自组织映射和弹性神经网络
自组织映射(SOM),或者你们可能听说过的Kohonen映射,是自组织神经网络的基本类型之一。自组织的能力提供了对以前不可见的输入数据的适应性。它被理论化为最自然的学习方式之一,就像我们的大脑所使用的学习方式一样,在我们的大脑中,没有预先定义的模式被认为是存在的。这些模式是在学习过程中形成的,并且在以更低的维度(如二维或一维)表示多维数据方面具有不可思议的天赋。此外,该网络以这样一种方式存储信息,即在训练集中保持任何拓扑关系。
更正式地说,SOM是一种集群技术,它将帮助我们发现大型数据集中有趣的数据类别。它是一种无监督的神经网络,神经元被排列在一个单一的二维网格中。网格必须是矩形的,例如,纯矩形或六边形。在整个迭代过程中,网格中的神经元将逐渐合并到数据点密度更高的区域。当神经元移动时,它们会弯曲和扭曲网格,直到它们更靠近感兴趣的点,并反映出数据的形状。
在这一章中,我们将讨论以下主题:
- Kohonen SOM(自组织映射)
- 使用AForge.NET
SOM引擎
简而言之,我们网格上的神经元,通过迭代,它们逐渐适应数据的形状(在我们的示例中,如下面的图所示,位于点面板左侧)。我们再来讨论一下迭代过程本身。
1.第一步是在网格上随机放置数据。我们将随机将网格的神经元放在数据空间中,如下图所示:
2.第二步是算法将选择单个数据点。
3.在第三步中,我们需要找到最接近所选数据点的神经元(数据点)。这就成了我们最匹配的单元。
4.第四步是将最匹配的单元移向该数据点。我们移动的距离是由我们的学习率决定的,每次迭代后学习率都会下降。
5.第五,我们将把最匹配单元的邻居移得更近,距离越远的神经元移动得越少。你在屏幕上看到的初始半径变量是我们用来识别邻居的。这个值,就像初始学习率一样,会随着时间的推移而降低。如果您已经启动并运行了监视器,您可以看到初始学习率随着时间的推移而降低,如下面的屏幕截图所示:
6.我们的第六步也是最后一步,是更新初始学习速率和初始半径,就像我们目前描述的那样,然后重复它。我们将继续这一进程,直到我们的数据点稳定下来并处于正确的位置。
现在我们已经有了了一些关于SOMs的直观的认识,我们再来讨论一下我们这一章要做的事情。我们选择了一个非常常见的机制来教我们的程序,那就是颜色的映射。
颜色本身是由红色、绿色和蓝色表示的三维对象,但是我们将把它们组织成二维。颜色的组织有两个关键点。首先,颜色被聚集成不同的区域,其次,具有相似属性的区域通常彼此相邻。
第二个例子更高级一些,它将使用ANN(人工神经网络);这是机器学习的一种高级形式,用于创建与呈现给它的映射相匹配的组织映射。
让我们看第一个例子。下面是我们示例的屏幕截图。正如所看到的,我们有一个随机的颜色图案,当完成时,它由一组相似的颜色组成:

如果我们成功了,我们的结果应该是这样的:

让我们从以下步骤开始:
1.我们将首先进行500次迭代来实现我们的目标。使用较小的数字可能不会产生我们最终想要的混合。例如,如果我们进行500次迭代,下面是我们的结果:
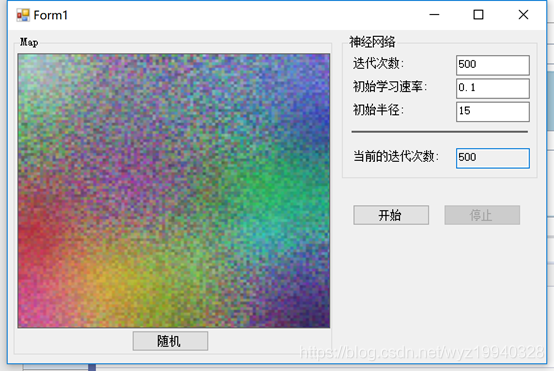
2.正如所看到的,我们离我们需要达到的目标还很远。但是我们能够更改迭代,以允许使用完全正确的设置进行试验。到了这里我们必须承认,500次的迭代远远不够,所以我把它留作练习,让你自己算出进展到哪里停止,才会让你感到满意(所以这个迭代次数是因人而异的,但可以肯定的是500次,肯定是不符合绝大多数人的要求的)
3.在设置了迭代次数之后,我们所要做的就是确保程序拥有我们想要的随机颜色模式,这可以通过单击随机按钮来实现。有了想要的模式后,只需单击Start按钮并查看结果。
4.一旦你点击开始,停止按钮将被激活,你可以随时停止进程。一旦达到指定的迭代次数,程序将自动停止。
在我们进入实际代码之前,让我们看一些组织模式的屏幕截图。我们可以通过简单地更改不同的参数来实现出色的结果,我们将在后面详细描述这些参数。
在下面的截图中,我们将迭代次数设置为3000次,初始半径为10:
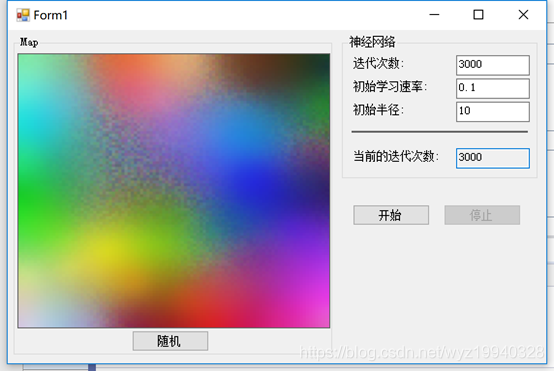
在下面的截图中,我们将迭代次数设置为4000次,初始半径为18:

在下面的截图中,我们将迭代次数设置为4000次,初始半径为5:
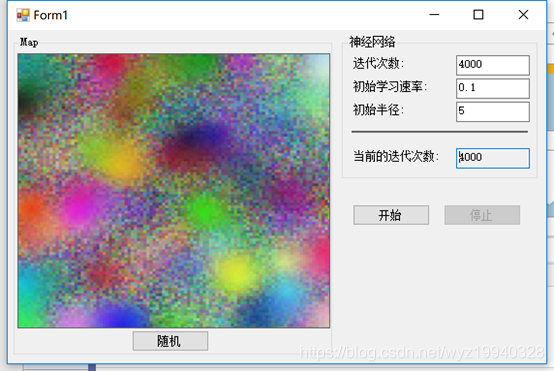
这里我们将迭代次数设为5000次,初始学习率设为0.3,初始半径设为25,如下截图所示,得到了期望的结果:
现在让我们深入研究代码。
在本例中,我们将使用AForge并使用DistanceNetwork对象。距离网络是只有一个距离的神经网络。除了用于SOM之外,它还用于一个弹性网络操作,这就是我们将要使用的来展示进程中对象之间的弹性连接。
我们将使用三个输入神经元和10000个神经元来创建我们的距离网络:
// 创建网络 network = new DistanceNetwork(3, 100 * 100);
当我们点击随机化颜色按钮来随机化颜色时:
/// <summary> /// 赋予网络随机权重 /// </summary> private void RandomizeNetwork() { if (network != null) { foreach (var neuron in (network?.Layers.SelectMany(layer => layer?.Neurons)).Where(neuron => neuron != null)) neuron.RandGenerator = new UniformContinuousDistribution(new Range(0, 255)); network?.Randomize(); } UpdateMap(); }
这里需要注意的是,我们处理的随机化范围保持在任何颜色的红、绿色或蓝色特征的范围内,即0-255之间(包含0,包含255)。
接下来,我们来看看我们的学习循环,就像这样。我们一会儿会深入研究它:
/// <summary> /// 工作内容 /// </summary> private void SearchSolution() { SOMLearning trainer = new SOMLearning(network); double[] input = new double[3]; double fixedLearningRate = learningRate / 10; double driftingLearningRate = fixedLearningRate * 9; int i = 0; while (!needToStop) { trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate; trainer.LearningRadius = radius * (iterations - i) / iterations; if (rand != null) { input[0] = rand.Next(256); input[1] = rand.Next(256); input[2] = rand.Next(256); } trainer.Run(input); // 每50次迭代更新一次map if ((i % 10) == 9) { UpdateMap(); } i++; SetText(currentIterationBox, i.ToString()); if (i >= iterations) break; } EnableControls(true); }
如果仔细观察,会发现我们创建的第一个对象是SOMLearning对象。这个对象是为正方形空间学习而优化的,这意味着它期望它所处理的网络具有与其宽度相同的高度。这使得计算网络神经元数量的平方根变得更加容易:
SOMLearning trainer = new SOMLearning(network);
接下来,我们需要创建变量来保存红色、绿色和蓝色的输入颜色,从中我们将不断地随机化输入颜色,以实现我们的目标:
if (rand != null) { input[0] = rand.Next(256); input[1] = rand.Next(256); input[2] = rand.Next(256); }
一旦我们进入while循环,我们将不断地更新变量,直到我们达到所选择的迭代总数。在这个更新循环中,会发生一些事情。首先,我们将更新学习速率和学习半径,并将其存储在我们的SOMLearning对象:
trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate;
trainer.LearningRadius = radius * (iterations - i) / iterations;
学习率决定了我们的学习速度。学习半径会对视觉输出产生非常显著的影响,它决定了相对于获胜神经元多少距离,需要更新的神经元数量。指定半径的圆由神经元组成,神经元在学习过程中不断更新。一个神经元离获胜神经元越近,它接收到的更新信息就越多。请注意,如果在实验中,将该值设置为零,那么只能更新获胜神经元的权重,而不能更新其他神经元的权重。
现在我们对这个迭代进行一次训练,并将Input数组传递给它:
trainer.Run(input);
让我们谈一下学习。正如我们所提到的,每次迭代都将尝试和学习越来越多的信息。这个学习迭代返回一个学习偏差,即神经元的权重和输入向量Input的差值。如前所述,距离是根据与获胜神经元之间的距离来测量的。过程如下。
训练器运行一次学习迭代,找到获胜的神经元(权重值与Input中提供的值最接近的神经元),并更新其权重。它还会更新相邻神经元的权重。随着每次学习迭代的进行,网络越来越接近最优解。
接下来是运行应用程序的屏幕截图。在实时调试和诊断工具中,可以看到我们是如何记录每次迭代的,更新地图时使用的颜色值,以及学习速率和学习半径。
由于SOM是自组织的,我们的第二个例子会更加形象。它能帮助我们更好地理解幕后所发生的事情。
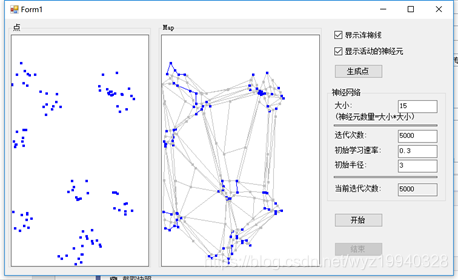
在本例中,我们将再次使用AForge。并构建一个二维平面的对象,组织成几个组。我们将从一个单独的位置开始,直观地得到这些形状的位置。这与我们的颜色示例在概念上是相同的,它使用了三维空间中的点,只是这次,我们的点是二维的。可视化在map面板中,这是一个自顶向下的视图,用于查看二维空间中发生的事情,从而获得一个一维图形视图。
起初,SOM网格中的神经元从随机位置开始,但它们逐渐被揉捏成我们数据形状的轮廓。这是一个迭代的过程,我已经在迭代过程的不同地方截屏,向大家展示了发生了什么。当然你也可以自己运行这个示例来实时查看它。
我们将运行500次迭代来展示演进。我们将从一个空白的白色面板得到一个类似的点的面板:
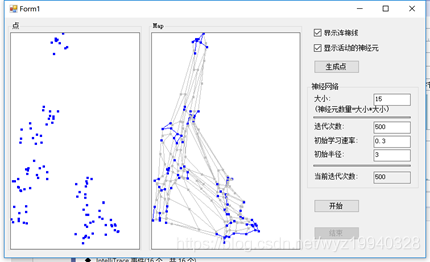
在我们点击开始按钮,我们将看到这些点开始通过移动到正确的位置来组织自己,希望这将反映出我们所指定的点:
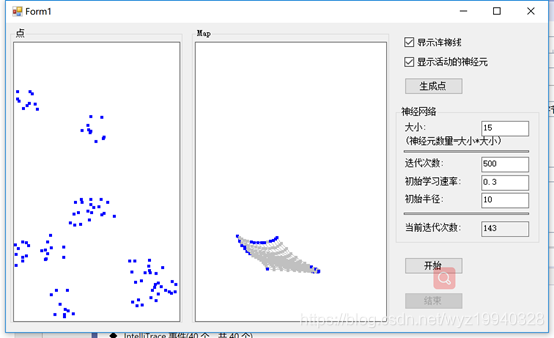
经过262次迭代:
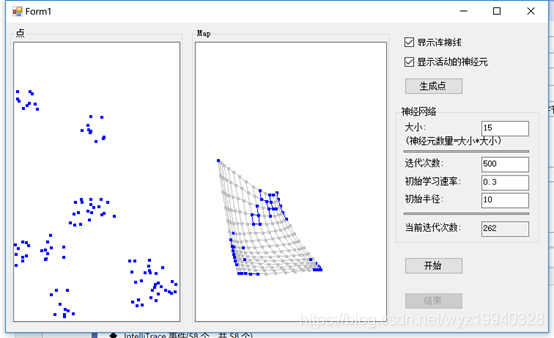
经过343次迭代:
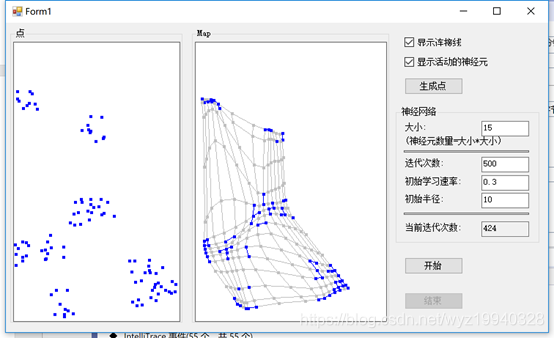
在完成之后,我们可以看到对象已经像我们最初创建的模式那样组织了它们自己。蓝色的点是活跃的神经元,浅灰色的点是不活跃的神经元,画的线是神经元之间的弹性连接。嗯,这有些像《黑客帝国》中的那个绿色的数据流。如果你看到足够仔细,是能够看到3D效果的。
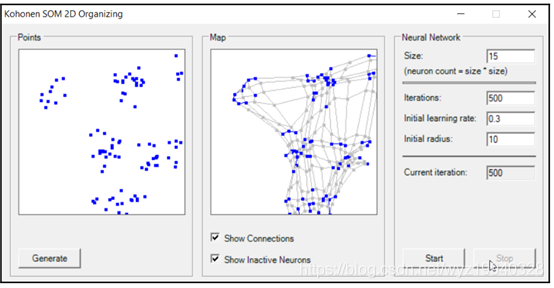
如果你窗体中没有显示连接和不活跃的神经元,你会看到map中的组织模式与我们的目标达到了相同的集群,对我们来说这意味着成功:

那么这一切究竟是如何工作的呢。像往常一样,让我们来看看我们的主执行循环。正如我们所看到的,我们将使用与前面讨论的相同的DistanceNetwork和SOMLearning对象:
/// <summary> /// 工作内容 /// </summary> private void SearchSolution() { // 创建网络 DistanceNetwork network = new DistanceNetwork(2, networkSize * networkSize); // 设置随机生成器范围 foreach (var neuron in network.Layers.SelectMany(layer => layer.Neurons)) neuron.RandGenerator = new UniformContinuousDistribution( new Range(0, Math.Max(pointsPanel.ClientRectangle.Width, pointsPanel.ClientRectangle.Height))); // 创建学习算法 SOMLearning trainer = new SOMLearning(network, networkSize, networkSize); // 创建map map = new int[networkSize, networkSize, 3]; double fixedLearningRate = learningRate / 10; double driftingLearningRate = fixedLearningRate * 9; // 迭代次数 int i = 0; while (!needToStop) { trainer.LearningRate = driftingLearningRate * (iterations - i) / iterations + fixedLearningRate; trainer.LearningRadius = (double)learningRadius * (iterations - i) / iterations; // 开始纪元的训练 trainer.RunEpoch(trainingSet); UpdateMap(network); i++; // 设置当前迭代的信息 SetText(currentIterationBox, i.ToString()); // stop ? if (i >= iterations) break; } // 启用设置控件 EnableControls(true); }
正如我们前面提到的,LearningRate和LearningRadius在每次迭代中都在不断发展。这一次,让我们来谈谈训练器的RunEpoch方法。这个方法虽然非常简单,但其设计目的是获取一个输入值向量,然后为该迭代返回一个学习偏差(正如我们现在看到的,有时也称为epoch)。它通过计算向量中的每个输入样本来实现这一点。学习误差是神经元的权值和输入之间的绝对差。这种差异是根据获胜神经元之间的距离来测量的。如前所述,我们针对一个学习迭代/历元运行此计算,找到获胜者,并更新其权重(以及邻居权重)。应该指出的是,当说赢家时,指的是权重值与指定输入向量最接近的神经元,也就是给网络输入的最小距离。
接下来,将重点介绍如何更新映射本身;我们计算的项目应该与初始输入向量(点)匹配:
private void UpdateMap(DistanceNetwork network) { // 得到第一层 Layer layer = network.Layers[0]; // 加锁 Monitor.Enter(this); // 遍历所有神经元 for (int i = 0; i < layer.Neurons.Length; i++) { Neuron neuron = layer.Neurons[i]; int x = i % networkSize; int y = i / networkSize; map[y, x, 0] = (int)neuron.Weights[0]; map[y, x, 1] = (int)neuron.Weights[1]; map[y, x, 2] = 0; } // 收集活动的神经元 for (int i = 0; i < pointsCount; i++) { network.Compute(trainingSet[i]); int w = network.GetWinner(); map[w / networkSize, w % networkSize, 2] = 1; } // 解锁 Monitor.Exit(this); mapPanel.Invalidate(); }
从这段代码中可以看到,我们得到了第一层,计算了所有神经元的map,收集了活动神经元,这样我们就可以确定获胜者,然后更新map。
我们确定获胜者的过程,实际上就是寻找权重与网络输入距离最小的神经元,就是这么简单,一定不要把简单的问题复杂化,就好像那个雨滴与硕士博士教授的笑话一样。
总结
在这一章中,我们学习了如何利用SOMs和弹性神经网络的力量。现在我们已经正式从机器学习跨入了神经网络的阶段。