一、创建测试表
1.创建唯一索引"b"
CREATE TABLE `test2` ( `id` int(10) NOT NULL AUTO_INCREMENT, `a` varchar(5) DEFAULT NULL, `b` varchar(5) DEFAULT NULL, `c` varchar(5) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_b` (`b`) ) ENGINE=InnoDB AUTO_INCREMENT=74 DEFAULT CHARSET=utf
2.插入3条数据
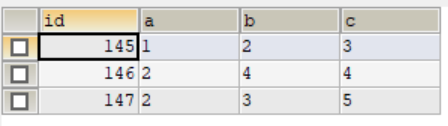
INSERT INTO test1(a,b,c) VALUE (1,2,3),(2,4,4),(2,3,5);
select * from tset2;
二、replace into用法
1.使用replace into插入单条数据
REPLACE INTO test2(b,c) VALUE (3,3);
2 row(s) affected
Execution Time : 00:00:00:047
Transfer Time : 00:00:00:000
Total Time : 00:00:00:047
INSERT INTO test2(a,b,c) VALUE (1,2,3),(2,4,4),(2,3,5);

1.当插入的值和唯一索引重复时,执行更新操作,相当于执行:
delete from where b=3; inset into test2(b,2) value(3,3);
先删除该记录,再插入指定列,没有指定值的为默认值
注意该数据的id加1了,数据替换之后id加1了,此处有坑,如果此id是其他的表的外键,关联关系就对不上了。
2.当插入的值和唯一索引不重复时,执行插入操作,相当于执行:
inset into test2(b,2) value(3,3);
2.使用replace into批量插入数据
INSERT INTO test2(a,b,c) VALUE (1,2,3),(2,4,4),(2,3,5);
三、DUPLICATE KEY UPDATE用法
1.插入重复单条数据
1.当唯一index重复时,直接更新update 后面的字段
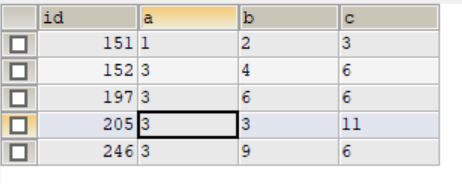
INSERT INTO test2(a,b,c) VALUE (3,3,11) ON DUPLICATE KEY UPDATE a=VALUES(a),c=VALUES(c);
2 row(s) affected
Execution Time : 00:00:01:250
Transfer Time : 00:00:00:000
Total Time : 00:00:01:250
INSERT INTO test2(a,b,c) VALUE (1,3,13) ON DUPLICATE KEY UPDATE c=VALUES(c);
2 row(s) affected
Execution Time : 00:00:00:062
Transfer Time : 00:00:00:000
Total Time : 00:00:00:062

两条sql的区别在于后条语句更新了两个值,而前一条更新了一个值
更新指定值需要在update后面指定。
两条sql分别相当于执行了:
update test2 set a=3,c=13 where b=3; update test2 set c=13 where b=3;
2.插入不重复的值
INSERT INTO test2(a,b,c) VALUE (1,5,13) ON DUPLICATE KEY UPDATE c=VALUES(c);
1 row(s) affected
Execution Time : 00:00:00:031
Transfer Time : 00:00:00:000
Total Time : 00:00:00:031
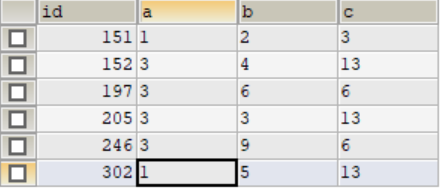
三个值全部插入了,相当于执行了:
insert into test(a,b,c) value (,5,13)
id已经不连续了,说明每次unique index重复时,该表的id也会自增
2.批量插入用法
INSERT INTO test2(a,b,c) VALUE (1,5,14),(1,6,13),(1,7,13) ON DUPLICATE KEY UPDATE a=VALUES(a),c=VALUES(c);
四、两者之间的区别
1.unique index重复插入时
a.单条数据受影响的行都是2;
b.replace 之后原来的数据更新之后会id+1,指定的值会更新,没有指定的,会更新为默认值;
c.uplicate key只会更新指定的值,没有指定的值跟原数据保持一致;
2.unique index不重复时
a.都相当于插入了新记录。