置的有问题, 如: 应该是 CoCo/train/image/
但是,我只是给定了 CoCo/train/ ...
9. 怎么设置 torch代码在哪块 GPU 上运行 ? 或者 怎么设置在两块卡上同时运行 ?

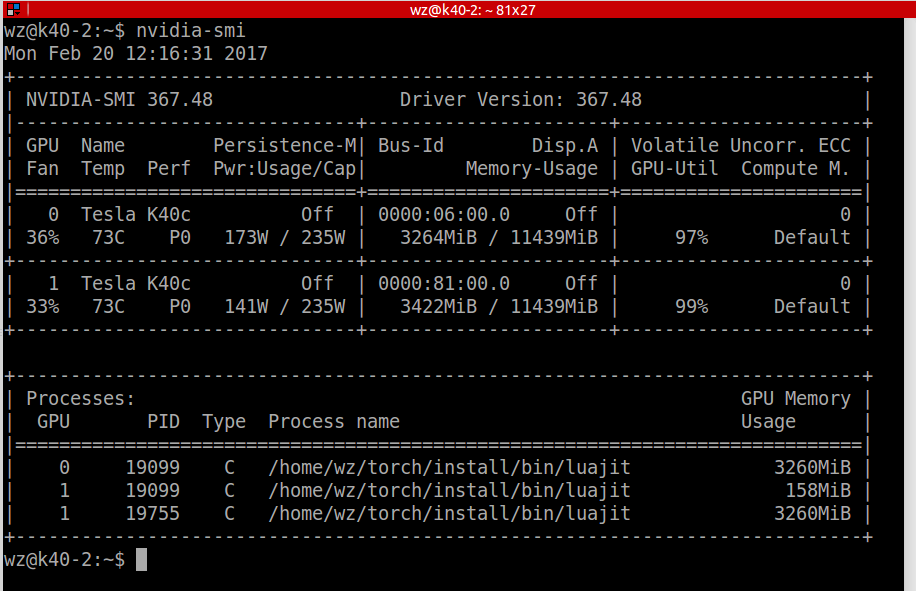
如图所示: export CUDA_VISIBLE_DEVICES=0 即可指定代码在 GPU-0 上运行.
10. When load the pre-trained VGG model, got the following errors:
MODULE data UNDEFINED
warning: module 'data [type 5]' not found
nn supports no groups!
warning: module 'conv2 [type 4]' not found
nn supports no groups!
warning: module 'conv4 [type 4]' not found
nn supports no groups!
warning: module 'conv5 [type 4]' not found
1 using cudnn
2 Successfully loaded ./feature_transfer/AlexNet_files/bvlc_alexnet.caffemodel
3 MODULE data UNDEFINED
4 warning: module 'data [type 5]' not found
5 nn supports no groups!
6 warning: module 'conv2 [type 4]' not found
7 nn supports no groups!
8 warning: module 'conv4 [type 4]' not found
9 nn supports no groups!
10 warning: module 'conv5 [type 4]' not found
1 wangxiao@AHU:~/Downloads/multi-modal-visual-tracking$ qlua ./train_match_function_alexNet_version_2017_02_28.lua
2 using cudnn
3 Successfully loaded ./feature_transfer/AlexNet_files/bvlc_alexnet.caffemodel
4 MODULE data UNDEFINED
5 warning: module 'data [type 5]' not found
6 nn supports no groups!
7 warning: module 'conv2 [type 4]' not found
8 nn supports no groups!
9 warning: module 'conv4 [type 4]' not found
10 nn supports no groups!
11 warning: module 'conv5 [type 4]' not found
12 conv1: 96 3 11 11
13 conv3: 384 256 3 3
14 fc6: 1 1 9216 4096
15 fc7: 1 1 4096 4096
16 fc8: 1 1 4096 1000
17 nn.Sequential {
18 [input -> (1) -> (2) -> (3) -> output]
19 (1): nn.SplitTable
20 (2): nn.ParallelTable {
21 input
22 |`-> (1): nn.Sequential {
23 | [input -> (1) -> (2) -> (3) -> (4) -> (5) -> (6) -> (7) -> (8) -> (9) -> (10) -> (11) -> (12) -> (13) -> (14) -> (15) -> (16) -> (17) -> (18) -> output]
24 | (1): nn.SpatialConvolution(3 -> 96, 11x11, 4,4)
25 | (2): nn.ReLU
26 | (3): nn.SpatialCrossMapLRN
27 | (4): nn.SpatialMaxPooling(3x3, 2,2)
28 | (5): nn.ReLU
29 | (6): nn.SpatialCrossMapLRN
30 | (7): nn.SpatialMaxPooling(3x3, 2,2)
31 | (8): nn.SpatialConvolution(256 -> 384, 3x3, 1,1, 1,1)
32 | (9): nn.ReLU
33 | (10): nn.ReLU
34 | (11): nn.ReLU
35 | (12): nn.SpatialMaxPooling(3x3, 2,2)
36 | (13): nn.View(-1)
37 | (14): nn.Linear(9216 -> 4096)
38 | (15): nn.ReLU
39 | (16): nn.Dropout(0.500000)
40 | (17): nn.Linear(4096 -> 4096)
41 | (18): nn.ReLU
42 | }
43 `-> (2): nn.Sequential {
44 [input -> (1) -> (2) -> (3) -> (4) -> (5) -> (6) -> (7) -> (8) -> (9) -> (10) -> (11) -> (12) -> (13) -> (14) -> (15) -> (16) -> (17) -> (18) -> output]
45 (1): nn.SpatialConvolution(3 -> 96, 11x11, 4,4)
46 (2): nn.ReLU
47 (3): nn.SpatialCrossMapLRN
48 (4): nn.SpatialMaxPooling(3x3, 2,2)
49 (5): nn.ReLU
50 (6): nn.SpatialCrossMapLRN
51 (7): nn.SpatialMaxPooling(3x3, 2,2)
52 (8): nn.SpatialConvolution(256 -> 384, 3x3, 1,1, 1,1)
53 (9): nn.ReLU
54 (10): nn.ReLU
55 (11): nn.ReLU
56 (12): nn.SpatialMaxPooling(3x3, 2,2)
57 (13): nn.View(-1)
58 (14): nn.Linear(9216 -> 4096)
59 (15): nn.ReLU
60 (16): nn.Dropout(0.500000)
61 (17): nn.Linear(4096 -> 4096)
62 (18): nn.ReLU
63 }
64 ... -> output
65 }
66 (3): nn.PairwiseDistance
67 }
68 =================================================================================================================
69 ================= AlextNet based Siamese Search for Visual Tracking ========================
70 =================================================================================================================
71 ==>> The Benchmark Contain: 36 videos ...
72 deal with video 1/36 video name: BlurFace ... please waiting ...
73 the num of gt bbox: 493
74 the num of video frames: 493
75 ========>>>> Begin to track 2 video name: nil-th frame, please waiting ...
76 ========>>>> Begin to track 3 video name: nil-th frame, please waiting ... ............] ETA: 0ms | Step: 0ms
77 ========>>>> Begin to track 4 video name: nil-th frame, please waiting ... ............] ETA: 39s424ms | Step: 80ms
78 ========>>>> Begin to track 5 video name: nil-th frame, please waiting ... ............] ETA: 33s746ms | Step: 69ms
79 ========>>>> Begin to track 6 video name: nil-th frame, please waiting ... ............] ETA: 31s817ms | Step: 65ms
80 ========>>>> Begin to track 7 video name: nil-th frame, please waiting ... ............] ETA: 32s575ms | Step: 66ms
81 ========>>>> Begin to track 8 video name: nil-th frame, please waiting ... ............] ETA: 34s376ms | Step: 70ms
82 ========>>>> Begin to track 9 video name: nil-th frame, please waiting ... ............] ETA: 40s240ms | Step: 82ms
83 ========>>>> Begin to track 10 video name: nil-th frame, please waiting ... ...........] ETA: 44s211ms | Step: 91ms
84 ========>>>> Begin to track 11 video name: nil-th frame, please waiting ... ...........] ETA: 45s993ms | Step: 95ms
85 ========>>>> Begin to track 12 video name: nil-th frame, please waiting ... ...........] ETA: 47s754ms | Step: 99ms
86 ========>>>> Begin to track 13 video name: nil-th frame, please waiting ... ...........] ETA: 50s392ms | Step: 104ms
87 ========>>>> Begin to track 14 video name: nil-th frame, please waiting ... ...........] ETA: 53s138ms | Step: 110ms
88 ========>>>> Begin to track 15 video name: nil-th frame, please waiting ... ...........] ETA: 55s793ms | Step: 116ms
89 ========>>>> Begin to track 16 video name: nil-th frame, please waiting ... ...........] ETA: 59s253ms | Step: 123ms
90 ========>>>> Begin to track 17 video name: nil-th frame, please waiting ... ...........] ETA: 1m2s | Step: 130ms
91 ========>>>> Begin to track 18 video name: nil-th frame, please waiting ... ...........] ETA: 1m5s | Step: 137ms
92 ========>>>> Begin to track 19 video name: nil-th frame, please waiting ... ...........] ETA: 1m8s | Step: 143ms
93 ========>>>> Begin to track 20 video name: nil-th frame, please waiting ... ...........] ETA: 1m11s | Step: 149ms
94 //////////////////////////////////////////////////////////////////////////..............] ETA: 1m14s | Step: 157ms
95 ==>> pos_proposal_list: 19
96 ==>> neg_proposal_list: 19
97 qlua: /home/wangxiao/torch/install/share/lua/5.1/nn/Container.lua:67:
98 In 2 module of nn.Sequential:
99 In 1 module of nn.ParallelTable:
100 In 8 module of nn.Sequential:
101 /home/wangxiao/torch/install/share/lua/5.1/nn/THNN.lua:117: Need input of dimension 3 and input.size[0] == 256 but got input to be of shape: [96 x 13 x 13] at /tmp/luarocks_cunn-scm-1-6210/cunn/lib/THCUNN/generic/SpatialConvolutionMM.cu:49
102 stack traceback:
103 [C]: in function 'v'
104 /home/wangxiao/torch/install/share/lua/5.1/nn/THNN.lua:117: in function 'SpatialConvolutionMM_updateOutput'
105 ...ao/torch/install/share/lua/5.1/nn/SpatialConvolution.lua:79: in function <...ao/torch/install/share/lua/5.1/nn/SpatialConvolution.lua:76>
106 [C]: in function 'xpcall'
107 /home/wangxiao/torch/install/share/lua/5.1/nn/Container.lua:63: in function 'rethrowErrors'
108 ...e/wangxiao/torch/install/share/lua/5.1/nn/Sequential.lua:44: in function <...e/wangxiao/torch/install/share/lua/5.1/nn/Sequential.lua:41>
109 [C]: in function 'xpcall'
110 /home/wangxiao/torch/install/share/lua/5.1/nn/Container.lua:63: in function 'rethrowErrors'
111 ...angxiao/torch/install/share/lua/5.1/nn/ParallelTable.lua:12: in function <...angxiao/torch/install/share/lua/5.1/nn/ParallelTable.lua:10>
112 [C]: in function 'xpcall'
113 /home/wangxiao/torch/install/share/lua/5.1/nn/Container.lua:63: in function 'rethrowErrors'
114 ...e/wangxiao/torch/install/share/lua/5.1/nn/Sequential.lua:44: in function 'forward'
115 ./train_match_function_alexNet_version_2017_02_28.lua:525: in function 'opfunc'
116 /home/wangxiao/torch/install/share/lua/5.1/optim/adam.lua:37: in function 'optim'
117 ./train_match_function_alexNet_version_2017_02_28.lua:550: in main chunk
118
119
120
121 WARNING: If you see a stack trace below, it doesn't point to the place where this error occurred. Please use only the one above.
122 stack traceback:
123 [C]: at 0x7f86014df9c0
124 [C]: in function 'error'
125 /home/wangxiao/torch/install/share/lua/5.1/nn/Container.lua:67: in function 'rethrowErrors'
126 ...e/wangxiao/torch/install/share/lua/5.1/nn/Sequential.lua:44: in function 'forward'
127 ./train_match_function_alexNet_version_2017_02_28.lua:525: in function 'opfunc'
128 /home/wangxiao/torch/install/share/lua/5.1/optim/adam.lua:37: in function 'optim'
129 ./train_match_function_alexNet_version_2017_02_28.lua:550: in main chunk
130 wangxiao@AHU:~/Downloads/multi-modal-visual-tracking$

Just like the screen shot above, change the 'nn' into 'cudnn' will be ok and passed.
11. both (null) and torch.FloatTensor have no less-than operator
qlua: ./test_MM_tracker_VGG_.lua:254: both (null) and torch.FloatTensor have no less-than operator
stack traceback:
[C]: at 0x7f628816e9c0
[C]: in function '__lt'
./test_MM_tracker_VGG_.lua:254: in main chunk
Because it is floatTensor () style and you can change it like this if you want this value printed in a for loop: predictValue -->> predictValue[i] .
12.
========>>>> Begin to track the 6-th and the video name is ILSVRC2015_train_00109004 , please waiting ...
THCudaCheck FAIL file=/tmp/luarocks_cutorch-scm-1-707/cutorch/lib/THC/generic/THCStorage.cu line=66 error=2 : out of memory
qlua: cuda runtime error (2) : out of memory at /tmp/luarocks_cutorch-scm-1-707/cutorch/lib/THC/generic/THCStorage.cu:66
stack traceback:
[C]: at 0x7fa20a8f99c0
[C]: at 0x7fa1dddfbee0
[C]: in function 'Tensor'
./train_match_function_VGG_version_2017_03_02.lua:377: in main chunk
wangxiao@AHU:~/Downloads/multi-modal-visual-tracking$
Yes, it is just out of memory of GPU. Just turn the batchsize to a small value, it may work. It worked for me. Ha ha ...
13. luarocks install class does not have any effect, it still shown me the error: No Module named "class" in Torch.
==>> in terminal, install this package in sudo.
==>> then, it will be OK.
14. How to install opencv 3.1 on Ubuntu 14.04 ???
As we can found from: http://blog.csdn.net/a125930123/article/details/52091140
1. first, you should install torch successfully ;
2. then, just follow what the blog said here:
安装opencv3.1
1、安装必要的包
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
2、下载opencv3.1
http://opencv.org/downloads.html
解压:unzip opencv-3.1.0
3、安装
cd ~/opencv-3.1.0
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
sudo make -j24
sudo make install -j24
sudo /bin/bash -c 'echo "/usr/local/lib" > /etc/ld.so.conf.d/opencv.conf'
sudo ldconfig
安装完成
4、问题在安装过程中可能会出现无法下载 ippicv_linux_20151201.tgz的问题。解决方案:
手动下载ippicv_linux_20151201.tgz:https://raw.githubusercontent.com/Itseez/opencv_3rdparty/81a676001ca8075ada498583e4166079e5744668/ippicv/ippicv_linux_20151201.tgz将下载好的文件 放入 opencv-3.1.0/3rdparty/ippicv/downloads/linux-808b791a6eac9ed78d32a7666804320e 中,如果已经存在 ,则替换掉,这样就可以安装完成了。
5、最后执行命令
luarocks install cv
OpenCV bindings for Torch安装成功。
But, maybe you may found some errors, such as:
cudalegacy/src/graphcuts.cpp:120:54: error: ‘NppiGraphcutState’ has not been declared (solution draw from: http://blog.csdn.net/allyli0022/article/details/62859290)
At this moment, you need to change some files:
found graphcuts.cpp in opencv3.1, and do the following changes:
解决方案:需要修改一处源码:
在graphcuts.cpp中将#if !defined (HAVE_CUDA) || defined (CUDA_DISABLER) 改为#if !defined (HAVE_CUDA) || defined (CUDA_DISABLER) || (CUDART_VERSION >= 8000)
then, try again, it will be ok...this code just want to make opencv3.1 work under cuda 8.0, you know...skip that judge sentence...
15. 安装torch-hdf5
sudo apt-get install libhdf5-serial-dev hdf5-tools
git clone https://github.com/deepmind/torch-hdf5
cd torch-hdf5
sudo luarocks make hdf5-0-0.rockspec LIBHDF5_LIBDIR=”/usr/lib/x86_64-Linux-gnu/”
17. iTorch安装
git clone https://github.com/zeromq/zeromq4-1.git
mkdir build-zeromq
cd build-zeromq
cmake ..
make && make install
安装完之后,luarocks install itorch
之后可以通过luarocks list查看是否安装成功