JVM运行时数据区规范
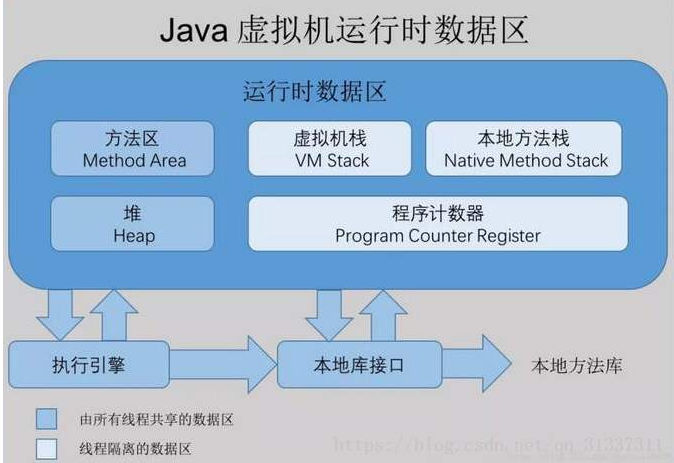
线程共享区域:JVM启动的时候,这块区域就开始分配空间。




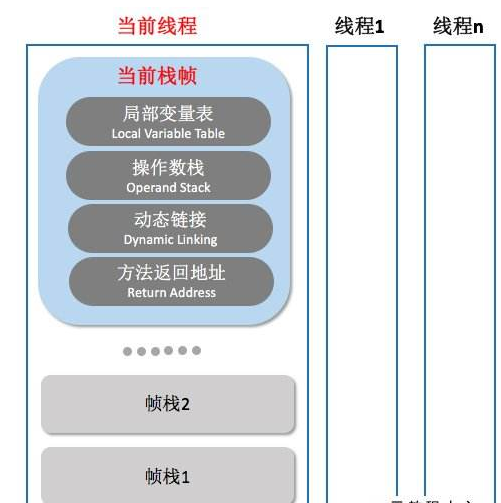 栈内存为线程私有的空间,每个线程都会创建私有的栈内存。栈空间内存设置过大,创建线程数量较多时会出现栈内存溢出StackOverflowError。
栈内存为线程私有的空间,每个线程都会创建私有的栈内存。栈空间内存设置过大,创建线程数量较多时会出现栈内存溢出StackOverflowError。
线程私有区域:没有线程的时候,这块区域是不存在的。这块空间的生命周期特别短暂,不存在垃圾回收的问题。
Hotspot运行时数据区
JDK1.6&JDK1.7&JDK1.8+
分配JVM内存空间
分配堆的大小
–Xms(堆的初始容量)
-Xmx(堆的最大容量)
分配方法区的大小
-XX:PermSize
永久代的初始容量
-XX:MaxPermSize
永久代的最大容量
-XX:MetaspaceSize
元空间的初始大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释
放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize
最大空间,默认是没有限制的。
分配线程空间的大小
-Xss:
为jvm启动的每个线程分配的内存大小,默认JDK1.4中是256K,JDK1.5+中是1M
1.方法区
存储内容
1.1 类型信息
类型的全限定名
超类的全限定名
直接超接口的全限定名
类型标志(该类是类类型还是接口类型)
类的访问描述符(public、private、default、abstract、fifinal、static).
1.2类型的常量池
存放该类型所用到的常量的有序集合,包括直接常量(如字符串、整数、浮点数的常量)和对其他类型、字段、方法的符号引用。
常量池中每一个保存的常量都有一个索引,就像数组中的字段一样。
因为常量池中保存着所有类型使用到的类型、字段、方法的字符引用,所以它也是动态连接的主要对象(在动态链接中起到核心作用)。
1.3字段信息(该类声明的所有字段)
字段修饰符(public、protect、private、default)
字段的类型
字段名称
1.4方法信息
方法信息中包含类的所有方法,每个方法包含以下信息:
方法修饰符
方法返回类型
方法名
方法参数个数、类型、顺序等
方法字节码
操作数栈和该方法在栈帧中的局部变量区大小
异常表
1.5类变量(静态变量)
指该类所有对象共享的变量,即使没有任何实例对象时,也可以访问的类变量。它们与类进行绑定。
1.6指向类加载器的引用
每一个被JVM加载的类型,都保存这个类加载器的引用,类加载器动态链接时会用到。
1.7指向Class实例的引用
类加载的过程中,虚拟机会创建该类型的Class实例,方法区中必须保存对该对象的引用。
通过Class.forName(String className)来查找获得该实例的引用,然后创建该类的对象。
1.8方法表
为了提高访问效率,JVM可能会对每个装载的非抽象类,都创建一个数组,数组的每个元素是实例可能
调用的方法的直接引用,包括父类中继承过来的方法。这个表在抽象类或者接口中是没有的。
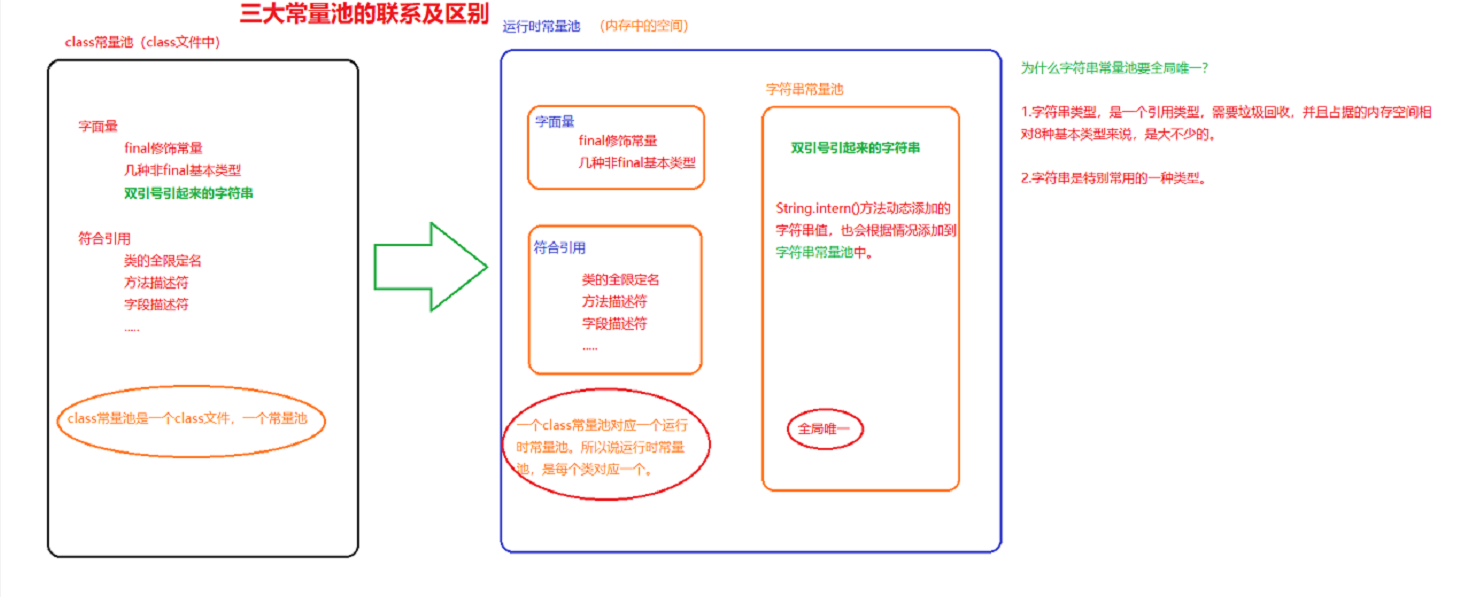
1.9运行时常量池(Runtime Constant Pool)
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译器生成的各种字面常量和符号引用,
这部分内容被类加载后进入方法区的运行时常量池中存放。
运行时常量池相对于Class文件常量池的另外一个特征具有动态性,可以在运行期间将新的常量放入池中(典型的如String类的intern()方法)。
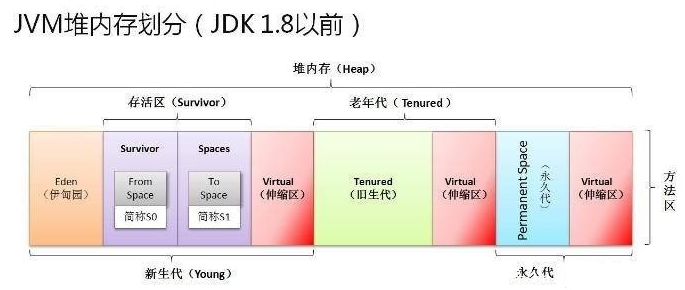
永久代和元空间的区别
永久代和元空间存储位置和存储内容的区别:
存储位置不同,永久代物理是是堆的一部分,和新生代,老年代地址是连续的,而元空间属于本地内存;
由于永久代它的大小是比较小的,而元空间的大小是决定于内地内存的。
所以说永久代使用不当,比较容易出现OOM异常。而元空间一般不会。
存储内容不同,元空间存储类的元信息,[静态变量]和[常量池]等并入堆中。相当于永久代的数据被分到了堆和元空间中。
为什么要把永久代替换为元空间?
1.原来Java是属于Sun公司的,后来Java被Oracle收购了。
Sun公司实现的Java中的JVM是Hotspot。
当时Oracle堆Java的JVM也有一个实现,交JRockit。
后来Oracle收购了Java之后,也同时想把Hotspot和JRockit合二为一。他们俩很大的不同,就是方法区的实现。
2.字符串存在永久代中,容易出现性能问题和永久代内存溢出。
3.类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
4.永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
最典型的场景就是,在 jsp 页面比较多的情况,容易出现永久代内存溢出。
JSP页面,需要动态生成Servlet类class文件运行时常量池和字符串常量池(面试高频)
字符串常量池如何存储数据的
stringtable是类似于hashtable的数据结构,hashtable/hashmap数据结构如下:
底层数组是:数组+链表
数组中的元素是entry对象。
entry对象是包含一个K/V对的。
K就是hashmap中的key。
V就是hashmap中的value。
一个entry对象,如何去在数组中什么位置进行存储呢?
hash算法来分配
首先对于要存储到hashmap或者hashtable中的key进行hashcode求值。
其次拿着这个hashcode值对数组的长度进行取余(余数肯定是0-------数组的长度-1);
余数是几,则存储到数组的对应下标位置。
当数组长度过短,容易产生hash冲突,那么hash冲突之后呢,一般使用链表方式去解决。链表的特点是:增删快、查找慢。
链表的特点是:增删快、查找慢。
结论:如果链接过长,不利于查找。
字符串常量池查找字符串的方式:
根据字符串的 hashcode 找到对应entry。如果没冲突,它可能只是一个entry,如果有冲突,它可能是一个entry链表,然后Java再遍历entry链表,匹配引用对应的字符串。
如果找得到字符串,返回引用。如果找不到字符串,会把字符串放到常量池,并把引用保存到stringtable里
字符串常量池案例分析
public class Test {
public void test() {
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1 == str2); //false
String str3 = new String("abc");
System.out.println(str3 == str2); //false
String str4 = "a" + "b";
System.out.println(str4 == "ab"); true
final String s = "a";
String str5 = s + "b";
System.out.println(str5 == "ab"); true
String s1 = "a";
String s2 = "b";
String str6 = s1 + s2;
System.out.println(str6 == "ab"); //false
String str7 = "abc".substring(0,2);
System.out.println(str7 == "ab"); false
String str8 = "abc".toUpperCase();
System.out.println(str8 == "ABC"); false
String s3 = "abc";
String s4 = "ab" + getString();
System.out.println(s3 == s4); //false
String s5 = "a";
String s6 = "abc";
String s7 = s5 + "bc";
System.out.println(s6 == s7.intern()); //true
}
private String getString(){
return "c";
}
}
String的Intern方法详解
String a = "hello";
String b = new String("hello");
System.out.println(a == b); //false
String c = "world";
System.out.println(c.intern() == c); //true
String d = new String("mike");
System.out.println(d.intern() == d); //false
String e = new String("jo") + new String("hn"); newString("john") -->不会放到常量池。
System.out.println(e.intern() == e); //true --->intern 将字符串放到常量池中。
String f = new String("ja") + new String("va");
System.out.println(f.intern() == f); //false (java关键字 字符串在编译器就放入常量池中)
intern的作用是把new出来的字符串的引用添加到stringtable中,java会先计算string的hashcode,查找stringtable中是否已经有string对应的引用了,如果有返回引用(地址),然后没有把字符串的地址
放到stringtable中,并返回字符串的引用(地址)。
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2); //false
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4); jdk1.6 false jdk1.7+ true
}
2.Java堆
Java堆中,主要是用来存储对象和数组的。
堆内存划分
堆被划分为老年代和年轻代。
年轻代和老年代的内存占比默认为1:2。
年轻代又划分为:伊甸园(Eden)、两个幸存区(Survivor)
伊甸园和两个幸存区的内存占比默认为8:1:1。
之所以我们堆内存要进行以上这么细粒度的内存划分,是为了垃圾回收。
垃圾回收针对不同情况的对象,回收策略(回收算法)是不同的的。而通过内存的划分,可以将不同的
算法在不同的区域中进行使用。
比如说年轻代使用了复制算法。
年轻代中的对象,生命周期很短,基本上是很快就死了,也就是被GC了。
老年代中的对象,都是一些老顽固,都是多次回收的对象或者大对象才存到老年代中。
内存的分配原则
优先在Eden分配,如果Eden空间不足虚拟机则会进行一次MinorGC
大对象直接进入老年代{大对象一般是 很长的字符串或数组}
长期存活的对象也会进入老年代,每个对象都有一个age,当age达到设定的年纪的时间就会进入老年代。默认是15.
内存分配安全问题
在分配内存的同时,存在线程安全的问题,即虚拟机给A线程分配内存过程中,指针未修改,B线程可能同时使用了同样一块内存。
在JVM中有两种解决办法:
1. CAS,比较和交换(Compare And Swap): CAS 是乐观锁的一种实现方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。虚拟机采用 CAS 配上失败重试的方式保证更新操作的原子性。
2. TLAB,本地线程分配缓冲(Thread Local Allocation Buffffer即TLAB): 为每一个线程预先分配一块内存,JVM在给线程中的对象分配内存时,首先在TLAB分配,当对象大于TLAB中的剩余内存或TLAB的内存已用尽时,再采用上述的CAS进行内存分配。
对象的内存布局
普通对象在内存中存储的布局可以分为4块区域: 对象头(Header 在hotport称为markword 长度8个字节)
ClassPointer 指针:--xx:+UseCompressedClassPointers 为4个字节 ,若不开启压缩 为8个字节
实例数据(Instance Data)引用类型: -XX:UseCompressedOops 开启压缩为4个字节,不开启为8个字节。
对齐填充(Padding) 这个对齐是8的倍数。
数组对象在内存中存储的布局可以分为4块区域:
对象头(Header 在hotport称为markword 长度8个字节)
ClassPointer 指针:--xx:+UseCompressedClassPointers 为4个字节 ,若不开启压缩 为8个字节 。
数组长度:4个字节。
实例数据(Instance Data)引用类型: -XX:UseCompressedOops 开启压缩为4个字节,不开启为8个字节。
对齐填充(Padding) 这个对齐是8的倍数。对象头具体包含:(JDK1.8)32位
对象定位
1.句柄池 :稳定,对象被移动只需要修改句柄中的地址。
2.直接指针:指向对象然后指向class,访问速度快。
Hotspot 中使用直接指针。
Java虚拟机栈
虚拟机栈也是线程私有,而且生命周期与线程相同,每个Java方法在执行的时候都会创建一个栈帧。
同时,栈内存也决定方法调用的深度,栈内存过小则会导致方法调用的深度较小,如递归调用的次数较少。
本地方法栈
执行其他语言的方法,主要指的就是C语言的方法(也叫本地方法,使用native关键字修饰的方法),它在执行的时候,也需要执行空间,那么这个空间就是本地方法栈。
为什么需要本地方法栈?
clone方法,不是通过java的构造方法去创建java对象,而是直接操作JVM中的堆内存,进行对象的复制。
直接操作JVM中的堆内存,这不是Java语言能干的事情,但是还必须要有该功能。怎么办呢?
通过本地方法接口,去调用C函数。