网络转载而来,仅供个人记录学习使用。
-----------------------------------------------------------------------------------------
InfluxDB基本概念
1. Influxdb(时序数据库)是一个开源分布式时序、时间和指标数据库,使用Go语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展,着力于高性能地查询与存储时序型数据,是InfluxData的核心产品。
2. Influxdb应用在性能监控,应用程序指标,物联网传感器数据和实时分析等的后端存储。
常见的使用场景:监控数据统计。比如每毫秒记录一下电脑内存的使用情况,进而根据统计的数据,利用图形化界面制作内润使用情况的折线图。
3. Influxdb完整的上下游产业还包括Chronograf、Telegraf、Kapacitor。
与传统关系型数据库(MySQL)基础概念区别
| 概念 | MySQL | InfluxDB |
| 数据库 | database | database |
| 表 | table | measurement |
| 列 | column | time(唯一主键)tags(带索引)、fields(不带索引) |
point(表中的一行数据)的数据结构由time(时间戳)、tags(标签)、fields(数据)三部分组成。
具体解释: time:数据记录的时间,是主索引,自动生成。
tags:各种有索引的属性。
fields:各种value值,没有索引的属性。
分类解释: tag set:不同的每组tag key和tag value的集合。
field set:每组field key和field value的集合。
retention policy: 数据存储策略(默认策略为autogen),InfluxDB没有删除数据操作,规定数据的保留时间来达到清除数据的目的。
series:相当于是InfluxDB中一些数据的集合,在同一个database中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
示例如下:
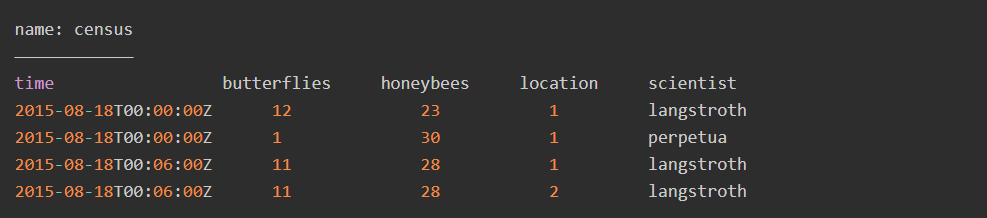
其中census是measurement,butterflies和honeybees是field key,location和scientist是tag key。示例中,有三个tag set。
注意事项:
-
-
- 所有在数据库中的数据,都需要通过图表来展示,而series就表示这个表里面的数据,可以在图表上画成几条线:通过tags排列组合算出来。
- influxdb不需要像传统数据库一样创建各种表,其表的创建主要是通过第一次数据插入时自动创建。
- fields中的 value 基本不用于索引。
- tag只能为字符串类型。
- field类型无限制。
- 不支持join
- 支持连续查询操作(汇总统计数据)。
-
保留策略(retention policy)
- 每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,在集群中的副本个数为1,之后用户可以自己设置(查看、新建、修改、删除),例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
- 每个数据库可以有多个过期策略: show retention policies on "db_name"。
-
Shard 在 influxdb中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。 - 建议在数据库建立的时候设置存储策略,不建议设置过多且随意切换。create database testdb2 with duration 30d
存储目录
influxdb的数据存储有三个目录,分别是meta、wal、data:
- meta 用于存储数据库的一些元数据,meta目录下有一个meta.db文件。
- wal目录存放与写日志文件,以.wal结尾。
- data目录存放实际存储的数据文件,以.tsm结尾。
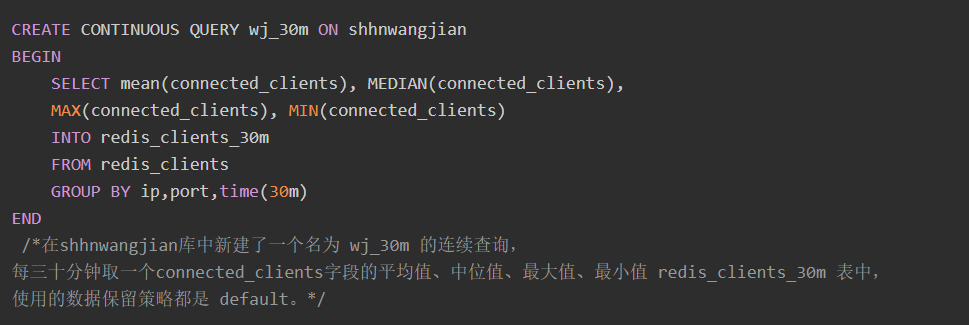
连续查询
influxdb的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含SELECT等关键词。influxdb会将查询结果放在指定的数据表中。
目的:使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低InfluxDB的系统占用量。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
当数据超过保存策略里指定的时间之后就会被删除,但是这时候可能并不想数据被完全删掉,可以使用连续查询将数据聚合存储。
安装及启动
1. 可通过官网下载各平台版本:https://portal.influxdata.com/downloads/
以windows为例,选择对应平台的influxdb:https://dl.influxdata.com/influxdb/releases/influxdb-1.7.6_windows_amd64.zip
2. 下载后解压,得到 influxd.exe、influx.exe、influxdb.conf 等文件,data、meta、wal 是自己建立的文件夹:

3. influx.exe 表示客户端,influxd.exe 表示服务端,influx_inspect.exe 表示查看工具,influx_stress.exe 表示压力测试工具,influx_tsm 表示数据库转换工具(将数据库从 b1 或 bz1 格式转换为 tsm1 格式),influxdb.conf 是配置文件,需要修改该文件,主要是三个路径修改:
[meta]
# Where the metadata/raft database is stored
dir = "C:/Install/influxdb-1.7.6-1/meta"
[data]
# The directory where the TSM storage engine stores TSM files.
#/var/lib/influxdb/data
dir = "C:/Install/influxdb-1.7.6-1/data"
# The directory where the TSM storage engine stores WAL files.
#/var/lib/influxdb/wal
wal-dir = "C:/Install/influxdb-1.7.6-1/wal"
4. 启动服务端 influxd.exe
5. 打开客户端 influx.exe
操作InfluxDB
可以通过SQL-like语言直接操作influxdb
1. 库操作
- 显示数据库
show databases
- 新建数据库
create database db1

- 删除数据库
drop databse db1
- 使用指定数据库
use mydb

2. 表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是MEASUREMENTS,MEASUREMENTS的功能与传统数据库中的表一致,因此我们也可以将MEASUREMENTS称为InfluxDB中的表。
- 显示所有表
show measurements
- 新建表
InfluxDB中没有显式的新建表的语句,只能通过insert数据的方式来建立新表。
insert disk_all,hostname=server01 value=446515834240
其中disk_all就是表名,hostname是索引(tag),value=xx是记录值(field),记录值可以有多个,系统自带追加时间戳


添加数据时,自己也可以写入时间戳
insert disk_all, hostname=server02 value=446515834240 1435362189575692181

此时time默认显示为19位的ns级别的时间戳,查看不方便,通过如下命令更改:
precision rfc3339

- 删除表
drop measurement disk_all
总结一下语句写法:
- insert + measurement + "," + tag=value,tag=value + 空格 + field=value,field=value
- tag与tag之间用逗号分隔;field与field之间用逗号分隔
- tag与field之间用空格分隔
- tag都是string类型,不需要引号将value包裹
- field如果是string类型,需要加引号
常见的查询tag keys语法:
show tag keys on <database> from <measurement>
查询tag values的语法:
show tag values on <database> from <measurement> with KEY [ [<operator> "<tag_key>" | <regular_expression>] | [IN ("<tag_key1>","<tag_key2")]] [WHERE <tag_key> <operator> ['<tag_value>' | <regular_expression>]] [LIMIT_clause] [OFFSET_clause]
with key后面带上查询条件,必须存在。
查看field key的语法:
show field keys on <database> from <measurement>
其中field的四种类型的指定方式如下:
| 类型 | 方式 | 示例 |
| float | 数字 | user_id=10 |
| int | 数字i | age=18i |
| boolean | true/false | boy=true |
| String | "" or '' | email=test@163.com |
查看series的语法:
show series on <database> from <measurement>
3. 数据保存策略(Retention Policies)
influxDB是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
- 创建Retention Policies
retention policy依托于database存在,所以,创建保存策略的时候,需要指定具体是哪个数据库,语法如下:
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
注意事项:
- retention_policy_name:策略名(自定义的)
- database_name:一个必须存在的数据库名
- duration:定义的数据保存时间,最低为1h,如果设置为0,表示数据持久不失效(默认的策略就是这样的)
- REPLICATION:定义每个point保存的副本数,默认为1
- default:表示将这个创建的保存策略设置为默认的
下面创建一个数据保存一年的策略:
create retention policy "1Y" on test duration 366d replication 1
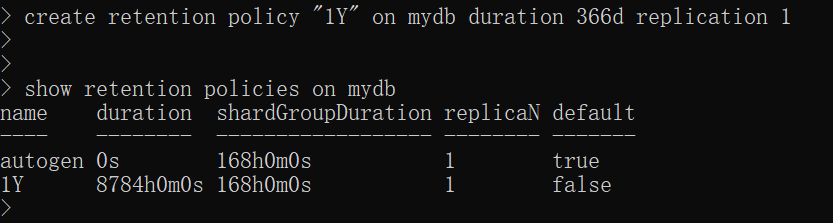
- 查看保存策略
show retention policies on <database name>
- 修改保存策略
ALTER RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> SHARD DURATION <duration> DEFAULT
- 删除保存策略
DROP RETENTION POLICY <retention_policy_name> ON <database_name>
关于保存策略,主要包括三个信息: 数据保存时间,数据分片时间,副本数。
1. 数据保存时间: duration这一列,就是这个策略定义的数据保存时间。如果当前时间与一条记录的time(这条记录的时间戳)之间差值大于duration,那么这条数据就会被删除掉。
默认的保存策略autogen中的duration=0,这表示这条数据不会被删除。
2. 数据分片时间:指每个分片的时间跨度,比如数据保存最近24小时的,每个小时就是一个分片。系统指定的方案如下:
| Retention Policy`s DURATION | Shard Group Duration |
| < 2 days | 1 hour |
| >= 2 days and <= 6 months | 1 day |
| > 6 months | 7 days |
3. 副本数:指定了数据有多少个独立的备份存在。
4. 作用:保存策略一个优势在于可以删除过期数据,比如使用influx来存日志,只希望查看最近一个月的数据,这时候指定一个duration时间为30天的保存策略,然后添加数据时,指定这个保存策略,就不需要自己来关心日志删除的问题了。