1、K8S,就是基于容器的集群管理平台,它的全称,是kubernetes。kubernetes 是什么?Kubernetes 这个词来源于希腊语,有主管、舵手、船长的意思,我们从中能听到一丝管理的意味,从图标中也能看出来。一个K8S系统,通常称为一个K8S集群(Cluster)。

这个集群主要包括两个部分:
- 一个Master节点(主节点)
- 一群Node节点(计算节点)
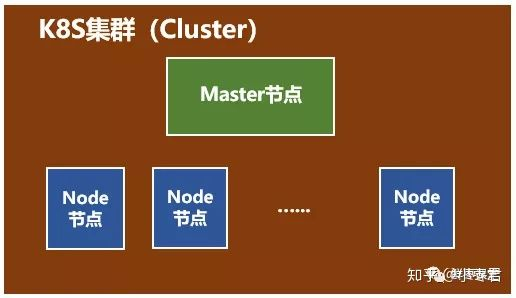
Master节点主要还是负责管理和控制,一般不运行用户的应用。Node节点是工作负载节点,里面是具体的容器,是用户应用运行的地方。
首先是Master节点。

Master 组件提供集群控制功能,对集群作出全局性决策(比如调度),以及检测和响应集群事件。Master 组件有如下几个部分:
Master节点包括API Server、Scheduler、Controller manager、etcd。
- kube-apiserver:对外暴露 API,是前端控制层,其他组件都与它进行通信,也是负责鉴权和授权的守门员角色。
- etcd:是 k8s 的后端存储,所有的集群数据存放在此处。
- kube-controller-manager:处理集群中常规任务的后台线程,包括节点控制器(负责节点移除响应)、副本控制器(维护正确数量的 Pod)、端点控制器、和服务账号和令牌控制器
- cloud-controller-manager:用于与底层云提供商交互的控制器。
- kube-scheduler:监视没有分配节点的新创建的 Pod,选择一个节点供他们运行。
- Additional Services:一些额外的插件,包括DNS、用户界面、容器资源监控、集群层面日志等
然后是Node节点。
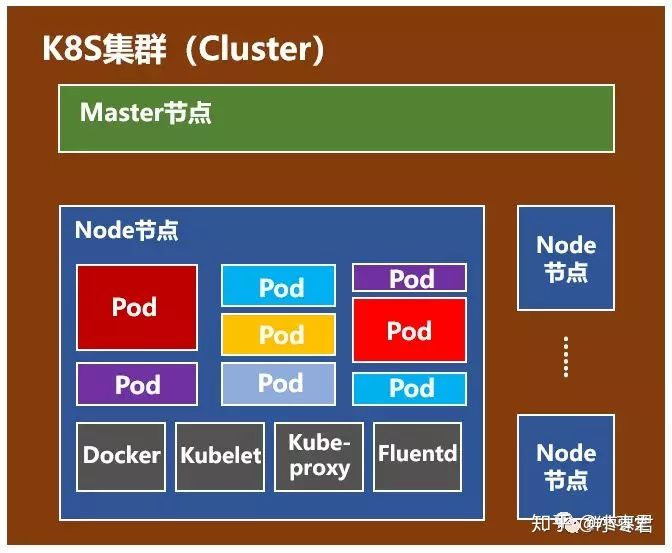
Node 组件在每个Node上运行,Node 是工作容器的运行节点,维护运行时的 Pod 并提供运行时的环境。Node 组件有如下几个部分:Docker、kubelet、kube-proxy、Fluentd、kube-dns(可选),还有就是Pod。
- kubelet:是主要的节点代理,管理其 host 上 Pod 的生命周期。
- kube-proxy:管理节点上的网络规则并执行连接转发。
- Container Runtime:提取容器运行的服务,包括 docker、rkt 等
- supervisord:来提供进程监控,保证kubelet 和 docker 运行
- fluentd:守护进程,有助于提供集群日志
Pod是Kubernetes最基本的操作单元。一个Pod代表着集群中运行的一个进程,它内部封装了一个或多个紧密相关的容器。除了Pod之外,K8S还有一个Service的概念,一个Service可以看作一组提供相同服务的Pod的对外访问接口。
2、在 kubernetes 的网站上,描述 kubernetes 是:
生产级别的容器编排系统
从这个定义我们可以提炼出三个关键字:
- 生产级别
- 容器
- 编排系统
容器的编排系统需要能够管理和组织在一个集群上的运行的宿主机和容器,需要能完成如下任务:
- 管理网络和访问
- 跟踪容器的状态
- 增大或缩小服务的规模
- 实现负载平衡
- 宿主机无响应后实现容器的重新分配
- 服务发现
- 管理容器的存储
- 等等…
3、k8s 与 大数据
我们看到很多企业的业务应用都已经部署到了 k8s 的集群之上,尤其是一些无状态的 Web 服务和 API 服务,特别适合 k8s 的场景。但是以 Hadoop 为代表的大数据系统能够运行在 k8s 之上吗?
如果将 Hadoop 部署在 k8s 之上,会带来哪些好处呢:
- 更好的资源利用:现在使用k8s的在线业务集群与离线大数据集群一般不在一起,而 Hadoop 部署在 k8s 之上就可以共用一套集群,更好的利用业务白天高峰和数据夜里高峰的特点
- 按需获取资源:就像 AWS 的 EMR,可以根据需要获取任意规模和任意时长的 Hadoop 集群,按需付费
- 更好的运维与升级:可以利用 k8s 的工具对 Hadoop 集群进行运维,不用再建设 Hadoop 运维工具
- 更灵活的资源隔离:使用 k8s 实现多个集群的部署,集群间互不影响
但是也存在一些挑战:
- IO性能:首当其冲的就是 IO,大数据系统是一类重 IO 操作的应用,容器化后需要将存储从本地 IO 变为网络 IO,这必然会引起性能的下
- 数据本地化:变为网络 IO 后,数据本地化的特点将不能利用
- 安全:因为不同容器共享一个内核,会有一定的安全隐患
参考链接:https://blog.didiyun.com/index.php/2019/12/11/kubernetes-%E6%98%AF%E4%BB%80%E4%B9%88/