通常,利用网络对物体进行检测时,浅层网络分辨率高,学到的是图片的细节特征,深层网络,分辨率低,学到的更多的是语义特征。
1)、通常的CNN使用如下图中显示的网络,使用最后一层特征图进行预测
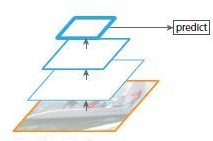
例如VGG16,feat_stride=16,表示若原图大小是1000*600,经过网络后最深一层的特征图大小是60*40,可理解为特征图上一像素点映射原图中一个16*16的区域;那这个是不是就表示,如果原图中有一个小于16*16大小的小物体,是不是就会被忽略掉,检测不到呢!
所以,使用上图中的网络的缺点就是,会造成检测小物体的性能急剧下降
2)、如果上面的单层检测会丢失细节特征;就会想到,利用图像的各个尺度进行训练和测试,比如下图所展示(图片金字塔生成特征金字塔)
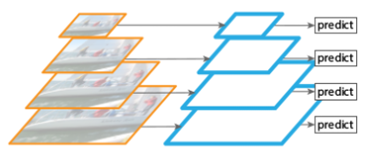
将图片缩放成多个比例,每个比例单独提取特征图进行预测,这样,可以得到比较理想的结果,但是比较耗时,不太适合运用到实际当中。
3)、为了节约时间,直接使用卷积网络中产生的各层特征图分别进行预测
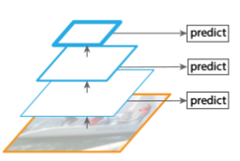
SSD网络也采用了类似的思想,这种方法的问题在于,让不同深度的特征图去学习同样的语义信息,同样会忽略掉底层网络中的细节特征
4)FPN网络,网络结构原理如下图所示
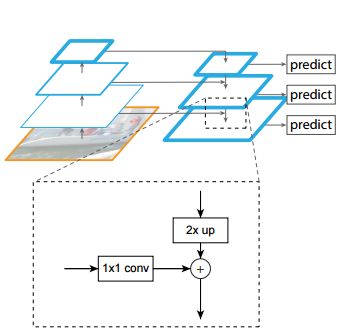
先来说下FPN能解决什么问题
FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能
左边的称为“自底向上”,右边的称为“自上而下”
① 自底向上:
自底向上的过程就是神经网络普通的正向传播过程,特征图经过卷积核计算,通常会越变越小
② 自上而下:
自上而下的过程是把更抽象、语义更强的高层特征图进行上采样,然后把该特征横向连接至前一层特征,因此,高层特征得到了增强,每一层预测所用的feature map都融合了不同分辨率、不同语义强度的特征,可以完成对应分辨率大小的物体进行检测,保证每一层都有合适的分辨率以及强语义特征。
值得注意的是:横向连接的两层特征在空间尺寸上要相同,这样做可以利用底层定位细节信息
上面通过文字描述完成了FPN网络的演化历程及其基本原理,下面通过一张图,对FPN的工作原理进行补充描述(基于ResNet50网络)
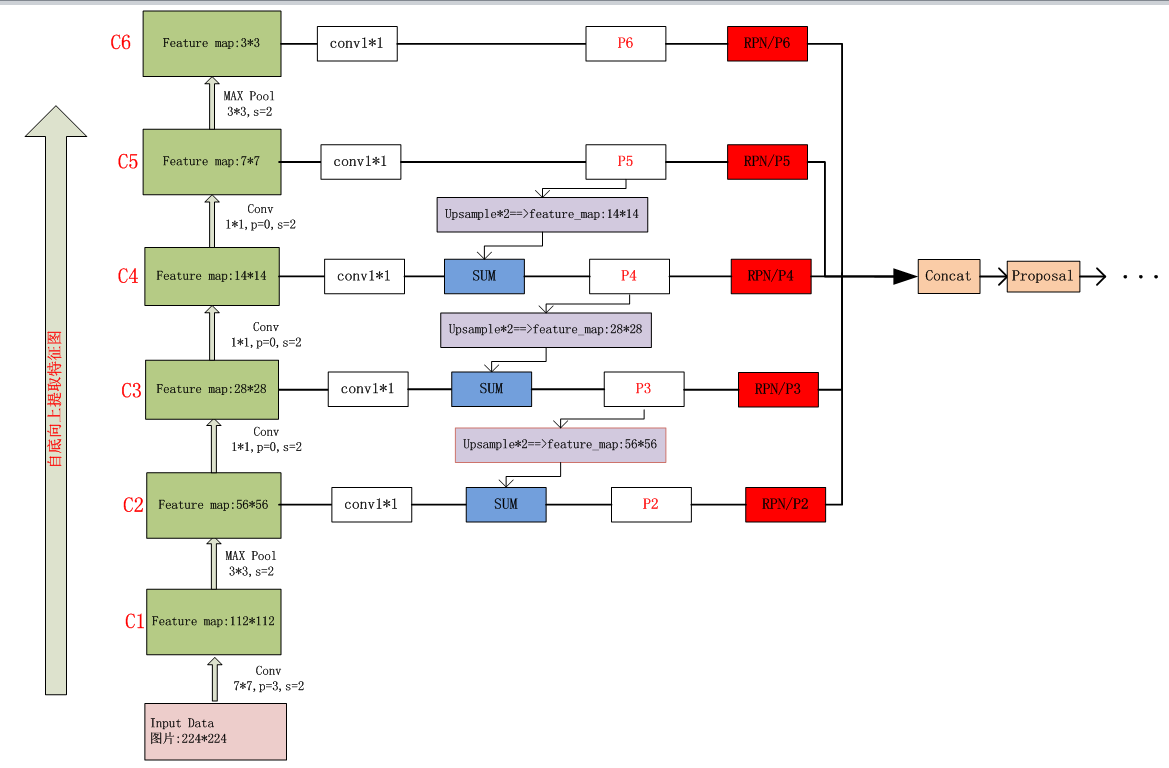
从上图中可以很清晰的看到FPN工作的原理,至于后面省略掉的网络不是这次的重点,可以参看RPN相关知识点
作为一枚技术小白,写这篇笔记的时候参考了很多博客论文,在这里表示感谢,同时,未经同意,请勿转载....