PageRank让链接来"投票" 。
一个页面的“得票数”由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(“链入页面”)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
一个页面的PageRank是由其他页面的PageRank计算得到。Google不断的重复计算每个页面的PageRank。如果给每个页面一个随机PageRank值(非0),那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。这就是搜索引擎使用它的原因。
对于某个互联网网页A来讲,该网页PageRank的计算基于如下两个基本假设:
-
数量假设:在Web图模型中,若是一个页面节点接收到的其余网页指向的入链数量越多,那么这个页面越重要。
-
质量假设:指向页面A的入链质量不一样,质量高的页面会经过连接向其余页面传递更多的权重。因此越是质量高的页面指向页面A,则页面A越重要。
为了防止迭代中一部分页面的PR值由于没有被投票而变为0,无法再继续为其他页面产生贡献值了。故pagerank为一个页面的PR值计算添加了一个最小值。

这里的d是一个手动选择的参数,在原版论文中,最小值是1-d,而不是(1-d)/N,这里将d选择为了0.85,即最小值设为0.15
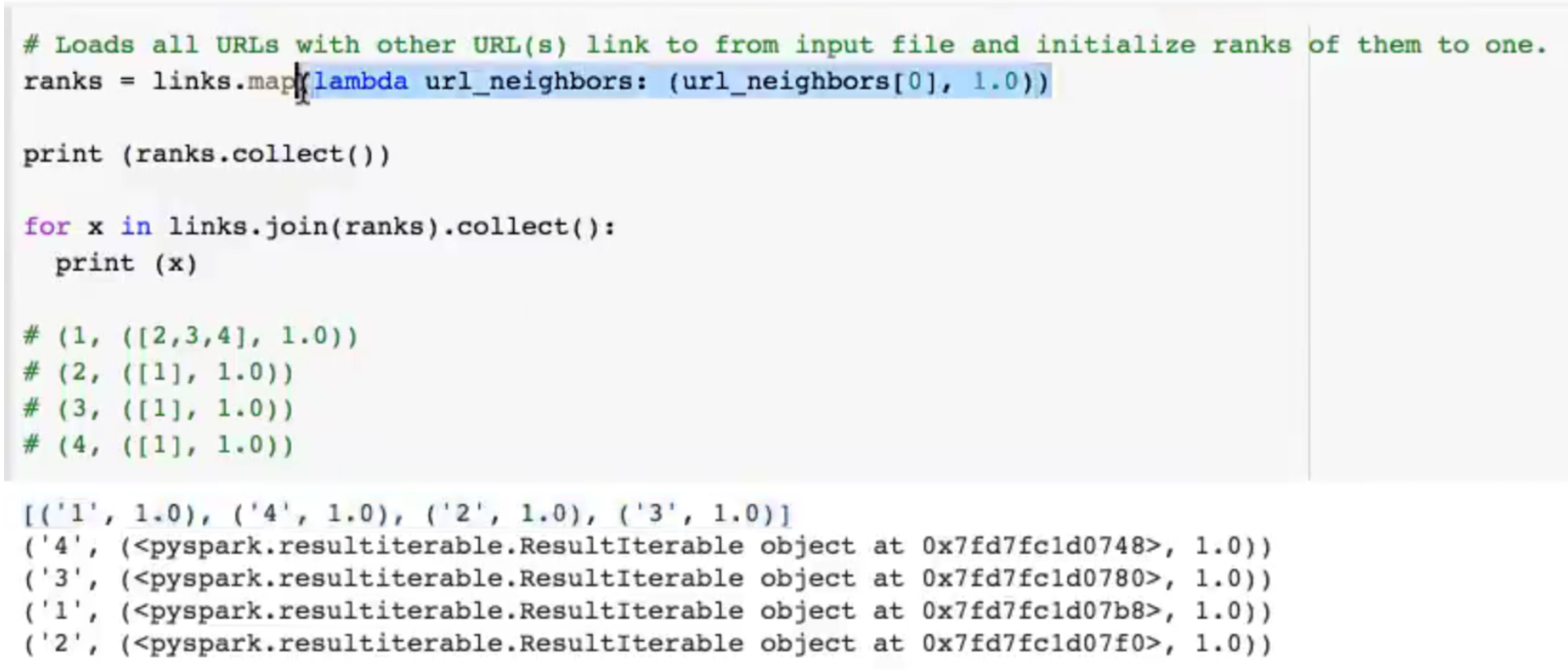
这个算法维护两个RDD,一个的键值对是(pageID, linkList),包含了每个页面的出链指向的相邻页面列表(由pageID组成);另一个的键值对是(pageID, rank),包含了每个页面的当前权重值。算法流程如下:
-
将每个页面的权重值初始化为1.0;
-
在每次迭代中,对页面p,向其每个出链指向的页面加上一个rank(p)/neighborsSize(p)的贡献值contributionReceived;
-
将每个页面的权重值设置为:0.15 + 0.85 *contributionReceived。
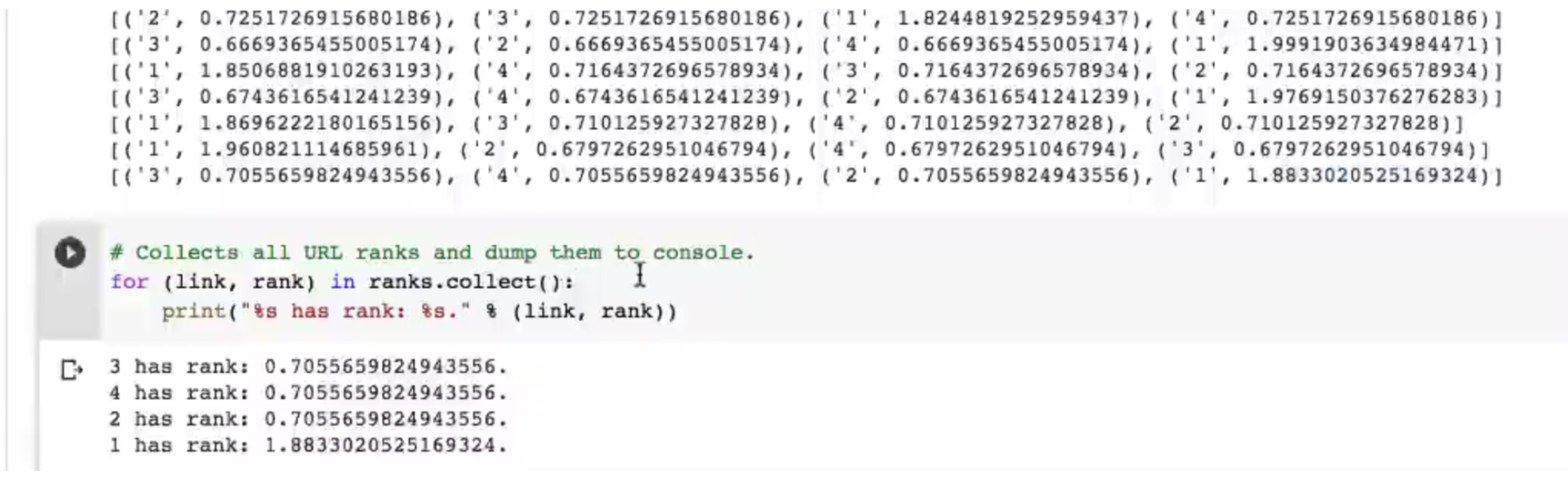
不断迭代步骤2和3,过程中算法会逐渐收敛于每个页面的实际PageRank值,实际运行之时大概迭代10+次以上即可。




scala版本:
package sparkMLib
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* Computes the PageRank of URLs from an input file. Input file should
* be in format of:
* URL neighborURL
* URL neighborURL
* URL neighborURL
* ...
* where URL and their neighbors are separated by space(s).
*/
object PageRank {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("PageRank")
val sc = new SparkContext(conf)
/***
* 假设相邻页面列表以Spark objectFile的形式存储,将读取的linksRDD进行哈希分区
* 分区有利于后续的join等操作,然后persist进行持久化
* 这里的K:V为:当前页面:当前页面的出链集合;
* 而相对于出链集合当中的每一个元素,当前页面则是其入链。
* 设置哈希分区为10;
* 这里假设links RDD是一个很大的静态数据集,
* 并且在每次迭代中都会和ranks发生连接操作,会通过网络进行数据混洗,开销很大,
* 所以我们通过预先进行分区来减小网络开销;
*
* 出于同样的原因,我们调用links的persist()方法,将它保留在内存中以供每次迭代时用。
*/
val links = sc.objectFile[(String,Seq[String])]("hdfs://8.129.26.6:9000/web-Google.txt").partitionBy(new HashPartitioner(100)).persist(StorageLevel.MEMORY_ONLY)
//将每个页面的排序值初始化为1.0;由于使用mapValues,生成的 RDD的分区方式会和"links"的一样
//ranks:(1,1.0) (2,1.0)
var ranks = links.mapValues(v => 1.0)
//进行10轮PageRank迭代
/**
* 此循环迭代的涵义是:
* 1、links.join(ranks):连接两个RDD,结果类型为:Array[(String, (List[String], Double))],
* 2、case(...)中links.map(dest => (dest, rank / links.size)):
* 算出当前页面(pageId)对其出链集合(links)中的每一个出链(link)排序的贡献(rank / links.size);
* 此时,contributions的值为:当前页面每一个出链的页面ID和其排序值(RDD[(String, Double)])
* 3、然后再把contributions按照页面ID(根据获得共享的页面)分别累加起来,
* 把该页面的排序值(ranks)设为 0.15*1+ 0.85*contributionReceived,
* 其中,0.85为查看当前页面的概率,0.15为直接从浏览器地址栏跳转的概率。
*/
for(i <- 0 until 10){
//(1,((2,3,4,5),1.0))
val contributions = links.join(ranks).flatMap{
case (pageId,(links,rank)) =>
links.map(dest => (dest,rank / links.size))
}
ranks = contributions.reduceByKey((x,y) => x+y).mapValues(v => 0.15 +0.85*v)
}
//写出最终排名
ranks.saveAsTextFile("rank")
}
}