中文分词技术说起来一定不陌生,大家初步接触时在网上查阅到最多的应该就是由中科院率先研究的ICTCLAS中文自动分词系统及其相关的源代码,不管是C#还是C++的或是VB的,想必都可以下载到。先不管是否可以看懂里面的源代码,至少可以知道这项技术即使在国内也已经相当的成熟了。
简单介绍一下分词的技术相关的算法以及对此几种算法的比较,最后用其中一种算法实现一个中文分词的小程序。
①中文分词的算法
中文分词技术发展到今天概括起来可以归为三类:基于匹配的分词、基于统计的分词和基于理解的分词。
a.基于匹配的分词方法:
由于该分词方法自动化程度较高,因此又常被称为机械分词法。该方法遵循一定的算法将待分析的文档与一个机器词典中的词条进行匹配,若匹配成功则识别出一个词。常用的集中机械分词方法有以下几种:正向最大匹配法(由左到右的方向);逆向最大匹配法(由右到左的方向);最少切分(使每一句中切出的次数最小)。
b.基于理解的分词方法:
该方法的基本思想是在分词的同时,进行句法分析和语义分析,利用句法信息和语义信息来处理歧义,以提高分词的准确度。也即让计算机模拟人理解句子的过程,以达到识别词的目的,该系统主要包括三个子系统:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断。该分词方法需要使用大量的语言知识和信息作为支撑。然而,由于汉语语言知识的复杂性,将各种语言信息组织成机器可直接读取的形式是非常困难的,因此目前基于理解的分词系统未达到使用的水平。
c.基于统计的分词方法:
该方法的理论依据是:由于词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词,也就是说字与字相邻共现的概率能较好的反映成词的可信度。可以对相邻共现的各个字的组合的频度进行统计,计算他们的互现信息。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成一个词。该方法的缺点是经常会抽出一些共现频度高、但不是词的字组,如“有的”、“你的”等,并且对常用词的识别精度不搞,时空开销却很大。
②分词算法的比较
下面对常用的几种算法进行比较分析
a.基于匹配的分词算法:
由于该方法的唯一根据就是词典,因此,待切分文档中的词是否被收录到词典中对最终的分词结果起着决定性的作用。一般来说,已登录词可以很好的被识别出来,而未登录词则会受到众多方面因素的影响不能被有效的识别出来,这主要取决于其匹配的模式,因此该方法对新词的识别率较低。此外,由于其分词过程仅仅是字符串的机械匹配,因此无法利用汉语上下文语境信息对歧义字词作识别。因此,若运用此算法,为提高分词的准确性,需要对系统词典随时进行更新,一个完善的词典是基于匹配的分词算法成功的关键因素。
b.基于统计的分词算法:
由于该方法依据的是汉字串在文档中的出现规律,借助统计学方法,根据词频识别词语,因此对新词有较高的识别率。然而,需要指出的是,在汉语中,同一个意思往往会有多种表达形式,同义词比较多,词语重现率比较低,而对于缺乏理解能力的计算机来说,就会将他们看作是完全不相同的字符串,而不能识别为一个独立的词,另外该算法只有当被统计分析的语料足够大时,各个词语的重现率才能达到充分大,才能够成功识别出词语,因此其算法的时间和空间复杂度也都较高,而且事实现也相对较难。
c.实际运用与分析
通过上面分析可知,目前已有的中文分词系统中,一般的分词系统大都只采用了基于匹配的分词算法,而一些高级的分词系统则采用了以匹配为主的混合形分词算法,以增强对未登录词的识别能力。一般来说,混合形算法会在分词效果上比单纯的匹配算法的分词准确率有较大的提供,尤其是对于一些新词,而这往往是用户用于搜索的关键词,因此加入统计思想将会大大提高分词效果。
③简单的分词系统实现
下面将会用C#开发一个基于匹配分词算法的小系统。
a.读取词库文本文件
首先第一步是需要读取词库的文件,可以是.txt或是其他的文件形式,读取的目的是要利用这些词构建一个Tree。Tree的结构如下所示:
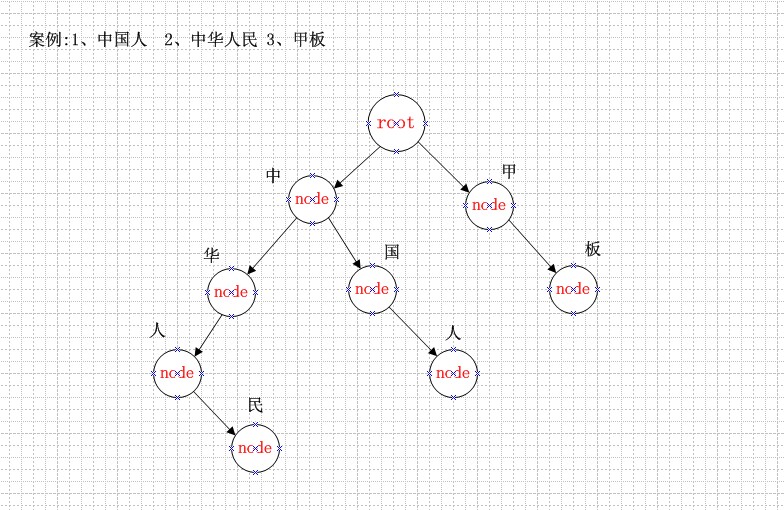
从上图中可以清楚地知道建树的主要思路是将词库中的词语用树与子树的关系关联起来,主要算法如下:
/// 词库数据构建树
/// </summary>
/// <param name="s"></param>
public void BuildTree(string s)
{
List<CNTreeNode> tmpRoot = rootNode.ChildNodes;
for (int i = 0; i < s.Length; i++)
{
int index = FindIndex(tmpRoot, s[i].ToString());
if (-1 == index)
{
CNTreeNode treeNode = new CNTreeNode(s[i].ToString());
tmpRoot.Add(treeNode);
tmpRoot = tmpRoot[tmpRoot.Count - 1].ChildNodes;
}
else
{
tmpRoot = tmpRoot[index].ChildNodes;
}
}
}
b. 中文分词
将文本中输入的词分开标识显示出来。效果如下:
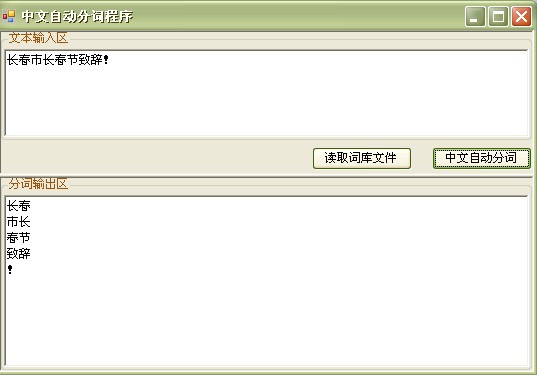
主要算法如下:
/// 中文分词
/// </summary>
/// <param name="s"></param>
public string[] CNAnalyse(string s)
{
StringBuilder sb = new StringBuilder();
List<CNTreeNode> tmpRoot = rootNode.ChildNodes;
int len = 0;
for (int i = 0; i < s.Length; i++)
{
int index = FindIndex(tmpRoot, s[i].ToString());
if (-1 == index)
{
if (len == 0)
{
sb.Append(s.Substring(i, 1) + "|");
}
else
{
sb.Append("|");
i--;
}
tmpRoot = rootNode.ChildNodes;
len = 0;
}
else
{
len++;
sb.Append(s[i].ToString());
tmpRoot = tmpRoot[index].ChildNodes;
}
}
string[] strs = sb.ToString().Split('|');
return strs;
}
注:在实现过程中,有参考其他类似的算法。
这只是对分词技术的初探,刚刚开始,在以后的时间里会继续优化目前的分词系统,积累更多的有关这方面的知识!