1.Spark简介
2.Spark安装总览
Spark安装配置分为以下6个步骤:下载,上传到虚拟机并解压,配置,配置HistortSerer,分发,启动集群
3.下载
https://spark.apache.org/downloads.html
4.上传解压
将本机下载好的安装包上传到虚拟机,我使用的是Xftp6,下载好后进行解压:tar xzvf spark.tgz(这里我对压缩包进行了重命名)

5.配置
为Spark配置JAVA的路径及启动时的主机和端口号
首先进入Spark目录,点开conf目录下有一个spark-env.sh.temeplate文件,复制一份,去掉后缀:cp spark-env.sh.temeplate spark-env.sh

修改此文件,添加以下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_261
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
注:第一个写jdk的路径,第二个写主机名
6.配置HistoryServer
6.1 主节点启动Spark,需启动其他节点的worker,配置步骤:
同样在conf目录下有一个slaves.template文件,在这个文件中添加所有需要启动worker的主机名,并重命名去掉后缀
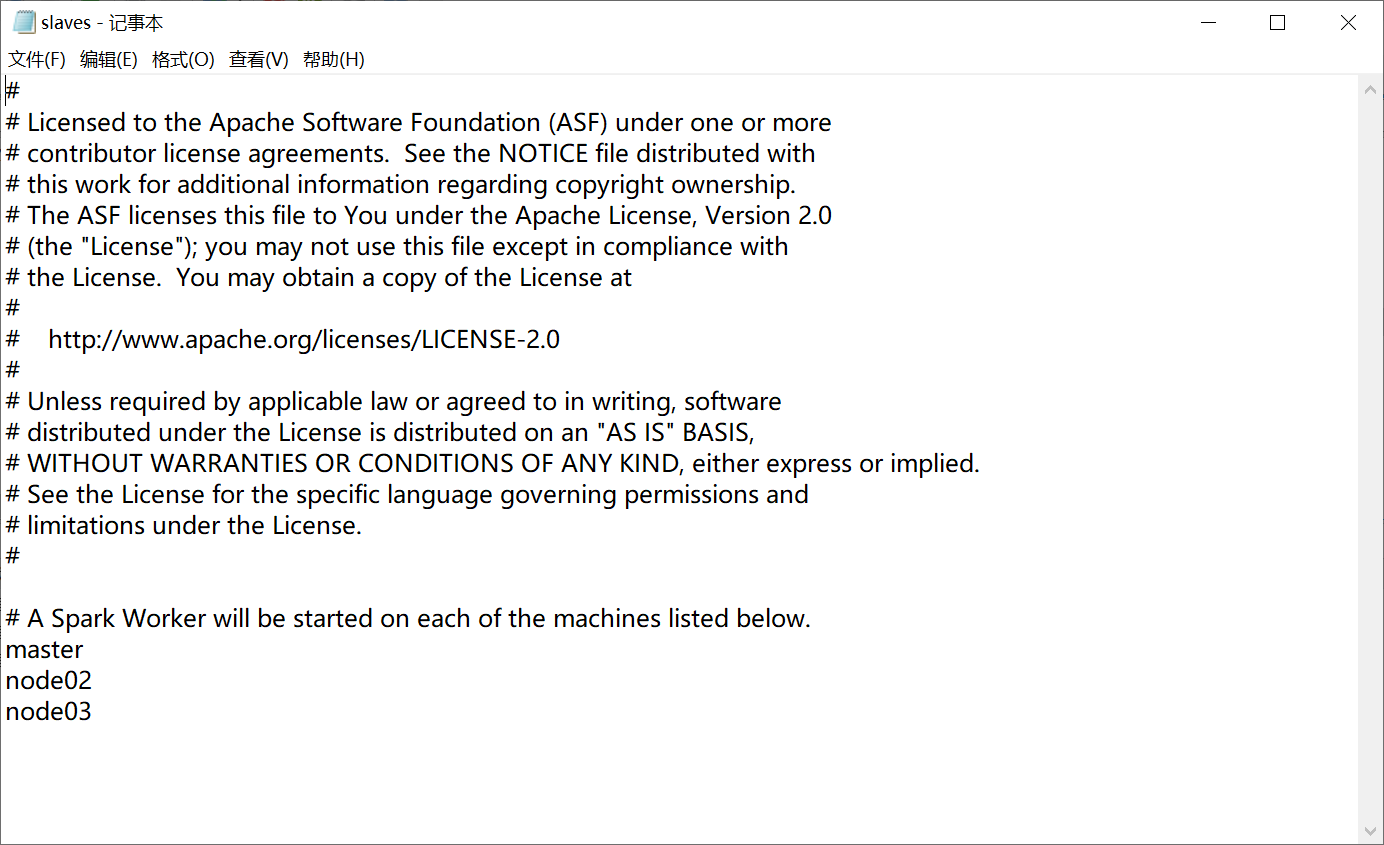
6.2 Spark是一个即用即走的工具,运行Spark程序结束后可能无法查看运行结果,过程等信息,可以配置历史服务,查看历史信息
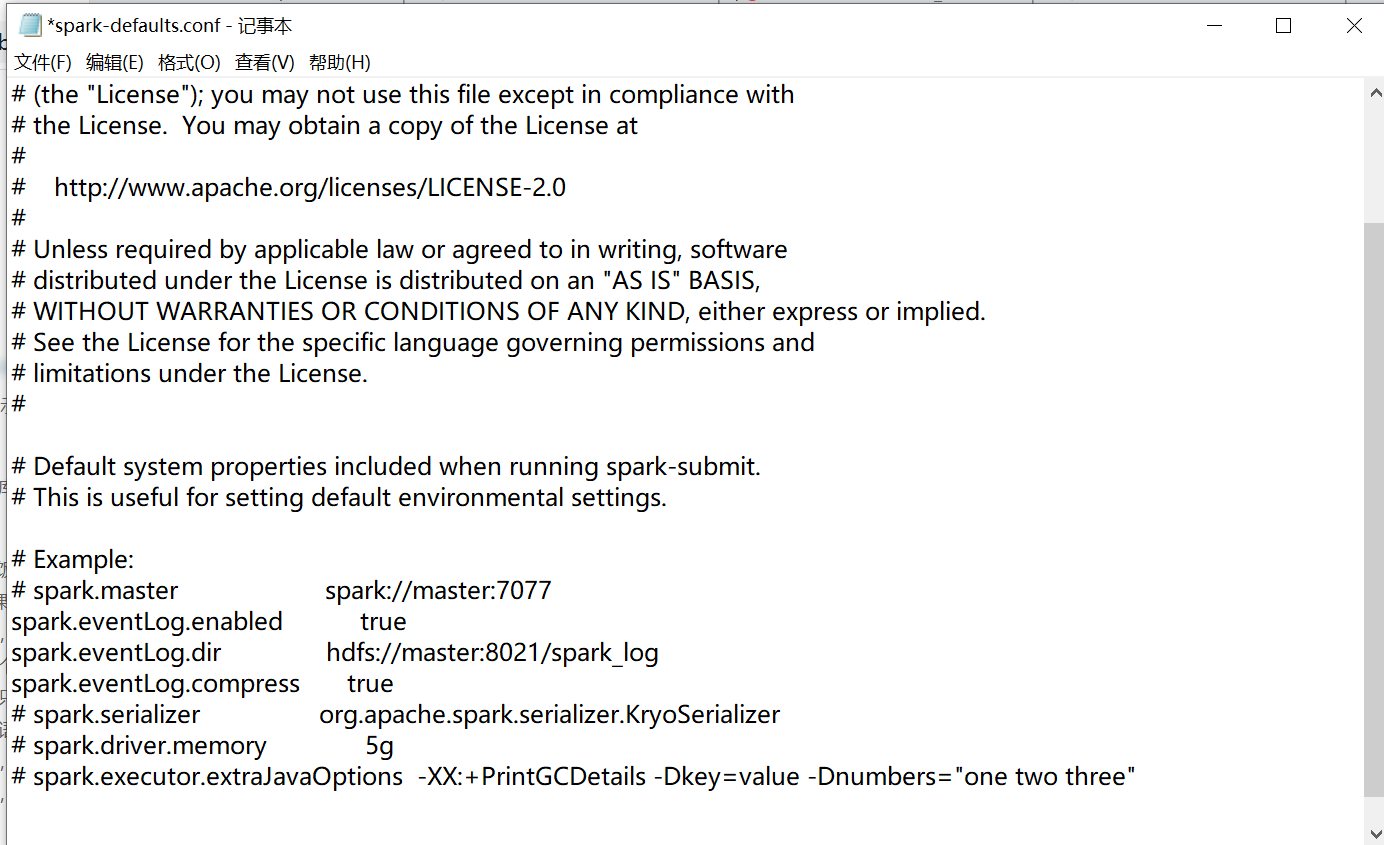
首先复制conf目录下的spark-defaults.conf.template文件并去掉后缀。编辑复制后的文件,添加以下内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:8021/spark_log
spark.eventLog.compress true
在hadoop中创建日志目录:hdfs dfs -mkdir -p /spark_log(需要首先启动hadoop集群)

7.分发
进入spark安装目录的上一级目录,输入以下命令


8.启动集群
进入spark目录下的sbin目录,执行start-all.sh命令
