MNIST(Modified National Institute of Standards and Technology)
MNIST被称作是计算机视觉的新手村,相当于神经网络CNN版的helloword,也是TensorFlow的初体验。提供的数据集是28*28的灰度矩阵,要分析并识别出对应原来手写图片的数字。
载入数据集
train = pd.read_csv('./input/train.csv')
test = pd.read_csv('./input/test.csv')
训练集数字总览
# 数字出现总数求和,柱状图
g = sns.countplot(Y_train)
plt.show()
 各个数字出现的总数大致相等,没有极端情况
####原始数据处理
因为训练集是28*28的灰度矩阵,取值范围是0-255的整数,数字越大对应的像素点越暗,因此/255转化成float
```python
X_train = X_train / 255.0
test = test / 255.0
各个数字出现的总数大致相等,没有极端情况
####原始数据处理
因为训练集是28*28的灰度矩阵,取值范围是0-255的整数,数字越大对应的像素点越暗,因此/255转化成float
```python
X_train = X_train / 255.0
test = test / 255.0
X_train = X_train.values.reshape(-1, 28, 28, 1)
test = test.values.reshape(-1, 28, 28, 1)
Y_train = to_categorical(Y_train, num_classes=10)
####CNN建模
因为训练集是28*28的灰度矩阵,取值范围是0-255的整数,数字越大对应的像素点越暗,因此/255转化成float
```python
model_begin = datetime.now()
print(str(model_begin) + " model begin")
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same',
activation='relu', input_shape=(28, 28, 1)))
model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same',
activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation="softmax"))
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])
learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc',
patience=3,
verbose=1,
factor=0.5,
min_lr=0.00001)
# epochs=1 ,- 340s - loss: 0.4151 - acc: 0.8693 - val_loss: 0.0748 - val_acc: 0.9779
# epochs=10,- 309s - loss: 0.0633 - acc: 0.9823 - val_loss: 0.0222 - val_acc: 0.9945
epochs = 1
batch_size = 86
datagen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=10,
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=False,
vertical_flip=False)
datagen.fit(X_train)
history = model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size),
epochs=epochs, validation_data=(X_val, Y_val),
verbose=2, steps_per_epoch=X_train.shape[0] // batch_size
, callbacks=[learning_rate_reduction])
训练集误差分析
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.savefig('./output_cnn/matrix.png')
plt.show()
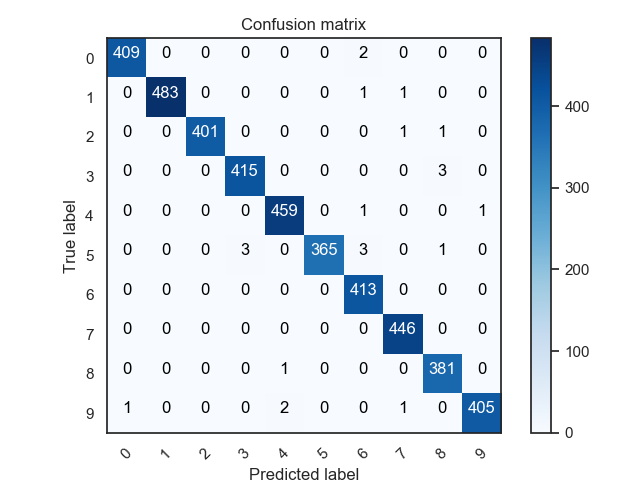 x轴是预测的数字,y轴是真实的数字。可以看出把5预测成6,3预测成8的情况较多,可能是因为这几对数字形状相近,在手写的情况下存在一定的误导
####查看预测错误的数字的真是图片
```python
n = 0
nrows = 3
ncols = 3
fig, ax = plt.subplots(nrows, ncols, sharex=True, sharey=True)
for row in range(nrows):
for col in range(ncols):
error = errors_index[n]
ax[row, col].imshow((img_errors[error]).reshape((28, 28)))
ax[row, col].set_title("Predicted label :{}
True label :{}".format(pred_errors[error], obs_errors[error]))
n += 1
x轴是预测的数字,y轴是真实的数字。可以看出把5预测成6,3预测成8的情况较多,可能是因为这几对数字形状相近,在手写的情况下存在一定的误导
####查看预测错误的数字的真是图片
```python
n = 0
nrows = 3
ncols = 3
fig, ax = plt.subplots(nrows, ncols, sharex=True, sharey=True)
for row in range(nrows):
for col in range(ncols):
error = errors_index[n]
ax[row, col].imshow((img_errors[error]).reshape((28, 28)))
ax[row, col].set_title("Predicted label :{}
True label :{}".format(pred_errors[error], obs_errors[error]))
n += 1
plt.savefig('./output_cnn/errors.png')
plt.show()
<img style="500px;height:350px" src="https://img2018.cnblogs.com/blog/841731/201905/841731-20190519142832900-1437250228.png" align=center />
可以看出部分手写数字比较潦草,人眼看的话,也可能存在错误的情况
####输出预测结果
```python
nresults = model.predict(test)
results = np.argmax(results, axis=1)
results = pd.Series(results, name="Label")
submission = pd.concat([pd.Series(range(1, 28001), name="ImageId"), results], axis=1)
submission.to_csv("./output_cnn/mnist_cnn.csv", index=False)
输出日志
2019-05-12 18:43:05.861004 digit-recongizer begin
2019-05-12 18:43:09.434510 model begin
Epoch 1/1
2019-05-12 18:43:10.537447: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
- 306s - loss: 0.4166 - acc: 0.8679 - val_loss: 0.0808 - val_acc: 0.9726
2019-05-12 18:48:16.955573 error begin
2019-05-12 18:48:25.481250 matrix begin
2019-05-12 18:48:26.292335 display_errors begin
2019-05-12 18:48:27.402511 predict begin
2019-05-12 18:49:28.578289 digit-recongizer end
上传Kaggle预测结果集

第二次修改epochs = 10
Using TensorFlow backend.
2019-05-19 13:10:45.624923 digit-recongizer begin
2019-05-19 13:10:49.557691 model begin
Epoch 1/10
2019-05-19 13:10:51.337148: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
- 311s - loss: 0.4112 - acc: 0.8695 - val_loss: 0.0765 - val_acc: 0.9771
Epoch 2/10
- 294s - loss: 0.1281 - acc: 0.9622 - val_loss: 0.0400 - val_acc: 0.9860
Epoch 3/10
- 298s - loss: 0.0940 - acc: 0.9717 - val_loss: 0.0367 - val_acc: 0.9895
Epoch 4/10
- 318s - loss: 0.0785 - acc: 0.9765 - val_loss: 0.0317 - val_acc: 0.9895
Epoch 5/10
- 303s - loss: 0.0701 - acc: 0.9798 - val_loss: 0.0384 - val_acc: 0.9888
Epoch 6/10
- 301s - loss: 0.0678 - acc: 0.9799 - val_loss: 0.0315 - val_acc: 0.9910
Epoch 7/10
- 291s - loss: 0.0635 - acc: 0.9811 - val_loss: 0.0342 - val_acc: 0.9898
Epoch 8/10
- 293s - loss: 0.0585 - acc: 0.9830 - val_loss: 0.0312 - val_acc: 0.9921
Epoch 9/10
- 292s - loss: 0.0606 - acc: 0.9829 - val_loss: 0.0202 - val_acc: 0.9943
Epoch 10/10
- 309s - loss: 0.0633 - acc: 0.9823 - val_loss: 0.0222 - val_acc: 0.9945
2019-05-19 14:01:01.464350 error begin
2019-05-19 14:01:09.997218 matrix begin
2019-05-19 14:01:10.969481 display_errors begin
2019-05-19 14:01:13.028658 predict begin
2019-05-19 14:02:23.559788 digit-recongizer end
可以看到随着epochs的增加,准确度在缓慢提升,不过花的时间也是越来越长
查看系统资源

mbp几乎在cpu满负荷的情况下跑了1个小时,epochs每一个轮次大药5分钟,10次接近一小时
上传Kaggle预测结果集

准确率达到了0.992,暂时先这样,后面再看有没有其他的调参优化方法