在Spark中,job与被组织在DAG中的一组RDD依赖性密切相关,类似下图:
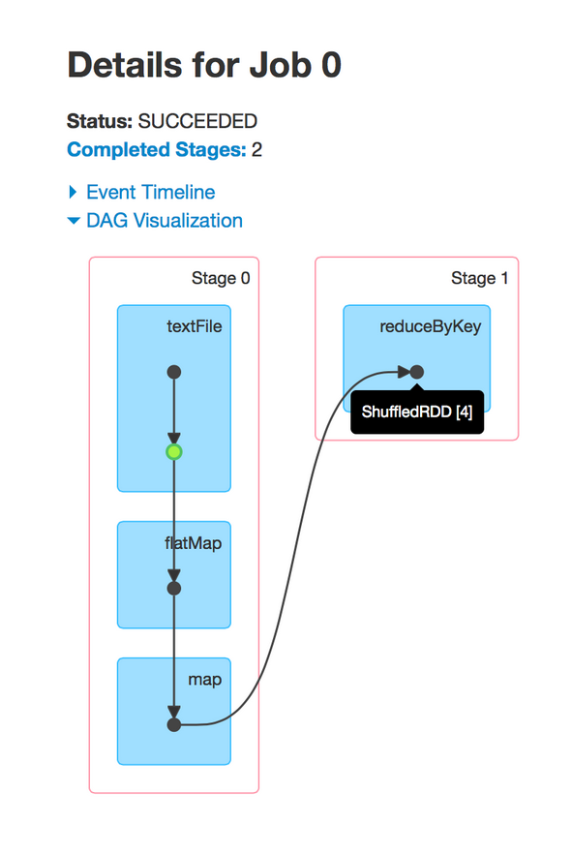
这个job执行一个简单的word cout。首先,它执行一个textFile从HDFS中读取输入文件,然后进行一个flatMap操作把每一行分割成word,接下来进行一个map操作,以形成form(word,1)对,最后进行一个reduceByKey操作总结每个word的数值。
可视化的蓝色阴影框对应到Spark操作,即用户调用的代码。每个框中的点代表对应操作下创建的RDDs。操作本身由每个流入的stages划分。
通过可视化我们可以发现很多有价值的地方。首先,根据显示我们可以看出Spark对流水线操作的优化——它们不会被分割。尤其是,从HDF S读取输入分区后,每个executor随后即对相同任务上的partion做flatMap和map,从而避免与下一个stage产生关联。
其次,RDDs在第一个stage中会进行缓存(用绿色突出表示),从而避免对HDFS(磁盘)相关读取工作。在这里,通过缓存和最小化文件读取可以获得更高的性能。