一、rabbitmq
1.1 简介
RabbitMQ(Rabbit Message Queue)是流行的开源消息队列系统,用erlang语言开发。
1.1.1 关键词说明
Broker:消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
1.1.2 消息队列运行机制
(1)客户端连接到消息队列服务器,打开一个channel。
(2)客户端声明一个exchange,并设置相关属性。
(3)客户端声明一个queue,并设置相关属性。
(4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
(5)客户端投递消息到exchange。(6)exchange接收到消息后,就根据消息的key和已经设置的binding,将消息投递到一个或多个队列里。注:在声明一个队列后,如果将其持久化,则下次不需要进行声明,因为该队列已经在rabbitMQ中了!!!例如下面的例子中都为首次声明一个队列!!!
1.1.3 exchange类型
1.Direct交换机
特点:依据key进行投递例如绑定时设置了routing key为”hello”,那么客户端提交的消息,只有设置了key为”hello”的才会投递到队列。
2.Topic交换机
特点:对key模式匹配后进行投递,符号”#”匹配一个或多个词,符号”*”匹配一个词例如”abc.#”匹配”abc.def.ghi”,”abc.*”只匹配”abc.def”。
3.Fanout交换机
特点:不需要key,采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列
1.2 构建环境
1.2.1 windows下安装rabbitmq
http://jingyan.baidu.com/article/a17d5285173ce68098c8f2e5.html
1.2.2 安装pika模块
python使用rabbitmq服务,可以使用现成的类库pika、txAMQP或者py-amqplib,这里选择了pika。
在命令行中直接使用pip命令:pip install pika
1.3 示例测试
实例的内容就是从send.py发送消息到rabbitmq,receive.py从rabbitmq接收send.py发送的信息。
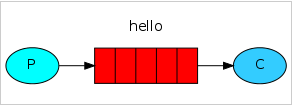
P表示produce,生产者的意思,也可以称为发送者,实例中表现为send.py;
C表示consumer,消费者的意思,也可以称为接收者,实例中表现为receive.py;
中间红色的表示队列的意思,实例中表现为hello队列。
1.3.1 send.py
import pika import random # 新建连接,rabbitmq安装在本地则hostname为'localhost' hostname = '192.168.1.133' parameters = pika.ConnectionParameters(hostname) connection = pika.BlockingConnection(parameters) # 创建通道 channel = connection.channel() # 声明一个队列,生产者和消费者都要声明一个相同的队列,用来防止万一某一方挂了,另一方能正常运行 channel.queue_declare(queue='hello') number = random.randint(1, 1000) body = 'hello world:%s' % number # 交换机; 队列名,写明将消息发往哪个队列; 消息内容 # routing_key在使用匿名交换机的时候才需要指定,表示发送到哪个队列 channel.basic_publish(exchange='', routing_key='hello', body=body) print " [x] Sent %s" % body connection.close()
1.3.2 receive.py
import pika hostname = '192.168.1.133' parameters = pika.ConnectionParameters(hostname) connection = pika.BlockingConnection(parameters) # 创建通道 channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print " [x] Received %r" % (body,) # 告诉rabbitmq使用callback来接收信息 channel.basic_consume(callback, queue='hello', no_ack=True) # 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理,按ctrl+c退出 print ' [*] Waiting for messages. To exit press CTRL+C' channel.start_consuming() 我们先运行send.py发送消息:
我们先运行send.py发送消息:
再运行receive.py接收消息:

1.4 rabbitmq的实现原理
https://www.cnblogs.com/wangyong123/articles/11658477.html
1.5 rabbitmq宕机了怎么办?
MQ默认建立的是临时 queue 和 exchange,如果不声明持久化,一旦 rabbitmq 挂掉,queue、exchange 将会全部丢失。所以我们一般在创建 queue 或者 exchange 的时候会声明 持久化。
1.5.1 queue声明持久化
# 声明消息队列,消息将在这个队列传递,如不存在,则创建。durable = True 代表消息队列持久化存储,False 非持久化存储 result = channel.queue_declare(queue = 'python-test',durable = True)
1.5.2 exchange声明持久化
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建.durable = True 代表exchange持久化存储,False 非持久化存储 channel.exchange_declare(exchange = 'python-test', durable = True)注意:如果已存在一个非持久化的 queue 或 exchange ,执行上述代码会报错,因为当前状态不能更改 queue 或 exchange 存储属性,需要删除重建。如果 queue 和 exchange 中一个声明了持久化,另一个没有声明持久化,则不允许绑定。
1.5.3 消息持久化
虽然 exchange 和 queue 都申明了持久化,但如果消息只存在内存里,rabbitmq 重启后,内存里的东西还是会丢失。所以必须声明消息也是持久化,从内存转存到硬盘。
# 向队列插入数值 routing_key是队列名。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化 channel.basic_publish(exchange = '',routing_key = 'python-test',body = message, properties=pika.BasicProperties(delivery_mode = 2))
1.5.4 acknowledgement消息不丢失
消费者(consumer)调用callback函数时,会存在处理消息失败的风险,如果处理失败,则消息丢失。但是也可以选择消费者处理失败时,将消息回退给 rabbitmq ,重新再被消费者消费,这个时候需要设置确认标识。
channel.basic_consume(callback,queue = 'python-test', # no_ack 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉 no_ack = False)
二、redis
Python内置了一个好用的队列结构。我们也可以是用redis实现类似的操作。并做一个简单的异步任务。
Redis提供了两种方式来作消息队列。一个是使用
生产者消费模式模式,另外一个方法就是发布订阅者模式。前者会让一个或者多个客户端监听消息队列,一旦消息到达,消费者马上消费,谁先抢到算谁的,如果队列里没有消息,则消费者继续监听。后者也是一个或多个客户端订阅消息频道,只要发布者发布消息,所有订阅者都能收到消息,订阅者都是平等的。
2.1 生产消费模型
主要使用了redis提供的blpop获取队列数据,如果队列没有数据则阻塞等待,也就是监听。
import redis class Task(object): def __init__(self): self.rcon = redis.StrictRedis(host='localhost', db=5) self.queue = 'task:prodcons:queue' def listen_task(self): while True: task = self.rcon.blpop(self.queue, 0)[1] print "Task get", task if __name__ == '__main__': print 'listen task queue' Task().listen_task()使用redis的brpop方式做队列,经过一段时间,会发现程序莫名其妙的卡主。也就是进程一切ok,redis的lpush也正常,唯独brpop不再消费。该问题十分不好复现,但是总是过了一段时间就会重现。本人采用了高并发,高延迟,弱网络环境等方式试图复现都没有成功,目前仍然在寻找解决方案。目测依赖redis做brokers的队列的celery也遇到同样的问题,并且其他语言也有类似问题,但是作者的解决方不适用。猜测问题的原因是redis在处理brpop的时候连接长时间不适用会自动假死。后来采用比较low的方案,每当凌晨3点左右重启一下队列服务。目前设置了更短的idle连接时间(config set timeout 10),再观察一下是否能复现。
不建议在生成环境使用该方案。如果使用类似方案也遇到了问题,并且有了解决方案,希望您能联系我哈哈哈。
升级了 redis 3.2 版本之后,运行了一个多月,目前没有再出现卡住的问题。
2.2 发布订阅模式
https://www.cnblogs.com/wangyong123/articles/11638181.html
三、rabbitmq与redis的区别
3.1 可靠性
redis :没有相应的机制保证消息的可靠消费,如果发布者发布一条消息,而没有对应的订阅者的话,这条消息将丢失,不会存在内存中;
rabbitmq:具有消息消费确认机制,如果发布一条消息,还没有消费者消费该队列,那么这条消息将一直存放在队列中,直到有消费者消费了该条消息,以此可以保证消息的可靠消费;
3.2 实用性
redis:实时性高,redis作为高效的缓存服务器,所有数据都存在在服务器中,所以它具有更高的实时性
3.3 消费者负载均衡
rabbitmq队列可以被多个消费者同时监控消费,但是每一条消息只能被消费一次,由于rabbitmq的消费确认机制,因此它能够根据消费者的消费能力而调整它的负载;
redis发布订阅模式,一个队列可以被多个消费者同时订阅,当有消息到达时,会将该消息依次发送给每个订阅者;
3.4 持久性
redis:redis的持久化是针对于整个redis缓存的内容,它有RDB和AOF两种持久化方式(redis持久化方式,后续更新),可以将整个redis实例持久化到磁盘,以此来做数据备份,防止异常情况下导致数据丢失。
rabbitmq:队列,消息都可以选择性持久化,持久化粒度更小,更灵活;
3.5 队列监控
rabbitmq实现了后台监控平台,可以在该平台上看到所有创建的队列的详细情况,良好的后台管理平台可以方面我们更好的使用;
redis没有所谓的监控平台。
3.6 总结
redis: 轻量级,低延迟,高并发,低可靠性;
rabbitmq:重量级,高可靠,异步,不保证实时;
rabbitmq是一个专门的AMQP协议队列,他的优势就在于提供可靠的队列服务,并且可做到异步,而redis主要是用于缓存的,redis的发布订阅模块,可用于实现及时性,且可靠性低的功能。