前言
师姐在毕业论文《基于邻居节点耦合的信息传播研究》中提到了机器学习中的监督学习(supervised learning)和无监督学习(unsupervised learning)这一大概念。
并提出:机器学习在信息传播领域也有着广泛的运用,但在信息传播领域对于机器学习的研究只是运用机器学习的各种算法来对信息进行分类和总结,却很少涉及运用机器学习的思想来解决问题。
出于好奇,对该机器学习方面做一些简单的了解和学习,有时间还是要看看书。
正文
机器学习算法的思想
通俗来说,机器学习就是通过一大堆数据集训练一个电脑程序让他能够去更加准确地预测出下一次的结果。
参考某一博客内容,
现在比较流行的机器学习算法,基本不看参数的显著性,主要根据最终的准确率或召回率来评价模型的优劣,以逻辑回归为例

机器学习的主要思想就是:
把数据集拆分成训练集和测试集,用训练集来进行建模,测试集进行检验,最后根据混淆矩阵的总体精准度和召回率来评判模型。
监督学习
目的:在监督学习中,会知道一些数据集(输入),并且知道他们的答案(输出),其中输入输出的关系就是监督学习想要得到的结果。
在日常生活中,我们从小就被大人教授这是鸟啊、那是猪啊、这个是西瓜、南瓜,这个可以吃、那个不能吃啊之类的。我们眼里见到的这些景物食物就是机器学习中的输入,大人们告诉我们的结果就是输出,久而久之,当我们见的多了,大人们说的多了,我们脑中就会形成一个抽象的模型,下次在没有大人提醒的时候看见别墅或者洋楼,我们也能辨别出来这是房子,不能吃,房子本身也不能飞等信息。上学的时候,老师教认字、数学公式啊、英语单词等等,我们在下次碰到的时候,也能区分开并识别它们。
这就是监督学习,它在我们生活中无处不在,如下。

该图中的h 就是监督学习想要得到的结果。
监督学习又分为两类,回归问题和分类问题。
回归问题
那么「回归问题」是什么呢?
举个例子来说:现在我想预测一下房价,已经知道了一些房子的大小和价格,通过这些数据来拟合一个函数,然后把我家房子的大小输入到这个函数中,这个过程就是解决「回归问题」的过程。
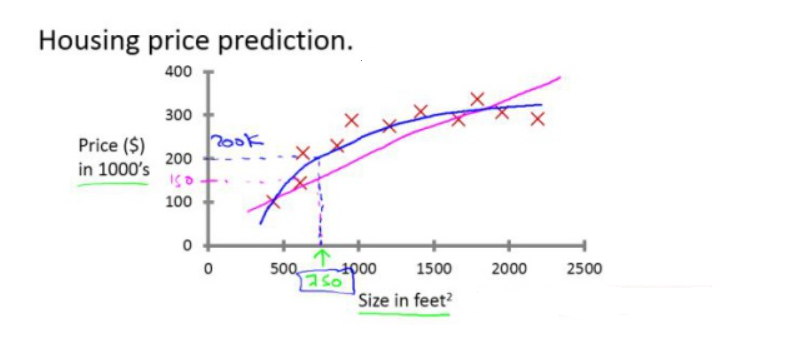
分类问题
「分类问题」呢?
举个例子:我现在看一下我的邮箱,里面有垃圾邮件和非垃圾邮件(这就是数据集),通过这些数据,我来拟合一个函数,判断我下一次收到的邮件是否为垃圾邮件。判断一封邮件是否为垃圾邮件的过程就是解决「分类问题」的过程。

无监督学习
目的:在一堆数据集中,通过他们内在的关系将他们划分成几类。
还记得前面提到过的监督学习吗?在监督学习中,你一开始就知道一些数据和他们的结果,但是不同于监督学习,无监督学习开始只知道这些数据,并不知道他们会得出什么样的结果。
举个例子:远古时期,祖先打猎吃肉,他们本身之前是没有经验而言的,当有人用很粗的石头去割动物的皮的时候,发现很难把皮隔开,但是又有人用很薄的石头去割,发现比别人更加容易的隔开动物的毛皮,于是,第二天、第三天、……,他们就知道了需要寻找比较薄的石头片来割。这些就是无监督学习的思想,外界没有经验和训练数据样本提供给它们,完全靠自己摸索。