要求:实现任意层数的NN。
每一层结构包含:


1、前向传播和反向传播函数;2、每一层计算的相关数值
cell 1 依旧是显示的初始设置
1 # As usual, a bit of setup 2 3 import time 4 import numpy as np 5 import matplotlib.pyplot as plt 6 from cs231n.classifiers.fc_net import * 7 from cs231n.data_utils import get_CIFAR10_data 8 from cs231n.gradient_check import eval_numerical_gradient, eval_numerical_gradient_array 9 from cs231n.solver import Solver 10 11 %matplotlib inline 12 plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots 13 plt.rcParams['image.interpolation'] = 'nearest' 14 plt.rcParams['image.cmap'] = 'gray' 15 16 # for auto-reloading external modules 17 # see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython 18 %load_ext autoreload 19 %autoreload 2 20 21 def rel_error(x, y): 22 """ returns relative error """ 23 return np.max(np.abs(x - y) / (np.maximum(1e-8, np.abs(x) + np.abs(y))))
cell 2 读取cifar数据,并显示维度信息
1 # Load the (preprocessed) CIFAR10 data. 2 3 data = get_CIFAR10_data() 4 for k, v in data.iteritems(): 5 print '%s: ' % k, v.shape
cell 3 使用随机生成的数据,测试affine 前向传播函数
1 # Test the affine_forward function 2 3 num_inputs = 2 4 input_shape = (4, 5, 6) 5 output_dim = 3 6 7 input_size = num_inputs * np.prod(input_shape) 8 # input_size 240 9 weight_size = output_dim * np.prod(input_shape) 10 # iweight_size 360 11 x = np.linspace(-0.1, 0.5, num=input_size).reshape(num_inputs, *input_shape) 12 #(2,4,5,6) -1->0.5 13 w = np.linspace(-0.2, 0.3, num=weight_size).reshape(np.prod(input_shape), output_dim) 14 #(120, 3) -0.2->0.3 15 b = np.linspace(-0.3, 0.1, num=output_dim) 16 #(3,) 0.3->0.1 17 #2 num_inputs 120 input_shape 2*120 * 120*3 >>2*3 18 out, _ = affine_forward(x, w, b) 19 correct_out = np.array([[ 1.49834967, 1.70660132, 1.91485297], 20 [ 3.25553199, 3.5141327, 3.77273342]]) 21 22 # Compare your output with ours. The error should be around 1e-9. 23 print 'Testing affine_forward function:' 24 print 'difference: ', rel_error(out, correct_out)
结果:
 affine_forward(x, w, b)函数内容
affine_forward(x, w, b)函数内容
1 def affine_forward(x, w, b): 2 """ 3 Computes the forward pass for an affine (fully-connected) layer. 4 5 The input x has shape (N, d_1, ..., d_k) and contains a minibatch of N 6 examples, where each example x[i] has shape (d_1, ..., d_k). We will 7 reshape each input into a vector of dimension D = d_1 * ... * d_k, and 8 then transform it to an output vector of dimension M. 9 10 Inputs: 11 - x: A numpy array containing input data, of shape (N, d_1, ..., d_k) 12 - w: A numpy array of weights, of shape (D, M) 13 - b: A numpy array of biases, of shape (M,) 14 15 Returns a tuple of: 16 - out: output, of shape (N, M) 17 - cache: (x, w, b) 18 """ 19 out = None 20 ############################################################################# 21 # TODO: Implement the affine forward pass. Store the result in out. You # 22 # will need to reshape the input into rows. # 23 ############################################################################# 24 N = x.shape[0] 25 D = x.size / N 26 x = x.reshape(N, D) 27 #2 num_inputs 120 input_shape 2*120 * 120*3 >>2*3 28 out = np.dot(x,w) + b 29 ############################################################################# 30 # END OF YOUR CODE # 31 ############################################################################# 32 cache = (x, w, b) 33 return out, cache
cell 4 反向传播,计算梯度是否正确
1 # Test the affine_backward function 2 3 x = np.random.randn(10, 2, 3) 4 w = np.random.randn(6, 5) 5 b = np.random.randn(5) 6 dout = np.random.randn(10, 5) 7 #x (10,2,3) w (6,5) b 5 dout (10,5) 8 dx_num = eval_numerical_gradient_array(lambda x: affine_forward(x, w, b)[0], x, dout) 9 dw_num = eval_numerical_gradient_array(lambda w: affine_forward(x, w, b)[0], w, dout) 10 db_num = eval_numerical_gradient_array(lambda b: affine_forward(x, w, b)[0], b, dout) 11 _, cache = affine_forward(x, w, b) 12 #g = lambda i : range(i) 13 #print g(len(cache)) 14 #for i in range (len(cache)): 15 # print cache[i].shape 16 #(10, 6) 17 #(6, 5) 18 #(5,) 19 dx, dw, db = affine_backward(dout, cache) 20 print dx.shape 21 dx = dx.reshape(10, 2, 3) 22 # The error should be around 1e-10 23 print 'Testing affine_backward function:' 24 print 'dx error: ', rel_error(dx_num, dx) 25 print 'dw error: ', rel_error(dw_num, dw) 26 print 'db error: ', rel_error(db_num, db)
结果:

affine_backward(dout, cache)内容:
1 def affine_backward(dout, cache): 2 """ 3 Computes the backward pass for an affine layer. 4 5 Inputs: 6 - dout: Upstream derivative, of shape (N, M) 7 - cache: Tuple of: 8 - x: Input data, of shape (N, d_1, ... d_k) 9 - w: Weights, of shape (D, M) 10 11 Returns a tuple of: 12 - dx: Gradient with respect to x, of shape (N, d1, ..., d_k) 13 - dw: Gradient with respect to w, of shape (D, M) 14 - db: Gradient with respect to b, of shape (M,) 15 """ 16 x, w, b = cache 17 dx, dw, db = None, None, None 18 #(10, 6) 19 #(6, 5) 20 #(5,) 21 ############################################################################# 22 # TODO: Implement the affine backward pass. # 23 ############################################################################# 24 #loss ==>>dout 10 *5 25 #dx ==>> 10*5 * 5*6 >>>10*6 26 dx = np.dot(dout,w.T) 27 #dw ==>>6*10 * 10*5 >>>6*5 28 dw = np.dot(x.T,dout) 29 # db ==>> 5 30 db = np.sum(dout,axis=0) 31 ############################################################################# 32 # END OF YOUR CODE # 33 ############################################################################# 34 return dx, dw, db
cell 5 ReLU 的前向传播
1 # Test the relu_forward function 2 3 x = np.linspace(-0.5, 0.5, num=12).reshape(3, 4) 4 5 out, _ = relu_forward(x) 6 correct_out = np.array([[ 0., 0., 0., 0., ], 7 [ 0., 0., 0.04545455, 0.13636364,], 8 [ 0.22727273, 0.31818182, 0.40909091, 0.5, ]]) 9 # Compare your output with ours. The error should be around 1e-8 10 print 'Testing relu_forward function:' 11 print 'difference: ', rel_error(out, correct_out)
结果:

relu_forward(x)内容:
1 def relu_forward(x): 2 """ 3 Computes the forward pass for a layer of rectified linear units (ReLUs). 4 5 Input: 6 - x: Inputs, of any shape 7 8 Returns a tuple of: 9 - out: Output, of the same shape as x 10 - cache: x 11 """ 12 out = None 13 ############################################################################# 14 # TODO: Implement the ReLU forward pass. # 15 ############################################################################# 16 out = x*(x>0) 17 ############################################################################# 18 # END OF YOUR CODE # 19 ############################################################################# 20 cache = x 21 return out, cache
cell 6 ReLU 反向传播
1 x = np.random.randn(10, 10) 2 dout = np.random.randn(*x.shape) 3 dx_num = eval_numerical_gradient_array(lambda x: relu_forward(x)[0], x, dout) 4 _, cache = relu_forward(x) 5 dx = relu_backward(dout, cache) 6 # The error should be around 1e-12 7 print 'Testing relu_backward function:' 8 print 'dx error: ', rel_error(dx_num, dx)
结果:

relu_forward(x)内容:
1 def relu_backward(dout, cache): 2 """ 3 Computes the backward pass for a layer of rectified linear units (ReLUs). 4 5 Input: 6 - dout: Upstream derivatives, of any shape 7 - cache: Input x, of same shape as dout 8 9 Returns: 10 - dx: Gradient with respect to x 11 """ 12 dx, x = None, cache 13 ############################################################################# 14 # TODO: Implement the ReLU backward pass. # 15 ############################################################################# 16 dx = dout * (x>=0) 17 ############################################################################# 18 # END OF YOUR CODE # 19 ############################################################################# 20 return dx
cell 7 affine + ReLU 组合:
1 from cs231n.layer_utils import affine_relu_forward, affine_relu_backward 2 3 x = np.random.randn(2, 3, 4) 4 w = np.random.randn(12, 10) 5 b = np.random.randn(10) 6 dout = np.random.randn(2, 10) 7 8 out, cache = affine_relu_forward(x, w, b) 9 dx, dw, db = affine_relu_backward(dout, cache) 10 11 dx_num = eval_numerical_gradient_array(lambda x: affine_relu_forward(x, w, b)[0], x, dout) 12 dw_num = eval_numerical_gradient_array(lambda w: affine_relu_forward(x, w, b)[0], w, dout) 13 db_num = eval_numerical_gradient_array(lambda b: affine_relu_forward(x, w, b)[0], b, dout) 14 15 dx = dx.reshape(2, 3, 4) 16 print 'Testing affine_relu_forward:' 17 print 'dx error: ', rel_error(dx_num, dx) 18 print 'dw error: ', rel_error(dw_num, dw) 19 print 'db error: ', rel_error(db_num, db)
结果:

affine_relu_forward(x, w, b):
1 def affine_relu_forward(x, w, b): 2 """ 3 Convenience layer that perorms an affine transform followed by a ReLU 4 5 Inputs: 6 - x: Input to the affine layer 7 - w, b: Weights for the affine layer 8 9 Returns a tuple of: 10 - out: Output from the ReLU 11 - cache: Object to give to the backward pass 12 """ 13 a, fc_cache = affine_forward(x, w, b) 14 out, relu_cache = relu_forward(a) 15 cache = (fc_cache, relu_cache) 16 return out, cache
affine_relu_backward(dout, cache):
1 def affine_relu_backward(dout, cache): 2 """ 3 Backward pass for the affine-relu convenience layer 4 """ 5 fc_cache, relu_cache = cache 6 da = relu_backward(dout, relu_cache) 7 dx, dw, db = affine_backward(da, fc_cache) 8 return dx, dw, db
cell 8 Softmax SVM
这两层的代码在之前已经实现过。并且原文件也给出了。这里不再解释。原理同上。
cell 9 Two-layer network
实现: The architecure should be affine - relu - affine - softmax.
原理依旧是链式法则。
先前向传播,记录传播中用到的数值,之后的偏导需要用到,然后反向传播。
1 N, D, H, C = 3, 5, 50, 7 2 X = np.random.randn(N, D) 3 y = np.random.randint(C, size=N) 4 5 std = 1e-2 6 model = TwoLayerNet(input_dim=D, hidden_dim=H, num_classes=C, weight_scale=std) 7 # 3 example 5 input 50 hidden 7 class 8 #w1 5*50 b1 50 w2 50*7 b2 7 9 print 'Testing initialization ... ' 10 W1_std = abs(model.params['W1'].std() - std) 11 b1 = model.params['b1'] 12 W2_std = abs(model.params['W2'].std() - std) 13 b2 = model.params['b2'] 14 assert W1_std < std / 10, 'First layer weights do not seem right' 15 assert np.all(b1 == 0), 'First layer biases do not seem right' 16 assert W2_std < std / 10, 'Second layer weights do not seem right' 17 assert np.all(b2 == 0), 'Second layer biases do not seem right' 18 19 print 'Testing test-time forward pass ... ' 20 model.params['W1'] = np.linspace(-0.7, 0.3, num=D*H).reshape(D, H) 21 model.params['b1'] = np.linspace(-0.1, 0.9, num=H) 22 model.params['W2'] = np.linspace(-0.3, 0.4, num=H*C).reshape(H, C) 23 model.params['b2'] = np.linspace(-0.9, 0.1, num=C) 24 X = np.linspace(-5.5, 4.5, num=N*D).reshape(D, N).T 25 scores = model.loss(X) 26 correct_scores = np.asarray( 27 [[11.53165108, 12.2917344, 13.05181771, 13.81190102, 14.57198434, 15.33206765, 16.09215096], 28 [12.05769098, 12.74614105, 13.43459113, 14.1230412, 14.81149128, 15.49994135, 16.18839143], 29 [12.58373087, 13.20054771, 13.81736455, 14.43418138, 15.05099822, 15.66781506, 16.2846319 ]]) 30 scores_diff = np.abs(scores - correct_scores).sum() 31 assert scores_diff < 1e-6, 'Problem with test-time forward pass' 32 33 print 'Testing training loss (no regularization)' 34 y = np.asarray([0, 5, 1]) 35 loss, grads = model.loss(X, y) 36 correct_loss = 3.4702243556 37 assert abs(loss - correct_loss) < 1e-10, 'Problem with training-time loss' 38 39 model.reg = 1.0 40 loss, grads = model.loss(X, y) 41 correct_loss = 26.5948426952 42 assert abs(loss - correct_loss) < 1e-10, 'Problem with regularization loss' 43 44 for reg in [0.0, 0.7]: 45 print 'Running numeric gradient check with reg = ', reg 46 model.reg = reg 47 loss, grads = model.loss(X, y) 48 49 for name in sorted(grads): 50 f = lambda _: model.loss(X, y)[0] 51 grad_num = eval_numerical_gradient(f, model.params[name], verbose=False) 52 print '%s relative error: %.2e' % (name, rel_error(grad_num, grads[name]))
结果:

涉及的TwoLayerNet 类:
1 class TwoLayerNet(object): 2 """ 3 A two-layer fully-connected neural network with ReLU nonlinearity and 4 softmax loss that uses a modular layer design. We assume an input dimension 5 of D, a hidden dimension of H, and perform classification over C classes. 6 7 The architecure should be affine - relu - affine - softmax. 8 9 Note that this class does not implement gradient descent; instead, it 10 will interact with a separate Solver object that is responsible for running 11 optimization. 12 13 The learnable parameters of the model are stored in the dictionary 14 self.params that maps parameter names to numpy arrays. 15 """ 16 17 def __init__(self, input_dim=3 * 32 * 32, hidden_dim=100, num_classes=10, 18 weight_scale=1e-3, reg=0.0): 19 """ 20 Initialize a new network. 21 22 Inputs: 23 - input_dim: An integer giving the size of the input 24 - hidden_dim: An integer giving the size of the hidden layer 25 - num_classes: An integer giving the number of classes to classify 26 - dropout: Scalar between 0 and 1 giving dropout strength. 27 - weight_scale: Scalar giving the standard deviation for random 28 initialization of the weights. 29 - reg: Scalar giving L2 regularization strength. 30 """ 31 self.params = {} 32 self.reg = reg 33 self.D = input_dim 34 self.M = hidden_dim 35 self.C = num_classes 36 self.reg = reg 37 38 w1 = weight_scale * np.random.randn(self.D, self.M) 39 b1 = np.zeros(hidden_dim) 40 w2 = weight_scale * np.random.randn(self.M, self.C) 41 b2 = np.zeros(self.C) 42 43 self.params.update({'W1': w1, 44 'W2': w2, 45 'b1': b1, 46 'b2': b2}) 47 48 def loss(self, X, y=None): 49 """ 50 Compute loss and gradient for a minibatch of data. 51 52 Inputs: 53 - X: Array of input data of shape (N, d_1, ..., d_k) 54 - y: Array of labels, of shape (N,). y[i] gives the label for X[i]. 55 56 Returns: 57 If y is None, then run a test-time forward pass of the model and return: 58 - scores: Array of shape (N, C) giving classification scores, where 59 scores[i, c] is the classification score for X[i] and class c. 60 61 If y is not None, then run a training-time forward and backward pass and 62 return a tuple of: 63 - loss: Scalar value giving the loss 64 - grads: Dictionary with the same keys as self.params, mapping parameter 65 names to gradients of the loss with respect to those parameters. 66 """ 67 68 ####################################################################### 69 # TODO: Implement the backward pass for the two-layer net. Store the loss # 70 # in the loss variable and gradients in the grads dictionary. Compute data # 71 # loss using softmax, and make sure that grads[k] holds the gradients for # 72 # self.params[k]. Don't forget to add L2 regularization! # 73 # # 74 # NOTE: To ensure that your implementation matches ours and you pass the # 75 # automated tests, make sure that your L2 regularization includes a factor # 76 # of 0.5 to simplify the expression for the gradient. # 77 ####################################################################### 78 79 W1, b1, W2, b2 = self.params['W1'], self.params[ 80 'b1'], self.params['W2'], self.params['b2'] 81 82 X = X.reshape(X.shape[0], self.D) 83 # Forward into first layer 84 hidden_layer, cache_hidden_layer = affine_relu_forward(X, W1, b1) 85 # Forward into second layer 86 scores, cache_scores = affine_forward(hidden_layer, W2, b2) 87 88 # If y is None then we are in test mode so just return scores 89 if y is None: 90 return scores 91 92 data_loss, dscores = softmax_loss(scores, y) 93 reg_loss = 0.5 * self.reg * np.sum(W1**2) 94 reg_loss += 0.5 * self.reg * np.sum(W2**2) 95 loss = data_loss + reg_loss 96 97 # Backpropagaton 98 grads = {} 99 # Backprop into second layer 100 dx1, dW2, db2 = affine_backward(dscores, cache_scores) 101 dW2 += self.reg * W2 102 103 # Backprop into first layer 104 dx, dW1, db1 = affine_relu_backward( 105 dx1, cache_hidden_layer) 106 dW1 += self.reg * W1 107 108 grads.update({'W1': dW1, 109 'b1': db1, 110 'W2': dW2, 111 'b2': db2}) 112 113 return loss, grads
cell 10 使用独立的solver对模型进行训练。
之前训练函数是包含在模型类的方法中的。这样可以对参数》》batch size 正则衰减等值进行修改。
使用独立的solver进行训练,逻辑更清晰。
得到的结果用图像显示:

cell 13 建立隐藏层可选的模型
1 N, D, H1, H2, C = 2, 15, 20, 30, 10 2 X = np.random.randn(N, D) 3 y = np.random.randint(C, size=(N,)) 4 5 for reg in [0, 3.14]: 6 print 'Running check with reg = ', reg 7 model = FullyConnectedNet([H1, H2], input_dim=D, num_classes=C, 8 reg=reg, weight_scale=5e-2, dtype=np.float64) 9 10 loss, grads = model.loss(X, y) 11 print 'Initial loss: ', loss 12 13 for name in sorted(grads): 14 f = lambda _: model.loss(X, y)[0] 15 grad_num = eval_numerical_gradient(f, model.params[name], verbose=False, h=1e-5) 16 print '%s relative error: %.2e' % (name, rel_error(grad_num, grads[name]))
由于其中的FullyConnectedNet类包含的内容较多,不在这里贴了。
主要步骤:
对于不同的层数,建立对应的参数:
1 Ws = {'W' + str(i + 1): 2 weight_scale * np.random.randn(dims[i], dims[i + 1]) for i in range(len(dims) - 1)} 3 b = {'b' + str(i + 1): np.zeros(dims[i + 1]) 4 for i in range(len(dims) - 1)}
之后便是使用这些参数,原理是一致的。
cell 16 SGD+Momentum
1 def sgd_momentum(w, dw, config=None): 2 """ 3 Performs stochastic gradient descent with momentum. 4 5 config format: 6 - learning_rate: Scalar learning rate. 7 - momentum: Scalar between 0 and 1 giving the momentum value. 8 Setting momentum = 0 reduces to sgd. 9 - velocity: A numpy array of the same shape as w and dw used to store a moving 10 average of the gradients. 11 """ 12 if config is None: config = {} 13 config.setdefault('learning_rate', 1e-2) 14 config.setdefault('momentum', 0.9) 15 v = config.get('velocity', np.zeros_like(w)) 16 17 next_w = None 18 ############################################################################# 19 # TODO: Implement the momentum update formula. Store the updated value in # 20 # the next_w variable. You should also use and update the velocity v. # 21 ############################################################################# 22 v = config['momentum']*v - config['learning_rate']*dw 23 next_w = v+w 24 ############################################################################# 25 # END OF YOUR CODE # 26 ############################################################################# 27 config['velocity'] = v 28 29 return next_w, config
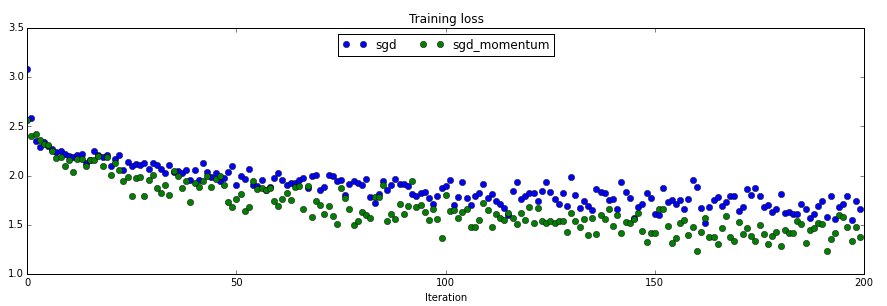
相比较而言,sgd_momentum 收敛的速度更快。
cell 18 rmsprop
1 def rmsprop(x, dx, config=None): 2 """ 3 Uses the RMSProp update rule, which uses a moving average of squared gradient 4 values to set adaptive per-parameter learning rates. 5 6 config format: 7 - learning_rate: Scalar learning rate. 8 - decay_rate: Scalar between 0 and 1 giving the decay rate for the squared 9 gradient cache. 10 - epsilon: Small scalar used for smoothing to avoid dividing by zero. 11 - cache: Moving average of second moments of gradients. 12 """ 13 if config is None: config = {} 14 config.setdefault('learning_rate', 1e-2) 15 config.setdefault('decay_rate', 0.99) 16 config.setdefault('epsilon', 1e-8) 17 config.setdefault('cache', np.zeros_like(x)) 18 19 next_x = None 20 ############################################################################# 21 # TODO: Implement the RMSprop update formula, storing the next value of x # 22 # in the next_x variable. Don't forget to update cache value stored in # 23 # config['cache']. # 24 ############################################################################# 25 config['cache'] = config['decay_rate']*config['cache'] + (1 - config['decay_rate'])*dx**2 26 next_x = x - config['learning_rate']*dx / (np.sqrt(config['cache']) + config['epsilon']) 27 ############################################################################# 28 # END OF YOUR CODE # 29 ############################################################################# 30 31 return next_x, config
cell 19 adam
1 def adam(x, dx, config=None): 2 """ 3 Uses the Adam update rule, which incorporates moving averages of both the 4 gradient and its square and a bias correction term. 5 6 config format: 7 - learning_rate: Scalar learning rate. 8 - beta1: Decay rate for moving average of first moment of gradient. 9 - beta2: Decay rate for moving average of second moment of gradient. 10 - epsilon: Small scalar used for smoothing to avoid dividing by zero. 11 - m: Moving average of gradient. 12 - v: Moving average of squared gradient. 13 - t: Iteration number. 14 """ 15 if config is None: config = {} 16 config.setdefault('learning_rate', 1e-3) 17 config.setdefault('beta1', 0.9) 18 config.setdefault('beta2', 0.999) 19 config.setdefault('epsilon', 1e-8) 20 config.setdefault('m', np.zeros_like(x)) 21 config.setdefault('v', np.zeros_like(x)) 22 config.setdefault('t', 1e5) 23 24 next_x = None 25 beta_1 = config['beta1'] 26 beta_2 = config['beta2'] 27 ############################################################################# 28 # TODO: Implement the Adam update formula, storing the next value of x in # 29 # the next_x variable. Don't forget to update the m, v, and t variables # 30 # stored in config. # 31 ############################################################################# 32 config['t'] = config['t'] + 1 33 config['m'] = config['m'] * config['beta1'] + (1 - config['beta1']) * dx 34 config['v'] = config['v'] * config['beta2'] + (1 - config['beta2']) * (dx ** 2) 35 beta_1 = 1 - (beta_1**config['t']) 36 beta_2 = np.sqrt(1 - (beta_2**config['t'])) 37 config['learning_rate'] = config['learning_rate'] * (beta_2/beta_1) 38 next_x = x - ((config['learning_rate'] * config['m']) / (np.sqrt(config['v']+config['epsilon']))) 39 ############################################################################# 40 # END OF YOUR CODE # 41 ############################################################################# 42 43 return next_x, config
4中方法的收敛速度比较:
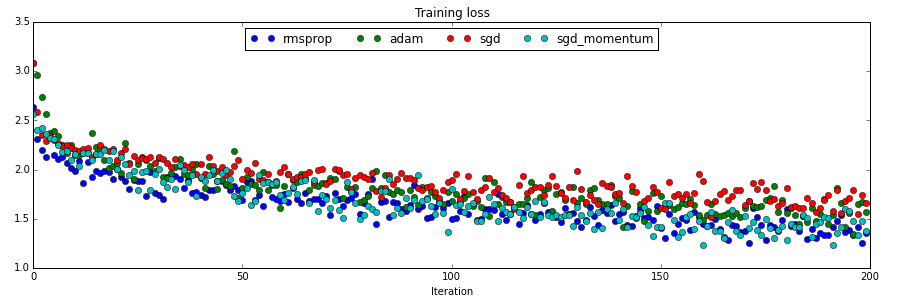
最终会给出所有的代码。
附:通关CS231n企鹅群:578975100 validation:DL-CS231n