我们都听说过深度学习,但是有多少人知道深度信念网络是什么?让我们从本章开始回答这个问题。深度信念网络是一种非常先进的机器学习形式,其意义正在迅速演变。作为一名机器学习开发人员,对这个概念有一定的了解是很重要的,这样当您遇到它或它遇到您时就会很熟悉它!
在机器学习中,深度信念网络在技术上是一个深度神经网络。我们应该指出,深度的含义,当涉及到深度学习或深度信念时,意味着网络是由多层(隐藏的单位)组成的。在深度信念网络中,这些连接在一层内的每个神经元之间,而不是在不同的层之间。一个深度信念网络可以被训练成无监督学习,以概率重建网络的输入。这些层就像“特征检测器”一样,可以识别或分类图像、字母等等。
在本章,我们将包括:
受限玻尔兹曼机
在c#中创建和培训一个深度信念网络
受限玻尔兹曼机
构建深度信念网络的一种流行方法是将其作为受限玻尔兹曼机(RBMs)的分层集合。这些RMBs的功能是作为自动编码器,每个隐藏层作为下一个可见层。深度信念网络将为训练前阶段提供多层RBMs,然后为微调阶段提供一个前馈网络。训练的第一步将是从可见单元中学习一层特性。下一步是从以前训练过的特性中获取激活,并使它们成为新的可见单元。然后我们重复这个过程,这样我们就可以在第二个隐藏层中学习更多的特性。然后对所有隐藏层继续执行该过程。
我们应该在这里提供两条信息。
首先,我们应该稍微解释一下什么是自动编码器。自动编码器是特征学习的核心。它们编码输入(输入通常是具有重要特征的压缩向量)和通过无监督重构的数据学习。
其次,我们应该注意到,将RBMs堆积在一个深度信念网络中只是解决这个问题的一种方法。将限制线性单元(ReLUs)叠加起来,再加上删除和训练,然后再加上反向传播,这又一次成为了最先进的技术。我再说一遍,因为30年前,监督方法是可行的。与其让算法查看所有数据并确定感兴趣的特征,有时候我们人类实际上可以更好地找到我们想要的特征。
我认为深度信念网络的两个最重要的特性如下:
l 有一个有效的,自上而下的逐层学习过程,生成权重。它决定了一个层中的变量如何依赖于它上面层中的变量。
l 当学习完成后,每一层变量的值都可以很容易地通过一个自底向上的单次遍历推断出来,该遍历从底层的一个观察到的数据向量开始,并使用生成权值逆向重构数据。
说到这里,我们现在来谈谈RBMs以及一般的玻尔兹曼机。
玻尔兹曼机是一个递归神经网络,具有二进制单元和单元之间的无向边。无向是指边(或链接)是双向的,它们没有指向任何特定的方向。
下面是一个带有无向边的无向图:
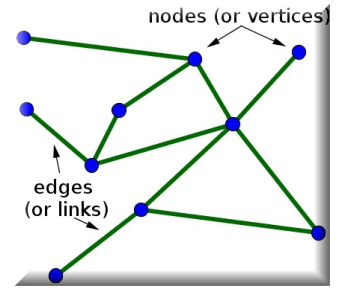
玻尔兹曼机是最早能够学习内部表征的神经网络之一,只要有足够的时间,它们就能解决难题。但是,它们不擅长伸缩,这就引出了我们的下一个主题,RBMs。
引入RBMs是为了解决玻尔兹曼机器无法伸缩的问题。它们有隐藏层,每个隐藏单元之间的连接受到限制,但不在这些单元之外,这有助于提高学习效率。更正式地说,我们必须深入研究一些图论来正确地解释这一点。
RBMs的神经元必须形成二分图,这是图论的一种更高级的形式;来自这两组单元(可见层和隐藏层)中的每一组的一对节点之间可能具有对称连接。任何组中的节点之间都不能有连接。二分图,有时称为生物图,是将一组图顶点分解为两个不相交的集合,使同一集合内没有两个顶点相邻。
这里有一个很好的例子,它将有助于可视化这个主题。
注意同一组内没有连接(左边是红色的,右边是黑色的),但两组之间有连接:
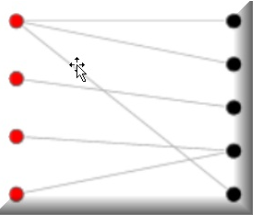
更正式地说,RBM是所谓的对称二分图。这是因为所有可见节点的输入都传递给所有隐藏节点。我们说对称是因为每个可见节点都与一个隐藏节点相关。
假设我们的RBM显示了猫和狗的图像,我们有两个输出节点,每个动物一个。在我们向前通过学习,我们的RBM问自己:“对于我看到的像素,我应该向猫或狗发送更强的权重信号吗?”在它想知道“作为一只狗,我应该看到哪个像素分布?”我的朋友们,这就是今天关于联合概率的课: 在给定A和给定X的情况下X的同时概率。在我们的例子中,这个联合概率表示为两层之间的权重,是RBMs的一个重要方面。
我们现在来谈谈重构,这是rbms的一个重要部分。在我们所讨论的示例中,我们正在学习一组图像出现哪些像素组(即打开)。当一个隐藏层节点被一个重要的权重激活时(无论决定打开它的权重是什么),它表示正在发生的事情的共同发生,在我们的例子中,是狗还是猫。如果这是一只猫,尖耳朵、圆脸、小眼睛可能就是我们要找的。大耳朵+长尾巴+大鼻子可能会让你的形象变成一只狗。这些激活表示RBM“认为”原始数据的样子。实际上,我们正在重建原始数据。
我们还应该迅速指出,RBM有两个偏见,而不是一个。这是非常重要的,因为这是区别于其他自动编码算法。隐藏的偏差帮助我们的RBM在向前传递时产生我们需要的激活,而可见的层偏差帮助我们在向后传递时学习正确的重构。隐藏的偏差很重要,因为它的主要工作是确保无论我们的数据有多么稀疏,一些节点都会被触发。稍后您将看到这将如何影响一个深层信仰网络的梦想。
分层
一旦我们的RBM了解了输入数据的结构,它与在第一个隐藏层中进行的激活相关,数据就会传递到下一个隐藏层。第一个隐藏层然后成为新的可见层。我们在隐藏层中创建的激活现在成为我们的输入。它们将乘以新隐藏层中的权重,以产生另一组激活。
这个过程在我们的网络的所有隐藏层中继续进行。隐藏层变成可见层,我们有另一个隐藏层,我们将使用它的权重,然后重复。每个新的隐藏层都会产生调整后的权重,直到我们能够识别来自前一层的输入为止。
为了更详细地说明,这在技术上被称为无监督的、贪婪的、分层的培训。改进每一层的权值不需要输入,这意味着不涉及任何类型的外部影响。这进一步意味着我们应该能够使用我们的算法来训练以前没有见过的无监督数据。
正如我们一直强调的,我们拥有的数据越多,我们的结果就越好!随着每一层图像的质量越来越好,也越来越准确,我们就可以更好地通过每一个隐藏层来提高我们的学习能力,而权重的作用就是引导我们在学习的过程中进行正确的图像分类。
但是在讨论重构时,我们应该指出,每次重构工作中的一个数字(权重)都是非零的,这表明我们的RBM从数据中学到了一些东西。在某种意义上,您可以像处理百分比指标一样处理返回的数字。数字越大,算法对它所看到的东西就越有信心。记住,我们有我们要返回的主数据集,我们有一个参考数据集用于我们的重建工作。当我们的RBM遍历每个图像时,它还不知道它在处理什么图像;这就是它想要确定的。
让我们花一点时间来澄清一些事情。当我们说我们使用贪婪算法时,我们真正的意思是我们的RBM将采用最短路径来获得最佳结果。我们将从所看到的图像中随机抽取像素,并测试哪些像素引导我们找到正确答案。
RBM将根据主数据集(测试集)测试每个假设,这是我们的正确最终目标。请记住,每个图像只是我们试图分类的一组像素。这些像素包含了数据的特征和特征。例如,一个像素可以有不同的亮度,其中深色像素可能表示边框,浅色像素可能表示数字,等等。
但如果事情不像我们想的那样,会发生什么呢?如果我们在给定步骤中学到的东西不正确会发生什么?如果出现这种情况,就意味着我们的算法猜错了。我们要做的就是回去再试一次。这并不像看上去那么糟糕,也不像看上去那么耗时。
当然,错误的假设会带来时间上的代价,但最终的目标是我们必须提高学习效率,并在每个阶段减少错误。每一个错误的加权连接都会受到惩罚,就像我们在强化学习中所做的那样。这些连接会减少重量,不再那么强。希望下一个遍历可以在减少误差的同时提高精度,并且权重越大,影响就越大。
假设我们对数字图像进行分类,也就是数字。有些图像会有曲线,比如2、3、6、8、9等等。其他数字,如1、4和7,则不会。这样的知识是非常重要的,因为我们的RBM,会用它来不断提高自己的学习,减少错误。如果我们认为我们处理的是数字2,那么这个路径的权值就会比其他路径的权值更重。这是一个极端的过度简化,但希望它足以帮助你理解我们将要开始的内容。
当我们把所有这些放在一起,我们现在有了一个深层信仰网络的理论框架。虽然我们比其他章节更深入地研究了理论,但是正如您所看到的我们的示例程序所工作的那样,它将开始变得有意义。您将更好地准备在应用程序中使用它,了解幕后发生的事情。
为了展示深度信念网络和RBMs,我们将使用Mattia Fagerlund编写的出色的开源软件SharpRBM。这个软件对开源社区做出了不可思议的贡献,我毫不怀疑您将花费数小时甚至数天的时间来使用它。这个软件附带了一些令人难以置信的演示。在本章中,我们将使用字母分类演示。
下面的截图是我们的深度信念测试应用程序。有没有想过电脑睡觉时会梦到什么?
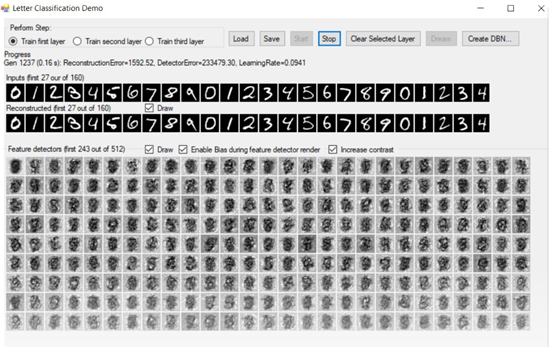
程序的左上角是我们指定要训练的图层的区域。我们有三个隐藏层,它们都需要在测试之前进行适当的训练。我们可以一次训练一层,从第一层开始。训练得越多,你的系统就会越好:

训练选项之后的下一部分是我们的进展。当我们在训练时,所有相关的信息,如生成,重构误差,检测器误差,学习率,都显示在这里:

下一个是我们的特性检测器的绘图,如果选中Draw复选框,它将在整个训练过程中更新自己:

当开始训练一个层时,我们将注意到重构和特征检测器基本上是空的。他们会随着我们的训练不断完善自己。记住,我们正在重建我们已经知道是真实的东西!随着训练的继续,重构的数字变得越来越清晰,我们的特征检测器也越来越清晰:
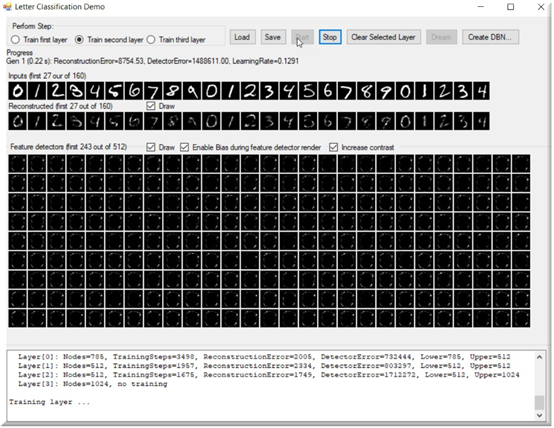
下面是训练期间应用程序的快照。如图所示,这是在第31代,重建的数字是非常明确的。
它们仍然不完整或不正确,但可以看到我们取得了多大的进步:

电脑在做梦?
电脑做梦时会梦到什么?对我们来说,直觉是一个特征,它允许我们看到计算机在重构阶段在想什么。当程序试图重建我们的数字时,特征检测器本身将在整个过程中以各种形式出现。我们在dream window中显示的就是这些形式(红色圆圈表示):

我们花了很多时间查看应用程序的屏幕截图。我想是时候看看代码了。让我们先看看如何创建DeepBeliefNetwork对象本身:
DeepBeliefNetwork = new DeepBeliefNetwork(28 * 29, 500, 500, 1000);
一旦创建了这个,我们需要创建我们的网络训练器,我们根据我们正在训练的层的权重来做这件事:
DeepBeliefNetworkTrainer trainer = new DeepBeliefNetworkTrainer(DeepBeliefNetwork, DeepBeliefNetwork?.LayerWeights?[layerId], inputs);
这两个对象都在我们的主TrainNetwork循环中使用,这是应用程序中大部分活动发生的部分。这个循环将继续,直到被告知停止。
private void TrainNetwork(DeepBeliefNetworkTrainer trainer) { try { Stopping = false; ClearBoxes(); _unsavedChanges = true; int generation = 0; SetThreadExecutionState(EXECUTION_STATE.ES_CONTINUOUS | EXECUTION_STATE.ES_SYSTEM_REQUIRED);
while (Stopping == false) { Stopwatch stopwatch = Stopwatch.StartNew(); TrainingError error = trainer?.Train(); label1.Text = string.Format( "Gen {0} ({4:0.00} s): ReconstructionError= {1:0.00}, DetectorError={2:0.00}, LearningRate={3:0.0000}", generation, error.ReconstructionError, error.FeatureDetectorError, trainer.TrainingWeights.AdjustedLearningRate, stopwatch.ElapsedMilliseconds / 1000.0); Application.DoEvents(); ShowReconstructed(trainer); ShowFeatureDetectors(trainer); Application.DoEvents(); if (Stopping) { break; }
generation++; }
DocumentDeepBeliefNetwork(); }
finally { SetThreadExecutionState(EXECUTION_STATE.ES_CONTINUOUS); } }
在前面的代码中,我们突出显示了trainer.Train()方法,它是一个基于数组的学习算法,如下所示:
public TrainingError Train() { TrainingError trainingError = null; if (_weights != null) { ClearDetectorErrors(_weights.LowerLayerSize, _weights.UpperLayerSize); float reconstructionError = 0; ParallelFor(MultiThreaded, 0, _testCount, testCase => { float errorPart = TrainOnSingleCase(_rawTestCases,_weights?.Weights, _detectorError,testCase,
_weights.LowerLayerSize,_weights.UpperLayerSize, _testCount); lock (_locks?[testCase % _weights.LowerLayerSize]) { reconstructionError += errorPart; } }
); float epsilon = _weights.GetAdjustedAndScaledTrainingRate(_testCount); UpdateWeights(_weights.Weights,_weights.LowerLayerSize, _weights.UpperLayerSize,_detectorError, epsilon); trainingError = new TrainingError(_detectorError.Sum(val =>Math.Abs(val)), reconstructionError); _weights?.RegisterLastTrainingError(trainingError); return trainingError; }
return trainingError; }
此代码使用并行处理(突出显示的部分)并行地训练单个案例。这个函数负责处理输入层和隐藏层的更改,正如我们在本章开头所讨论的。它使用TrainOnSingleCase函数,如下图所示:
private float TrainOnSingleCase(float[] rawTestCases, float[] weights, float[] detectorErrors, int testCase, int lowerCount, int upperCount, int testCaseCount) { float[] model = new float[upperCount]; float[] reconstructed = new float[lowerCount]; float[] reconstructedModel = new float[upperCount]; int rawTestCaseOffset = testCase * lowerCount; ActivateLowerToUpperBinary(rawTestCases, lowerCount, rawTestCaseOffset, model, upperCount, weights); // Model ActivateUpperToLower(reconstructed, lowerCount, model,upperCount, weights); // Reconstruction ActivateLowerToUpper(reconstructed, lowerCount, 0, reconstructedModel, upperCount, weights); // Reconstruction model return AccumulateErrors(rawTestCases, lowerCount,rawTestCaseOffset, model, upperCount, reconstructed, reconstructedModel, detectorErrors); // Accumulate detector errors }
最后,我们在处理过程中积累错误,这就是我们的模型应该相信的和它实际做的之间的区别。
显然,错误率越低越好,对于我们的图像重建最准确。AccumulateErrors函数如下所示:
private float AccumulateErrors(float[] rawTestCases, int lowerCount, int rawTestCaseOffset, float[] model, int upperCount, float[] reconstructed, float[] reconstructedModel, float[] detectorErrors) { float reconstructedError = 0; float[] errorRow = new float[upperCount]; for (int lower = 0; lower < lowerCount; lower++) { int errorOffset = upperCount * lower; for (int upper = 0; upper < upperCount; upper++) { errorRow[upper] = rawTestCases[rawTestCaseOffset + lower] * model[upper] + // 模型应该相信什么 -reconstructed[lower] * reconstructedModel[upper]; // 模型真正相信什么 } lock (_locks[lower]) { for (int upper = 0; upper < upperCount; upper++) { detectorErrors[errorOffset + upper] -= errorRow[upper]; } } reconstructedError += Math.Abs(rawTestCases[rawTestCaseOffset + lower] - reconstructed[lower]); } return reconstructedError; }
总结
在本章中,我们学习了RBMs、一些图论,以及如何在c#中创建和训练一个深入的信念网络。我建议你对代码进行试验,将网络层训练到不同的阈值,并观察计算机在重构时是如何做梦的。记住,你训练得越多越好,所以花时间在每一层上,以确保它有足够的数据来进行准确的重建工作。
警告:如果启用特性检测器和重构输入的绘图功能,性能将会极速下降。
如果你正在尝试训练你的图层,你可能希望先在没有可视化的情况下训练它们,以减少所需的时间。相信我,如果你把每一个关卡都训练成高迭代,那么可视化会让你感觉像一个永恒的过程!在你前进的过程中,随时保存你的网络。
在下一章中,我们将学习微基准测试,并使用有史以来最强大的开源微基准测试工具包之一!